智东西2月26日报道,刚刚,DeepSeek开源周第三弹发布——DeepGEMM,一个支持密集和MoE GEMM的FP8 GEMM库,为V3/R1训练和推理提供动力。

GitHub:
https://github.com/deepseek-ai/DeepGEMM
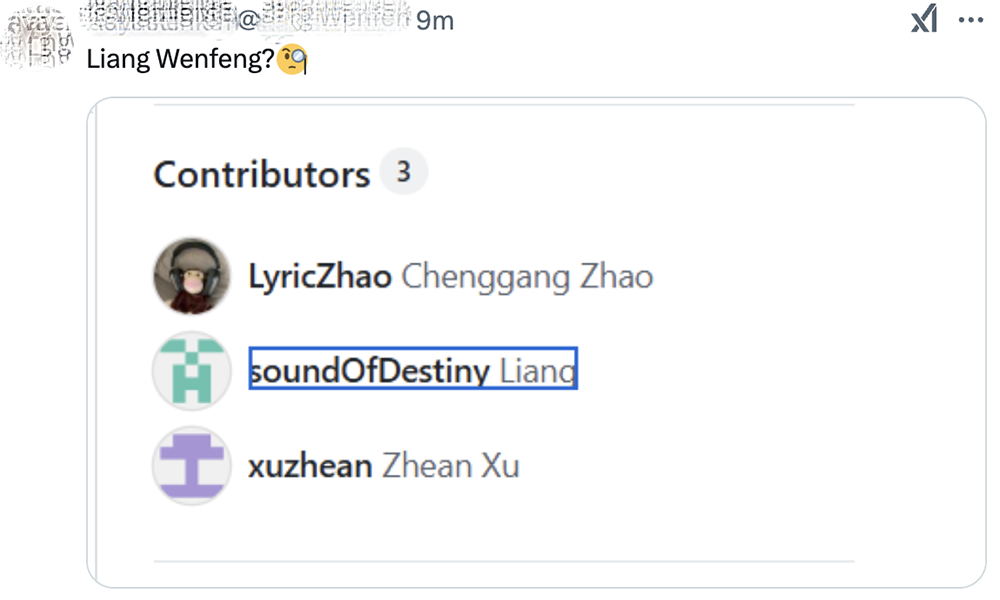
眼尖的网友已经在项目贡献者名单中捕捉到了一个“Liang”,并在DeepSeek推文评论区发问:“是梁文锋(DeepSeek创始人)吗?”
DeepGEMM是一个专为干净、高效的FP8通用矩阵乘法(GEMM)而设计的库,具有细粒度扩展功能,如DeepSeek-V3中所述。它支持普通和混合专家(MoE)分组GEMM。该库用CUDA编写,在安装过程中无需编译,而是使用轻量级即时(JIT)模块在运行时编译所有kernel。
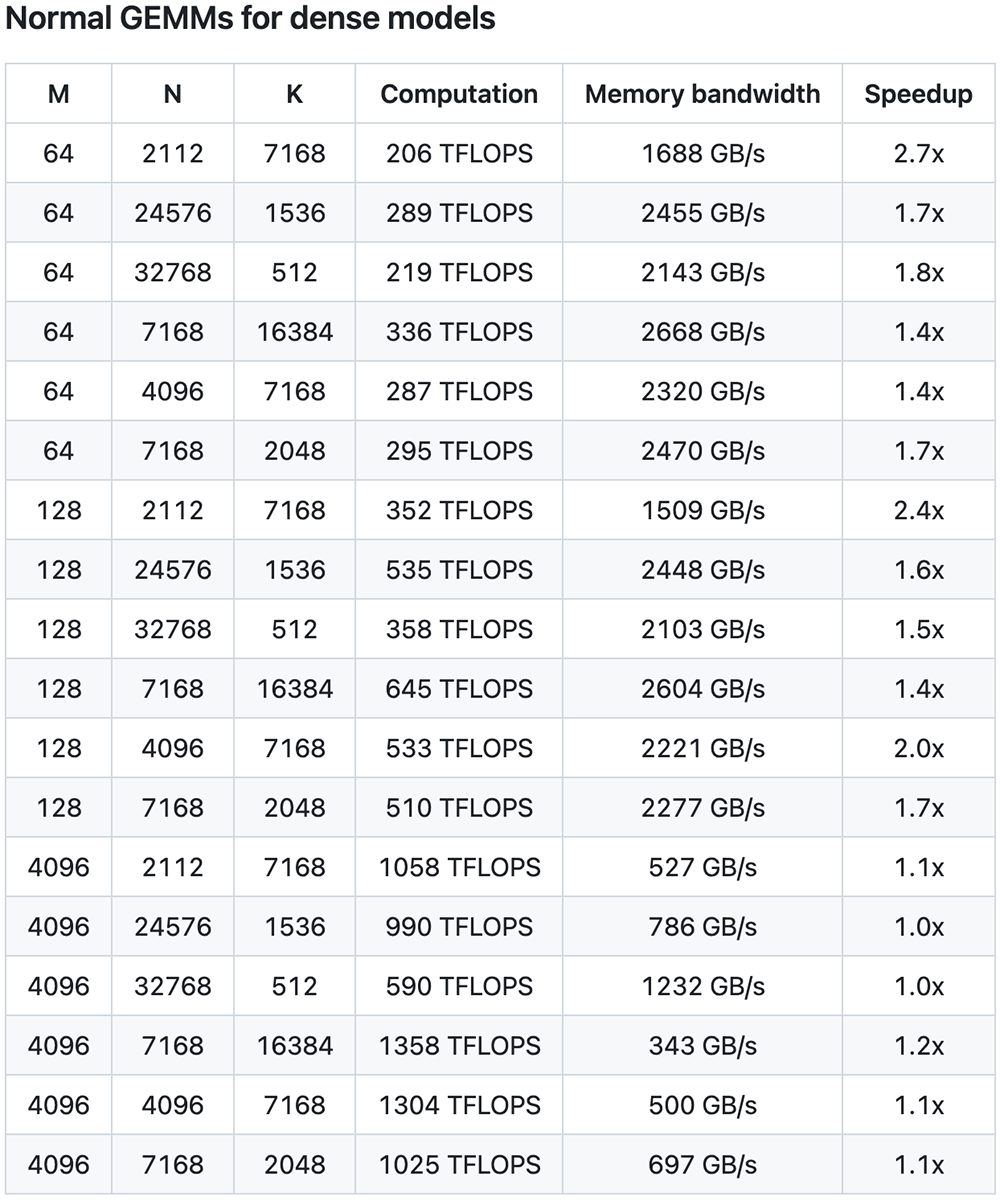
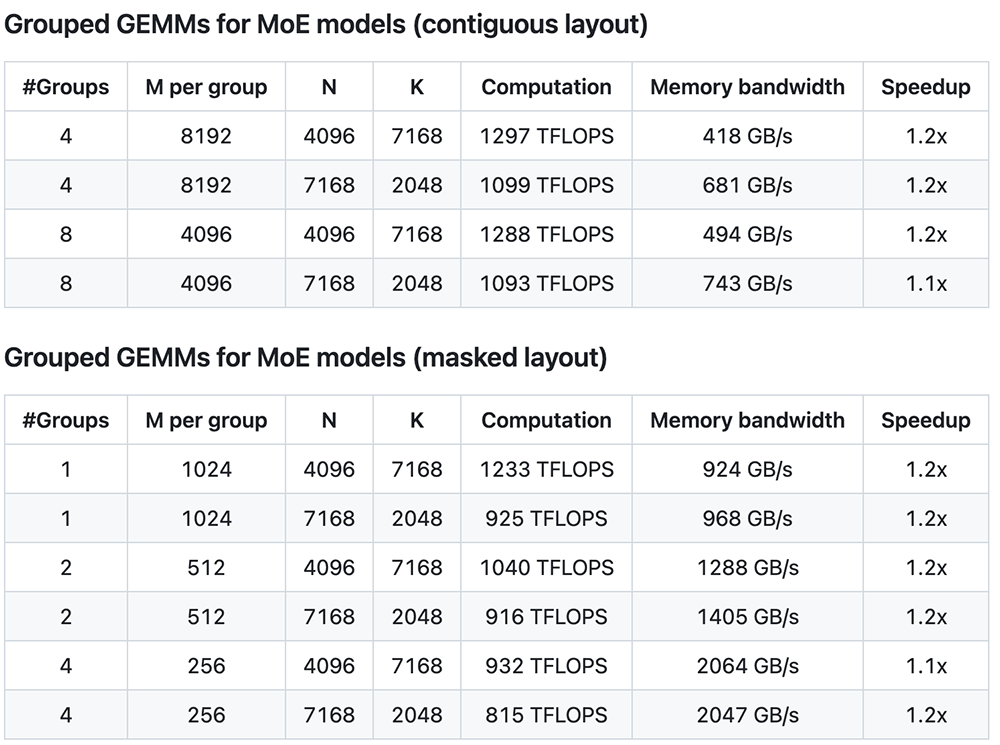
根据DeepSeek晒出的数据,普通GEMM(密集模型)中矩阵运算可提速多达2.7倍,分组GEMM(MoE模型)中连续性布局、掩码布局下可提速多达1.2倍。
目前,DeepGEMM仅支持英伟达Hopper Tensor Core。为了解决不精确的FP8 Tensor Core累积问题,它采用了CUDA核心两级累积(提升)。
虽然它利用了CUTLASS和CuTe的一些概念,但它避免了对其模板或代数的过度依赖。相反,该库的设计非常简单,只有一个核心kernel函数,包含大约300行代码。这使其成为学习Hopper FP8矩阵乘法和优化技术的干净且易于访问的资源。
尽管DeepGEMM设计轻量,但其性能却与各种矩阵形状的专家调整库相当或超过后者。
DeepSeek在搭载NVCC 12.8的H800上测试了DeepSeek-V3/R1推理中可能使用的所有形状(包括预填充和解码,但没有张量并行性)。所有加速指标都是与其基于CUTLASS 3.6的内部精心优化的实现进行比较计算的。
DeepGEMM在有些形状上的表现并不是很好,因此DeepSeek欢迎开发者来优化PR。在普通GEMM(密集模型)中,矩阵运算最高提速达到2.7倍。
在分组GEMM(MoE模型)中,连续性布局、掩码布局下速度可提升1.1倍~1.2倍。
DeepGEMM一发布,DeepSeek的推文评论区好评如潮。有人为英伟达股票发愁:

有人热情夸赞新代码库和DeepSeek工程师:
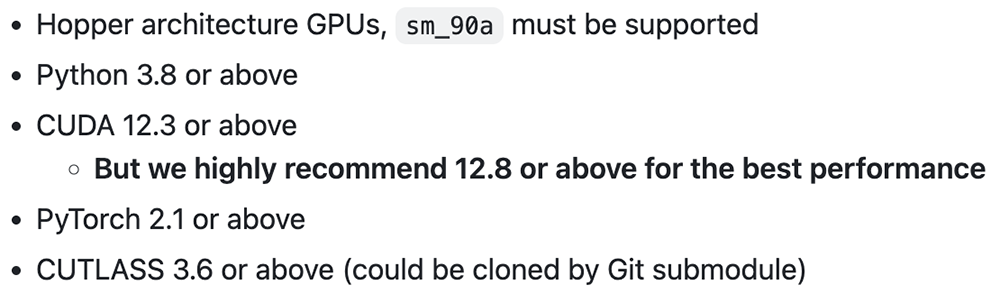
DeepSeek分享了清晰的上手指南,需要Hopper架构GPU、必须支持sm_90a,要求是Python 3.8、CUDA 12.3、PyTorch 2.1、CUTLASS 3.6或更新版本。DeepSeek强烈推荐CUDA 12.8或更高的版本以获得最佳性能。
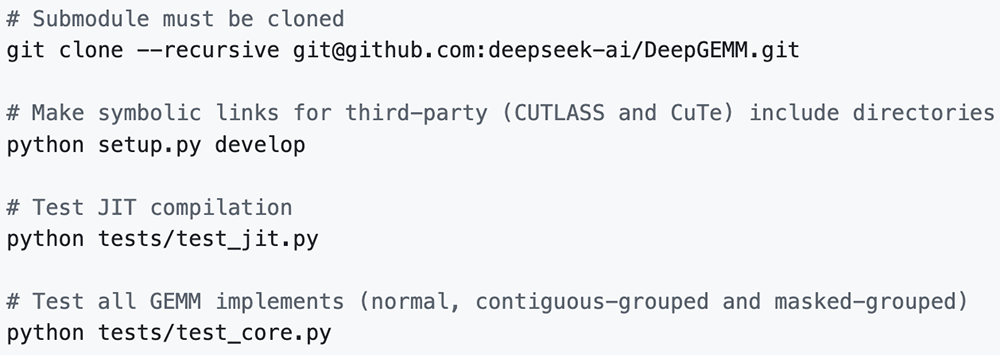

将deep_gemm导入Python项目,就可以开始享用了。
这个代码库仅包含GEMM kernel。它要求LHS扩展因子进行TMA对齐和转置,并且仅支持NT格式(非转置LHS和转置RHS)。对于转置或其他FP8转换操作,需单独实现或将它们融合到先前的kernel中。虽然该库提供了一些简单的PyTorch实用函数,但这些函数可能会导致性能下降。DeepSeek的主要重点是优化GEMM kernels本身。
除了kernel外,该代码库还提供了一些实用函数和环境变量。
DeepSeek用🐳表示CUTLASS中排除的技术。按照CUTLASS设计,DeepGEMM中的内核经过了warp专门化,可实现重叠数据移动、张量核心MMA指令和CUDA核心提升。下图是说明此过程的简化图:
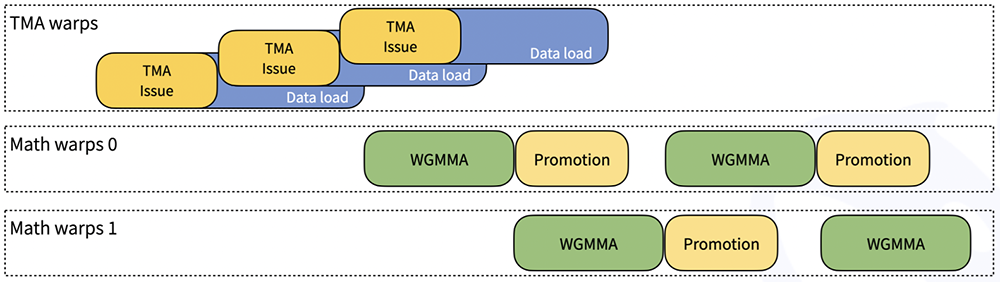
张量内存加速器(TMA)是Hopper架构引入的一项新硬件功能,旨在实现更快、异步的数据移动。具体来说,DeepSeek利用TMA来实现以下目的:
DeepGEMM采用完全即时编译(JIT)设计,安装时无需编译。所有内核均使用轻量级JIT实现在运行时进行编译。这种方法具有以下几个优点:
总体而言,JIT显著提高了小形状的性能,类似于Triton编译器的方法。
对于某些形状,与2的幂对齐的块大小可能会导致SM未得到充分利用。例如,对于M=256, N=7168,典型的块大小分配会BLOCK_M=128, BLOCK_N=128导致只有(256 / 128) * (7168 / 128) = 112132个SM得到利用。
为了解决这个问题,DeepSeek支持未对齐的块大小(如 112),使(256 / 128) * (7168 / 112) = 128SM能够在这种场景中工作。在细粒度扩展的同时实施此技术需要仔细优化,但最终可以提高性能。
(文:智东西)