


Figure创始人Brett Adcock表示:“欢迎观看我们发布过的最无聊的视频。”
该公司的目标是大规模生产人形机器人,并使之能够像人类一样完成真正有用的工作,这意味着机器人每天要在岗持续工作数小时,并保持不低于人的处理速度和性能目标,这对商业落地来说非常重要。

在演示视频中,快递分拣流水线上有大量不同的包裹种类,需要机器人实时输出微妙的行为策略进行灵活处理,而且克服偶尔出现的错误,展现了其内置VLA模型“Helix”近期的技术进步,Figure公司称之为:Scaling Helix。
不过,这种人形机器人在物流场景分捡的实用性引起了一些争议。
有网友吐槽,虽然流畅度相比同行(如特斯拉Optimus)有大幅改进,但目前人形机器人处理任务的速度仍不够快,根本无法适应现代自动化生产的处理需求,纯属作秀,分拣场景只需要传送带和扫描仪就能满足。

乐观派则认为,这可能是它有史以来最慢的一次,随着时间推移和技术进步,它们的速度只会越来越快,最重要的是它不睡觉,不抱怨,不会争吵,不会闹情绪,可以扩展多种应用场景。按美国工人平均年薪约6.5万美元,投入约2080小时算。一年有8760小时,相当于人类的四倍多,即使机器人的工作速度比人类慢三倍,它每年也能完成约2900个相当于人类的小时,大约是人类劳动的1.5倍或近10万美元的价值。

Figure官方表示,Helix现在可处理多种类包装,并且其灵活性和速度已接近人类水平,实现完全自主的包裹分拣。
1、更多包装类型——机器人可靠地操作可变形塑料袋、扁平信封或快递硬盒,并根据每种外形尺寸实时调整其抓握策略,动态地处理物体。
2、更快的吞吐量——尽管处理的包裹类型更加复杂多样,但执行速度从约每包裹5.0秒缩短至每包裹4.05秒,在保持准确性的同时实现了约20%的处理速度。

3、更高的条形码扫描成功率——通过视觉和控制,运输标签现在能够正确定向扫描,成功率约为95%。
4、自适应行为——机器人展现出从演示中学习到的微妙行为,例如轻轻拍打塑料邮件以抚平皱纹来改善条形码的读取。
看似普通的分拣流水线,对于机器人来说,每个时间步骤中包裹和场景都在不断变化,对其内置的“视觉-语言-动作”(VLA)模型来说是种挑战,Figure团队通过数据扩展和模型架构改进了Helix模型,重点是对视觉运动策略的架构增强。

据介绍,Helix引入了新的记忆和感知模块,使控制策略更加情境感知和稳健,能够更好地感知外部世界随时间的变化,并感受自身行为,从而补充了初始部署中建立的视觉和控制基础。
视觉记忆:Helix的策略现在能够保持对周围环境的短期视觉记忆,而非仅仅基于瞬时摄像机帧,具体来说,该模型可以从一系列近期视频帧中合成特征,从而获得场景的时间扩展视图。本质上,视觉记忆赋予Helix一种时间上下文感知能力,使其能够在多步骤操作中更具策略性地采取行动。
状态历史:近期状态历史记录增强了Helix的本体感受输入,从而实现了更快、更灵敏的控制。重要的是,状态历史记录保留了上下文,因此即使更频繁地重新规划,策略也不会丢失其当前操作的轨迹或破坏操作的稳定性。最终结果是能够更快地响应意外或干扰:如果包裹发生移动或尝试抓取时未完美落地,Helix会以最小的延迟纠正中间运动,显著缩短了每个包裹的处理时间。

力反馈:Figure 02机器人对其环境及其操控的物体施加的力现在已成为输入神经网络状态的一部分,这些信息使策略能够检测接触事件并进行相应调整。这提高了成功率和运动一致性,使系统对物体重量、刚度和位置的变化具有更强的鲁棒性。
最终,Figure 02机器人的分拣手法和操作熟练度上了个大台阶,离能实际干活儿的目标越来越近了。
为了量化改进的影响,Figure团队在不同的训练数据方案和模型配置下,对Helix模型的物流性能进行了受控评估。
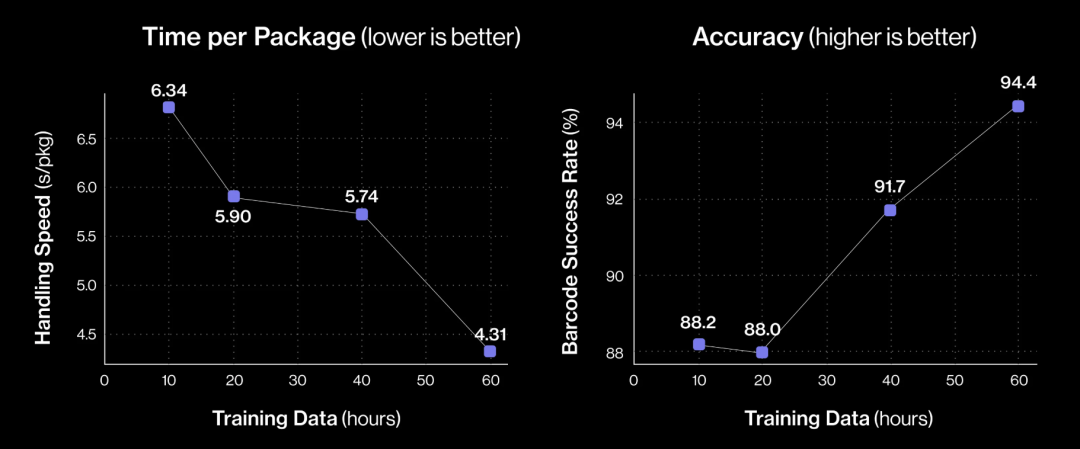
首先,研究扩展人类演示数据量对机器人熟练程度的影响,通过比较分别基于大约10、20、40和60小时的演示轨迹(具有相同的网络架构和超参数)训练的模型。
从10小时到60小时的训练演示来看,每件包裹平均处理时间从约6.84秒缩短至4.31秒,吞吐量提升了58%,条形码识别成功率也从88.2%攀升至94.4%。这些回报表明,该模型仍处于低数据量阶段,随着数据规模的扩大,模型性能将持续稳步提升。
其次,评估架构增强功能(视觉记忆、状态历史和力反馈)对性能的贡献。本次比较中的所有模型均基于相同的60小时数据集进行训练,因此任何指标差异都反映了新功能的存在与否。



-END-

(文:头部科技)