

当前,AI 图像生成技术迅猛发展,各类图文生成模型让用户能凭借简单文字描述创作出精美的图像。然而,这也引发了诸多问题,比如有人借此剽窃艺术风格、丑化 IP 角色和名人,甚至生成不安全图像。如何以低成本且高效的方式,精准快速地从生成图像中去除这些不想要的概念,成为亟待解决的难题。
这一概念擦除任务有两个关键要求:一是擦除效果,需在生成过程中彻底清除与目标概念相关的语义;二是先验保护,即擦除目标概念时尽量不影响无关概念的生成。但现有方法难以平衡二者。
为此,中国科学技术大学联合曼彻斯特大学等机构的研究团队,提出了一种名为自适应值分解器(AdaVD)的 training-free 方法。在无需额外训练的前提下,它实现了对目标概念的精准擦除,同时最大程度地保护了先验知识,相较于现有 SOTA 方法,先验保护能力提升 2 到 10 倍。该成果已被 CVPR2025 接收。

Precise, Fast, and Low-cost Concept Erasure in Value Space: Orthogonal Complement Matters
https://arxiv.org/pdf/2412.06143

现有方法的困境

现有概念擦除方法主要分为基于训练(training-based)和无训练(training-free)两类。基于训练的方法需要对模型参数进行微调,尽管擦除效果较好,但成本高昂,且处理速度较慢,难以满足在线 T2I 平台的实时需求。此外,这类方法往往难以在擦除目标概念的同时保护非目标概念。
而无训练方法,如 NP、SLD 和 SuppressEOT,虽然能够实现快速擦除,但各自存在不足。例如,NP 的擦除精度有限,SuppressEOT 需要用户手动指定目标概念的位置,而 SLD 在保护非目标概念的先验信息方面表现不佳,影响图像的整体质量。

AdaVD 如何破局
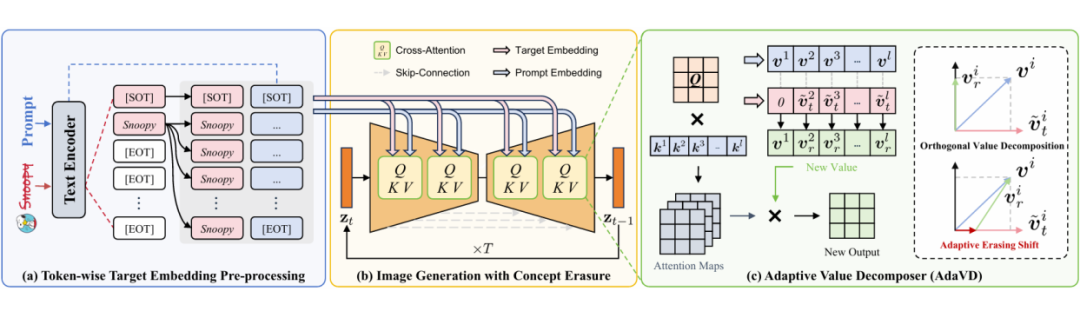

核心原理:正交补运算
作为一种无需训练的概念擦除方法,AdaVD 通过经典的正交补运算,在扩散模型 UNet 的值空间内进行精准擦除。具体而言,它将原始文本提示所对应的值投影到目标概念的正交补空间,从而剥离目标概念的语义,同时最大程度地保留其他内容。
此外,AdaVD 采用逐 token 计算方式,以确保对每个 token 的擦除精度,实现更灵活细致的概念擦除。

创新机制:自适应擦除移位
为了在保证擦除效果的同时进一步增强先验知识保护,AdaVD 还引入了自适应擦除移位机制(Adaptive Token Shift)。该机制基于文本 token 与目标概念 token 之间的语义相关性计算移位因子,从而动态调整擦除强度。
若某个 token 与目标概念的语义关联较低,AdaVD 会减少对其的擦除,从而在精准擦除目标概念的同时,最大程度地保留先验知识。

效果惊艳,实力验证
实验结果显示,AdaVD 在多个概念擦除任务中均表现出色,涵盖 IP 角色、艺术风格、NSFW 内容及名人相关概念等场景。与其他方法相比,AdaVD 在 CLIP Score(CS)和 FID 评分上均表现优异,前者反映擦除效果,后者衡量先验保护能力。

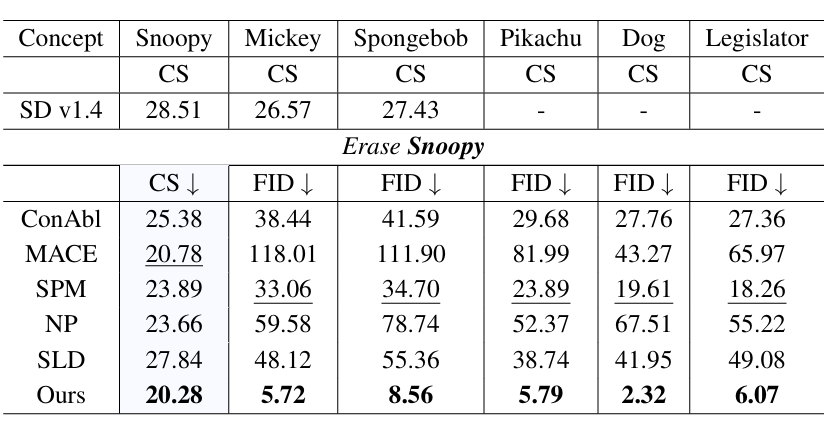
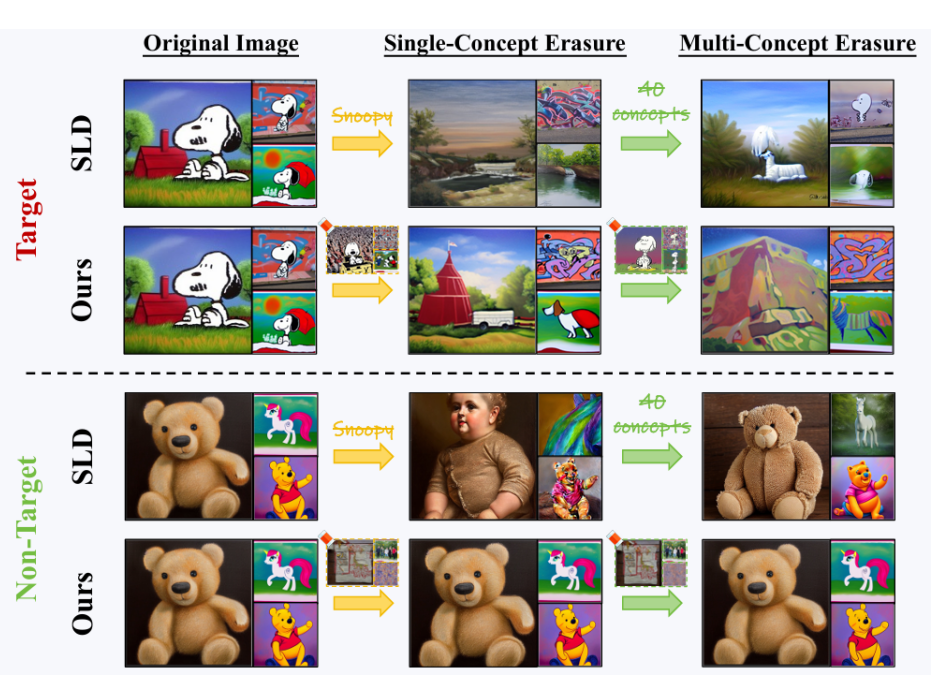
此外,在多概念擦除实验中,AdaVD 也展现出卓越的性能。例如,在同时擦除“Snoopy”“Mickey” 和 “Spongebob” 时,其 CS 和 FID 均优于其他方法,即便同时擦除 40 个概念,也能有效保护非目标概念,展现出强大稳定的擦除和先验保护能力。


效率与可解释性兼具
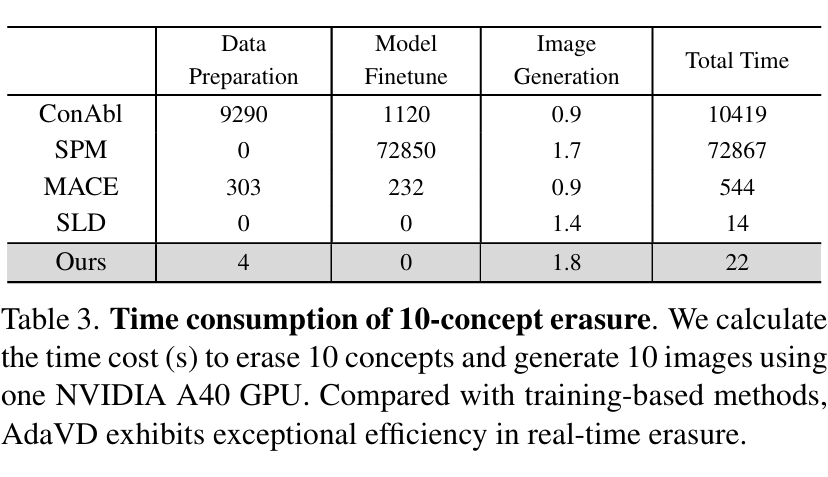
在时间消耗层面,AdaVD 由于无需模型微调,在运行速度上远超基于训练的方法。虽然比 SLD 略慢,但换来的却是更优的擦除性能,整体性价比更高。
此外,研究团队通过可视化擦除部分,深入探究了 AdaVD 的可解释性。结果显示,AdaVD 能够精准定位语义空间中与目标概念相关的语义信息。对于无关概念,其对应的擦除部分呈现出无意义的信息特征。这一现象进一步证实,AdaVD 不仅可以精准擦除目标概念,还能实现擦除效果与先验保护的良好平衡。


AdaVD 的能力不仅限于概念擦除,还可拓展至多个图像生成任务。例如,在隐式概念擦除中,它能去除 “rainy” “foggy” 等隐含概念;在图像编辑任务中,可精准移除 “glasses”“mustache” 等外观特征;在属性抑制任务中,可去除 “red” 等耦合颜色概念,如让苹果或玫瑰褪色。
此外,AdaVD 还能与多种扩散模型兼容,如 Chilloutmix、DreamShaper、RealisticVision 和 SD v2.1,适用性极为广泛。

(文:PaperWeekly)