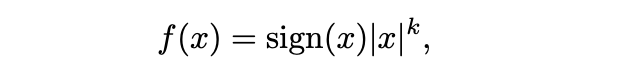©作者 | 席浩诚
近期DeepSeek V3 引爆国内外的社交媒体,他们在训练中成功应用了 FP8 精度,显著降低了 GPU 内存使用和计算开销。这表明,FP8 量化技术在优化大型模型训练方面正发挥着越来越重要的作用。
近期,来自伯克利,英伟达,MIT 和清华的研究者们提出了显存高效的 FP8 训练方法:COAT(Compressing Optimizer states and Activation for Memory-Efficient FP8 Training),致力于通过 FP8 量化来压缩优化器状态和激活值,从而提高内存利用率和训练速度。
COAT 实现了端到端内存占用减少 1.54 倍,端到端训练速度提高 1.43 倍,同时保持模型精度。它还可以使训练批次大小加倍,从而更好地利用 GPU 资源。
通过利用 FP8 精度,COAT 使大型模型的高效全参数训练在更少的 GPU 上成为可能,并有助于在分布式训练环境中加倍批次大小,为大规模模型训练的扩展提供了实用的解决方案。最重要的是,他们的训练代码完全开源。
论文第一作者席浩诚本科毕业于清华大学姚班,目前在伯克利攻读博士学位,他在英伟达实习期间完成了这篇工作。论文共同通讯作者为 MIT 韩松副教授和清华大学陈键飞副教授。
论文题目:
COAT: Compressing Optimizer States and Activation for memory efficient FP8 Training
https://arxiv.org/abs/2410.19313
https://github.com/NVlabs/COAT
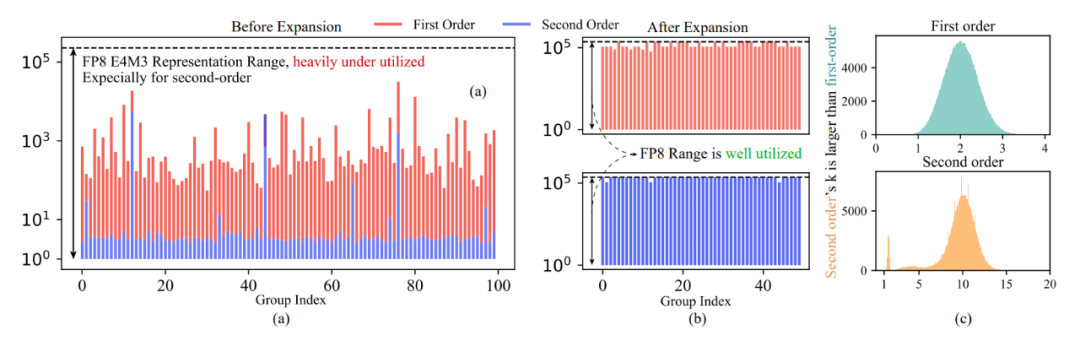
论文作者发现,当前的量化方法无法充分利用 FP8 的表示范围,因此在使用每组量化(per-group quantization)对优化器状态进行量化时会导致较大的量化误差。
对于 FP8 的 E4M3 格式,我们希望量化组 X 的动态范围覆盖 E4M3 的最小可表示值(0.00195)和最大可表示值(448)之间的整个跨度,以充分利用其表示能力。
然而,E4M3 的动态范围通常未被充分利用:E4M3 的动态范围约为 200000,但一阶动量的每个量化组的最大值最小值之比通常为 1000,二阶动量的该比值则通常为 10,远小于 E4M3 的动态范围。这使得用 FP8 来量化优化器状态的误差非常大。
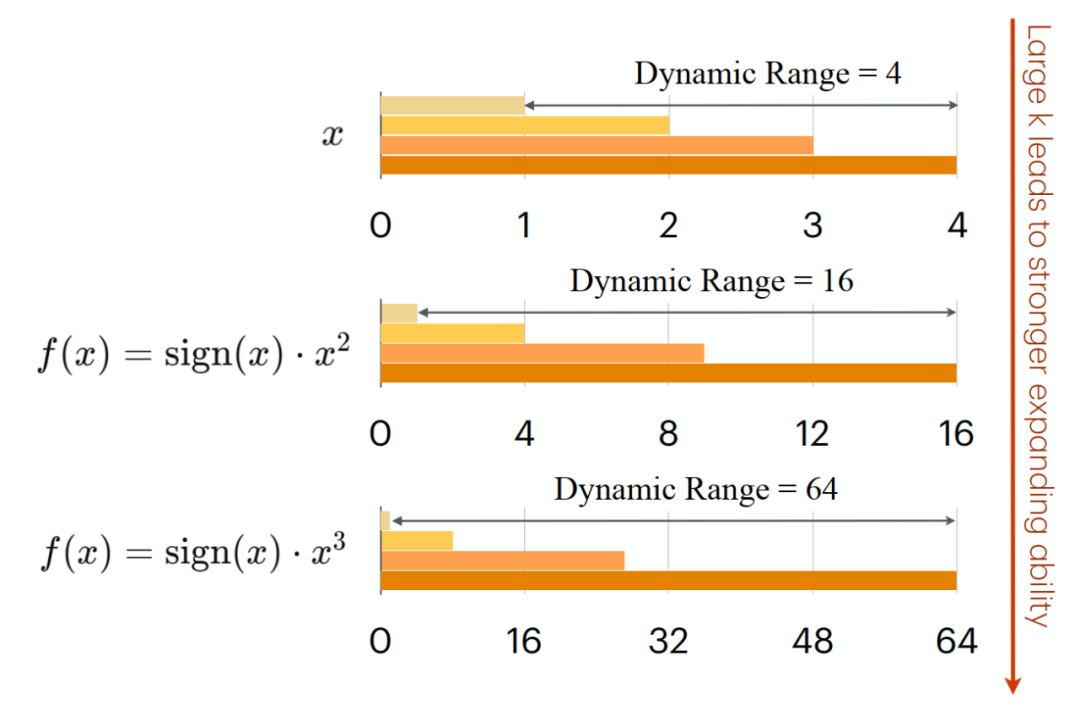
论文作者发现,在量化之前引入一个扩展函数 f (・),能够扩大量化组的动态范围,并使其与 E4M3 对齐。使用的扩展函数为:
其中,k 是即时计算的参数,每个量化组共享一个 k。当 k > 1 时,动态范围将被扩大,并更接近 E4M3 的动态范围。在每一步训练中,都可以即时的计算出最优的 k,从而可以充分利用 E4M3 的表示范围,而原始的量化方法只能利用其中的一小部分。
动态范围扩展方法可以大大减少量化误差,并充分利用 E4M3 的动态范围。除此之外,还发现,E4M3 比 E5M2 更适合一阶动量。
而对于二阶动量,虽然在原始设置中 E4M3 优于 E5M2,但在应用我们的扩展函数后,它们的量化误差几乎相同。因此,建议在量化优化器状态时使用 E4M3 + E4M3 量化策略或 E4M3 + E5M2 量化策略。
FP8激活
动机:非线性层占用大量内存
在语言模型的前向传播中,必须保留激活值以用于反向传播计算梯度。在 Llama 模型系列中,非线性层通常占内存占用的约 50%。相比之下,线性层的贡献不到 25%。因此,优化线性和非线性层以减少激活内存占用至关重要。
FP8 精度流要求所有线性和非线性层的输入和输出采用 FP8 格式。通过直接以 FP8 格式保存输入张量用于反向传播,这消除了额外的量化操作需求,从而减少了相关开销。
FP8 精度流自然地将非线性和线性层的内存占用减少了 50%,因为它们只需要保存 FP8 激活值,而不是 BF16。为了进一步提高该方法的准确性,作者提出在不同层中变化量化粒度,以混合粒度的方式平衡精度和效率。
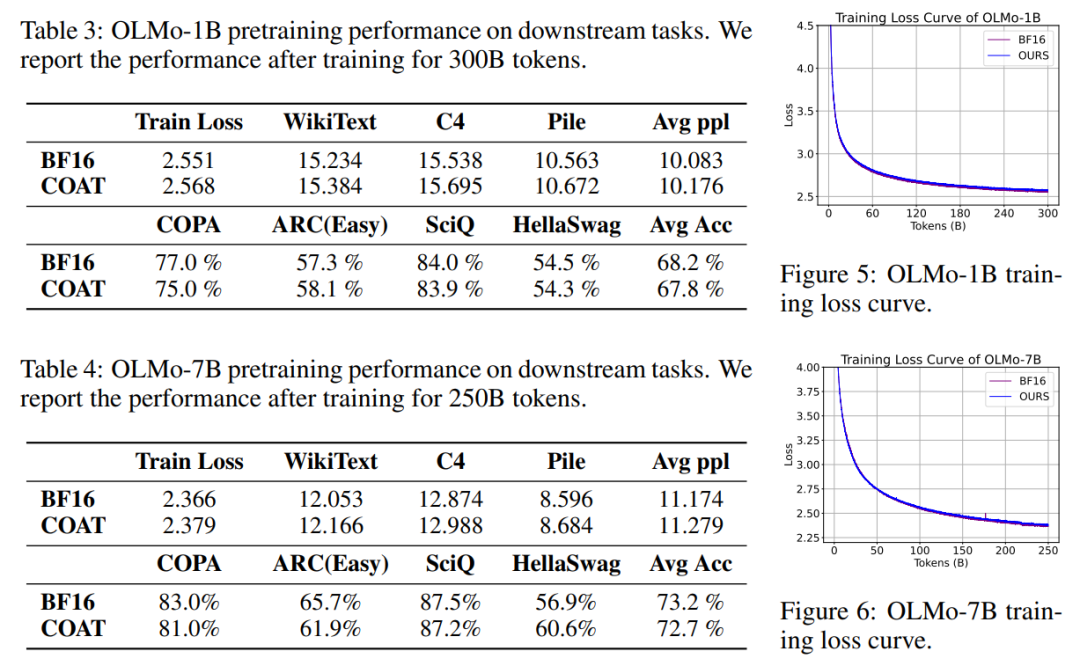
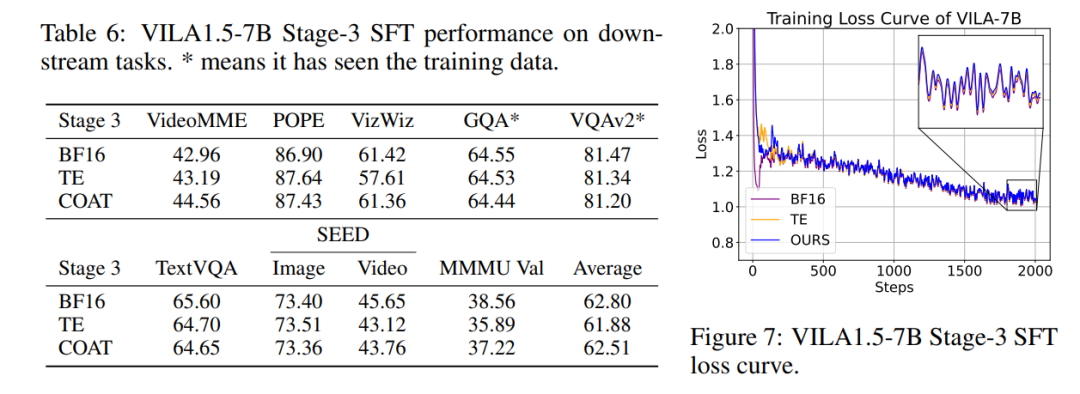
实验结果
COAT 在多个任务中展示了其在内存占用和训练速度方面的优势,同时保持了模型性能。
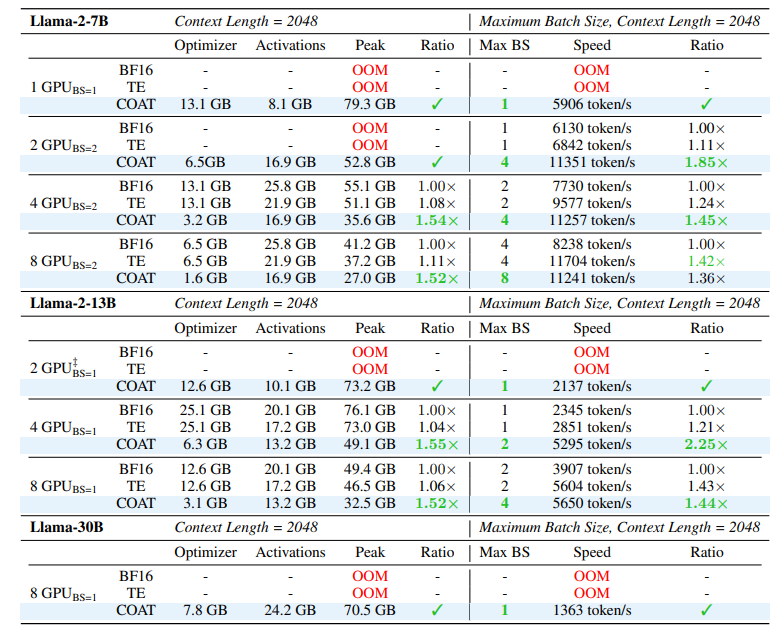
在使用 4 张 H100 训练 Llama-2-13B 模型时,COAT 将每个 GPU 的内存占用从 BF16 的 76.1GB 减少到 49.1GB,实现了 1.54 倍的内存缩减。
同时,COAT 将训练速度从 BF16 的每秒 2345 个 token 提升至每秒 5295 个 token,达到 1.43 倍的加速。在几乎所有的训练场景下,COAT 都能够使 Batch Size 翻倍,或是让训练所需的卡数减小。
COAT 在各种应用场景下,均展现出了出色的精度,完全不会导致模型性能下降。例如,在大语言模型预训练任务中,COAT 可以保持近乎无损的模型性能,训练中的 loss 曲线也和 BF16 完全吻合。
COAT 在视觉语言模型微调中同样实现了和 BF16 训练完全一致的表现。无论是 loss 曲线,还是下游任务上的表现,COAT 均和 BF16 基准相持平。
在一些实际的下游任务例子中,经过 COAT 训练过的模型也有着相当优秀的生成和总结能力。
总结
COAT 的核心价值在于使用 FP8 进行训练的同时做到了显存优化。动态范围扩展减少量化误差,混合粒度量化优化激活存储,两者协同作用使得端到端内存占用降低 1.54 倍。
这种优化不仅适用于单机训练,更在分布式训练中发挥关键作用 —— 通过批量大小翻倍,可在相同硬件条件下处理更多数据,显著提升训练效率。而对于显存资源紧张的研究者,COAT 也提供了全参数训练的可行路径,降低了大模型训练的门槛。
(文:PaperWeekly)