



总览
这是 RMIT 大学、新南威尔士大学和莫纳什大学联合发表的论文。这篇论文提出了一种新的数据选择方法 SCAR(Style Consistency-Aware Response Ranking),旨在通过选择具有风格一致性的高质量训练数据来提高大语言模型指令微调的效率。
当前大语言模型的指令微调通常需要大量的训练数据,但这些数据往往存在风格不一致的问题,导致训练效率低下。如果全量数据中回答的风格不一致,SCAR 通过识别和选择风格一致的指令-回答对,能够在显著减少训练数据量的同时,达到甚至超越全量数据训练的效果。
实验结果表明,使用 SCAR 选择的数据进行微调,最好情况下仅用 0.7% 的原始数据就能匹配或超越使用全量数据训练的模型性能。
在代码生成任务上,使用 SCAR 选择的风格一致数据训练的 LLM 在 HumanEval 基准上取得了显著的性能提升,远超使用风格不一致数据训练的模型。在开放域问答任务中,仅使用 25% 的精选数据就能超越全量风格不一致数据的训练效果。

▲ 图1:不同回答类型在风格一致性维度的对比分析。左图展示了不同类型回答在 Linguistic Form 特征空间中的分布,右图为 Instructional Surprisal 的密度分布。Direct 表示由 GPT-3.5-Turbo 直接生成的回答,Referenced 表示 GPT-3.5-Turbo 在保留人类回答语义的基础上重新生成的回答。结果显示,直接生成的回答在风格上更加一致。
我们还开发了一个开源工具包,支持研究者便捷地应用 SCAR 方法进行数据选择和模型训练。该工具包提供了完整的数据选择流程,包括风格一致性评估、数据排序和子集选择等功能。

论文标题:
SCAR: Data Selection via Style Consistency-Aware Response Ranking for Efficient Instruction-Tuning of Large Language Models
论文链接:
https://arxiv.org/abs/2406.10882
数据和代码链接:
https://github.com/zhuang-li/SCAR

文章主要贡献
风格一致性理论框架:首次系统性地分析了训练数据中的风格一致性对大语言模型指令微调性能的影响,识别出 Linguistic Form 和 Instructional Surprisal 两个关键风格要素。
SCAR 数据选择方法:提出了一种基于风格一致性感知的数据排序方法,能够自动从大规模数据集中选择高质量、风格一致的训练样本。该方法在代码生成和开放域问答两个领域都取得了显著效果提升。
极致的数据效率: 实验证明,使用 SCAR 选择的数据进行训练,可以在仅使用 0.7%-25% 原始数据的情况下,达到或超越全量数据训练的性能。在某些情况下,精选的小数据集训练出的模型甚至比全量数据训练的模型表现更好。
跨域泛化能力:SCAR 方法展现出良好的跨域泛化能力,在代码域训练的排序器可以有效选择开放域的数据,为实际应用提供了灵活性。

问题描述
当前大语言模型指令微调面临的主要挑战是数据质量和一致性问题:
风格不一致性:现有的指令微调数据集通常由多个来源组合而成,包括人工标注数据和不同模型生成的合成数据。这些数据在语言形式、回答风格等方面存在显著差异,导致模型训练效率低下。
数据质量参差不齐:大规模数据集中往往包含大量低质量样本,这些样本不仅不能提升模型性能,反而可能引入噪声,影响模型的最终效果。训练成本高昂:使用全量数据进行训练需要大量的计算资源和时间成本,特别是对于个人研究者和小型团队来说,这种成本往往难以承受。
缺乏有效的数据选择策略:现有的数据选择方法大多基于简单的启发式规则或单一指标,缺乏对数据内在风格特征的深入理解,难以选出真正有价值的训练样本。
这些问题导致大语言模型的指令微调效率低下,训练成本居高不下,限制了该技术的普及和应用。

方法
风格要素识别:
-
Linguistic Form:包括句子结构、标点符号使用、布局特征(如项目符号、标题)等表面语言特征
-
Instructional Surprisal:衡量回答相对于给定指令的可预测性,通过困惑度和语义相关性进行量化
我们发现在如果数据的质量在用一等级,但是数据中回答的两种风格元素一致性更高的话,这个数据用来微调大模型会得到更好地效果。同时我们发现大语言模型生成的数据往往在风格上更一致,导致大语言模型生成的数据在质量跟人工数据相差无极的情况下能微调更好地模型。
基于这个发现,我们构造训练数据,包含人工回答,人工-大模型协同生成的回答,纯大模型生成的回答,训练了一个排序器给予跟语言模型回答相似的数据更高的分数。
SCAR 排序器架构:
使用神经网络构建排序函数,该函数能够为指令-回答对分配风格一致性分数。排序器通过以下组件实现:
-
风格特征的学习模块,从回答中抽取两个风格要素的特征 Linguistic Form 和 Instructional Surprisal
-
质量约束机制,确保选择的数据既具有风格一致性又保持高质量
-
三元组损失训练,优化风格特征的学习效果
数据选择流程:
1. 训练 SCAR 排序器学习风格一致性模式
2. 对目标数据集进行排序和筛选
3. 选择得分最高的 k% 样本用于模型微调
方法
风格要素识别
我们关注的两个关键风格要素是:
-
Linguistic Form(语言形式):包括句子结构、标点符号使用、格式布局(如项目符号、标题)等语言表层特征。
-
Instructional Surprisal(指令意外性):衡量回答在语义和形式上对给定指令的可预测性,综合使用困惑度(perplexity)与语义相关性进行建模。
我们观察到:当训练数据在 helpfulness 和 correctness 等质量指标相当时,回答风格更加一致的数据往往能训练出表现更优的大语言模型(LLM)。进一步地,我们发现大模型生成的数据通常在风格上更加一致,这也是为什么在质量相近的情况下,大模型生成数据反而优于人工数据的原因之一。
基于这一发现,我们构建了包含多种风格来源的训练数据:包括纯人工回答、人工与大模型协同生成的混合数据,以及纯大模型生成的内容。随后,我们训练了一个排序器模型,专注于识别风格一致性的样本,并给予与高质量大模型回答相似的样本更高评分。
SCAR 排序器架构
SCAR 是一个用于风格一致性打分的轻量级排序器,具体包括以下几个组成部分:
-
风格特征提取模块:从回答中学习 Linguistic Form 和 Instructional Surprisal 的特征表示。
-
质量约束机制:通过软性规则或联合建模,确保筛选结果在保持风格一致性的同时也具备基础的回答质量。
-
三元组损失函数训练:使用正负样本对比,强化排序器对风格一致与不一致样本的区分能力。
数据筛选流程
SCAR 的使用流程如下:
1. 利用构造的数据训练排序器,学习风格一致性的表示。
2. 对目标训练集中的所有指令–回答对进行打分排序。
3. 选取得分最高的前 k% 样本作为最终用于微调的训练数据。

实验和评估
我们设计了两个风格不一致的数据场景来验证 SCAR 的有效性:一是包含多个来源的人工标注数据,二是混合了不同 LLM 生成的合成数据。这些场景模拟了实际应用中常见的风格不一致问题。
1. 代码生成任务评估:在 HumanEval 和 MultiPL-E 基准上评估了 CodeLlama-7B 模型。结果显示,使用 SCAR 选择的 25% 数据训练的模型,在平均 Pass@1 指标上超越了使用全量数据训练的模型。具体而言,模型在 Python、Java、JavaScript 和 C++ 四种编程语言上都取得了显著提升。
2. 开放域问答评估:在 AlpacaEval 基准上评估了 Meta-Llama-3-8B 模型。使用 SCAR 选择的 10% 数据就能达到全量数据的性能水平,而在某些配置下,小数据集训练的模型 L.C. WinRate 甚至达到了 6.61,远超全量数据训练的 3.86。
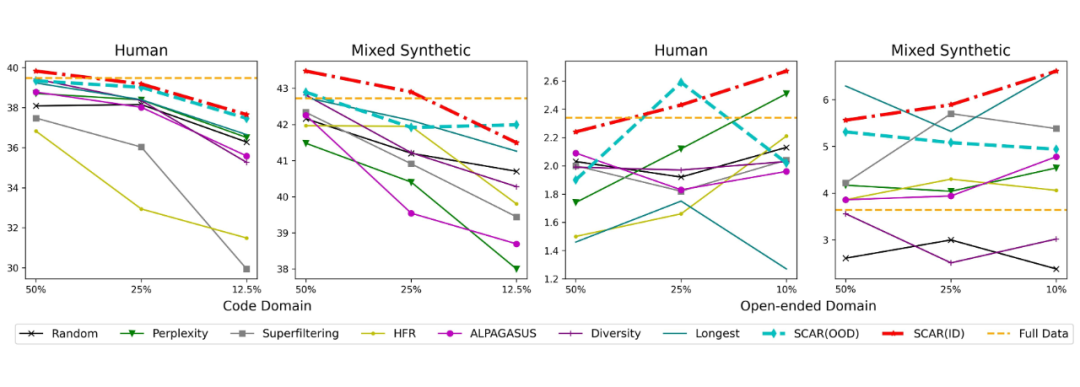
▲ 图2:SCAR 与其他数据选择方法的性能对比。在代码生成和开放域问答任务中,SCAR 始终保持领先优势,特别是在小数据集场景下表现尤为突出。
3. 开源模型验证:在 OLMo-7B 和 StarCoder-15.5B 等开源了全量数据的模型上的实验进一步验证了 SCAR 的有效性。这两个模型所使用的原始数据都有风格不一致的特点。我们用 SCAR 筛选这些开源的全量数据,重新微调基座模型来比对全量数据和子集数据对大模型微调的影响。
特别是在 OLMo-7B 的实验中,使用仅 0.7% 原始数据的 SCAR 筛选的子集在部分基准测试上超过了官方全量训练模型的表现;而在 StarCoder-15.5B 上,SCAR筛选的数据子集在 HumanEval 和 MultiPL-E 等基准上的平均表现提升了2–4个百分点。
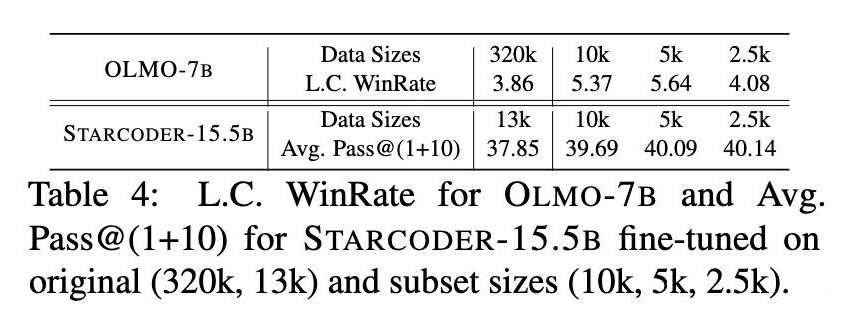
▲ 表1:开源模型验证结果。SCAR 选择的小规模数据集训练出的模型超越了官方全量数据训练的版本,证明了方法的突破性价值。
4. 风格一致性分析:通过多种指标分析验证了 SCAR 选择数据的风格一致性。结果表明,选择的数据的回答在 TTR、MTLD 和困惑度等指标的标准差显著降低,证明了方法有效的选择了风格一致的回答。
5. 消融实验:为了验证 SCAR 各个组件的重要性,我们进行了详细的消融实验。结果表明,风格表示学习、质量约束和参考回答等组件都对最终性能有重要贡献。

结论
SCAR 方法在大语言模型指令微调领域取得了重要突破。通过引入风格一致性的概念和相应的数据选择技术,该方法显著提升了训练效率,在大幅减少数据需求的同时提升了模型性能。
实验结果证明,精心选择的小规模的风格一致的数据集往往比大规模但风格参差不齐的数据集更有效。这一发现对于资源受限的研究环境和实际应用场景具有重要意义,为大语言模型的经济高效训练提供了新的路径。
SCAR 方法的跨域泛化能力和工具包的开源发布,为研究社区提供了实用的数据选择解决方案,有望推动大语言模型训练技术的进一步发展和普及。
(文:PaperWeekly)