


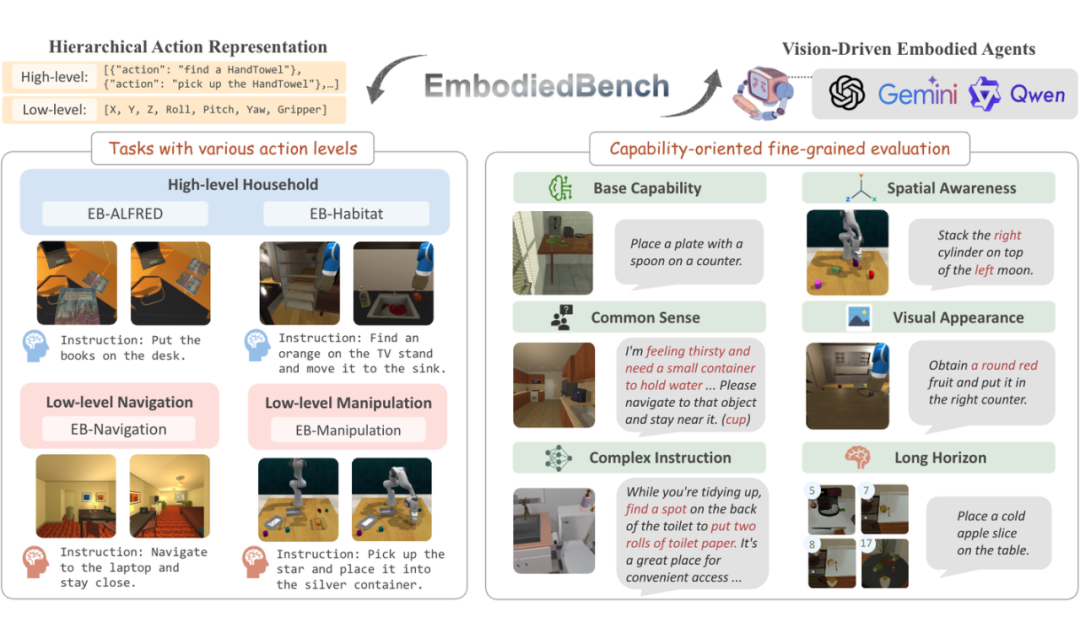
伊利诺伊大学香槟分校联合西北大学,多伦多大学,构建了致力于为 MLLM 驱动的具身智能体提供标准化、多维度评测的框架—— EmbodiedBench:


-
如 LotaBench、VisualAgentBench 等仅支持高层语义任务(如家庭场景规划),无法评估低层控制能力。
-
如 VLMBench、GOAT-bench 等专注于低层操作或导航,但缺乏高层任务理解和分解。
4. 现有数据集的质量问题及其改进:当前部分常用数据集存在低质量现象。例如,在 ALFRED 数据集中,标准任务要求操作 “Tomato”(番茄),但语言指令却指向 “Potato”(土豆);此外,相似概念(如 “Bottle” 和 “Cup”)的指令描述模糊不清,导致任务失败并非源于模型能力,而是数据本身。
此外,LotaBench 提供的仿真器也存在局限性,例如不支持多物品操作,以及正确动作无法成功执行(如将物品放入水槽却只能放置到边缘),这些仿真器的问题同样影响了任务的完成。针对这些缺陷,我们在设计新数据集和仿真器时,通过人工检查与修复,提升了数据质量与仿真环境的可靠性。
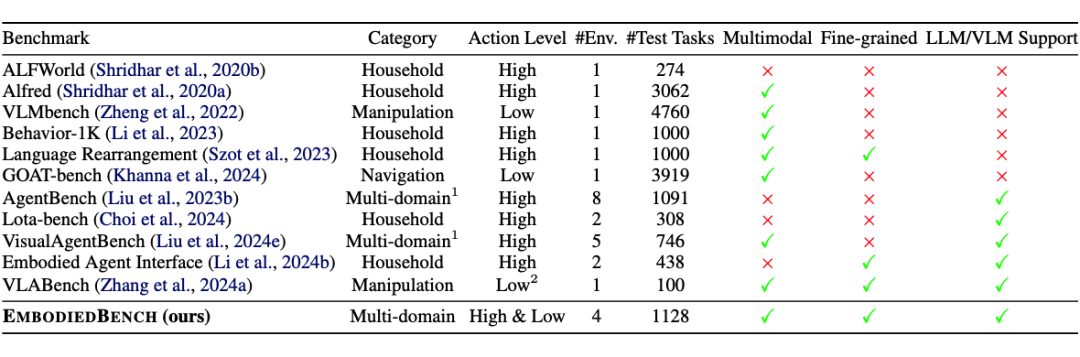

EmbodiedBench设计:任务维度多样性,能力维度多样性

2.1 同时覆盖高&低层次任务:
-
高层次任务环境:1. EB-ALFRED & 2. EB-Habitat 环境包含高层次语义任务,强调任务分解与规划。例如,“把一本书放到桌子上”这样的家庭场景任务,需要模型理解语义指令并规划一系列子步骤去完成
-
低层次任务环境:1. EB-Navigation & 2. EB-Manipulation 环境包含低层次操作任务,要求模型通过原子动作来完成目标。例如导航任务需要通过连续的前进、转向等底层动作在空间中移动,操作任务需要精确控制机械臂的平移/旋转来抓取或操作物体。这类任务对模型的感知精度和空间推理能力提出了更高要求。
层次化的动作粒度:通过上述环境的设计,EmbodiedBench 囊括了高层次动作(如拾起/放下物体这样的宏动作)和低层次控制(如机器人逐步移动和操纵)的任务类型。这样的多层次任务设置使我们能够同时评估模型在“大局规划”和“细节执行”两个层面上的表现。
-
基础任务解决:完成基本任务的能力,衡量模型对指令的基本执行力(相当于总体任务成功率的基础部分)。
-
常识推理:常识性理解能力。通过将物体名称替换为常识性描述,考察模型根据常识进行推断的能力:比如将 cup(水杯)替换为 “a small container to hold water or coffee”。
-
复杂指令理解:考察当指令中包含复杂和不相关的信息时,模型提取关键指令的能力
-
空间认知:理解和推理空间关系的能力,包括导航路径规划、方位朝向理解,以及对“三维空间中物体位置”的把握。
-
视觉感知:通过物品的外观,颜色或者形状信息正确识别目标物体的能力。
-
长期规划:面向长时间跨度任务的规划能力。这涉及在需要很多步骤才能完成的任务中保持合理的计划和顺序,不遗漏关键步骤。
通过以上六个维度的评估,EmbodiedBench 能够识别出模型的长处和短板。例如,如果一个模型常识推理得分低,可能意味着它缺乏对日常物理知识的理解;空间认知差则意味着它可能在导航或定位物体方面表现不佳。

视觉驱动的智能体框架,有效提升低层级任务执行
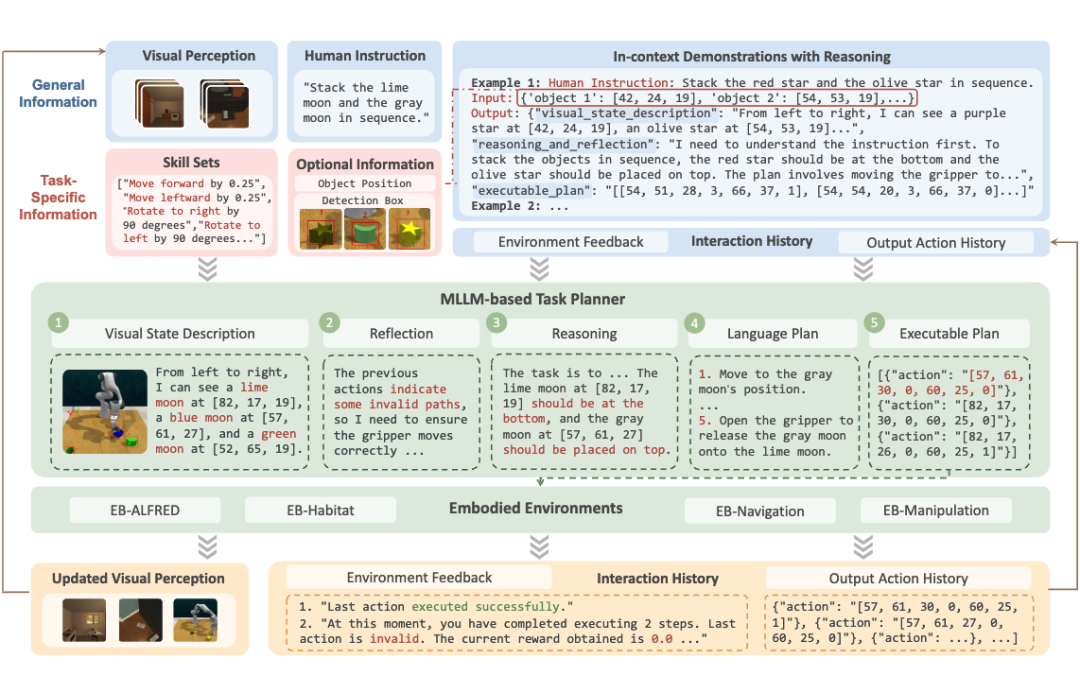
▲ EmbodiedBench 中提出的视觉驱动的智能体框架
语言指令:用户或系统通过自然语言发出任务需求(例如“去厨房拿一个苹果”),提供高层次意图。
当前帧图像:从视觉传感器或摄像头获取的实时画面,用于识别场景、定位目标和理解环境状态。
历史交互:记录机器人过去的动作执行情况、已经做过的尝试以及与用户或环境的互动信息,帮助机器人保持上下文连续性。
环境反馈:例如动作是否执行成功、是否被阻挡、物体是否可达等。这些反馈让机器人了解执行效果,进而进行动态调整。
-
检测框标注(EB-Manipulation)
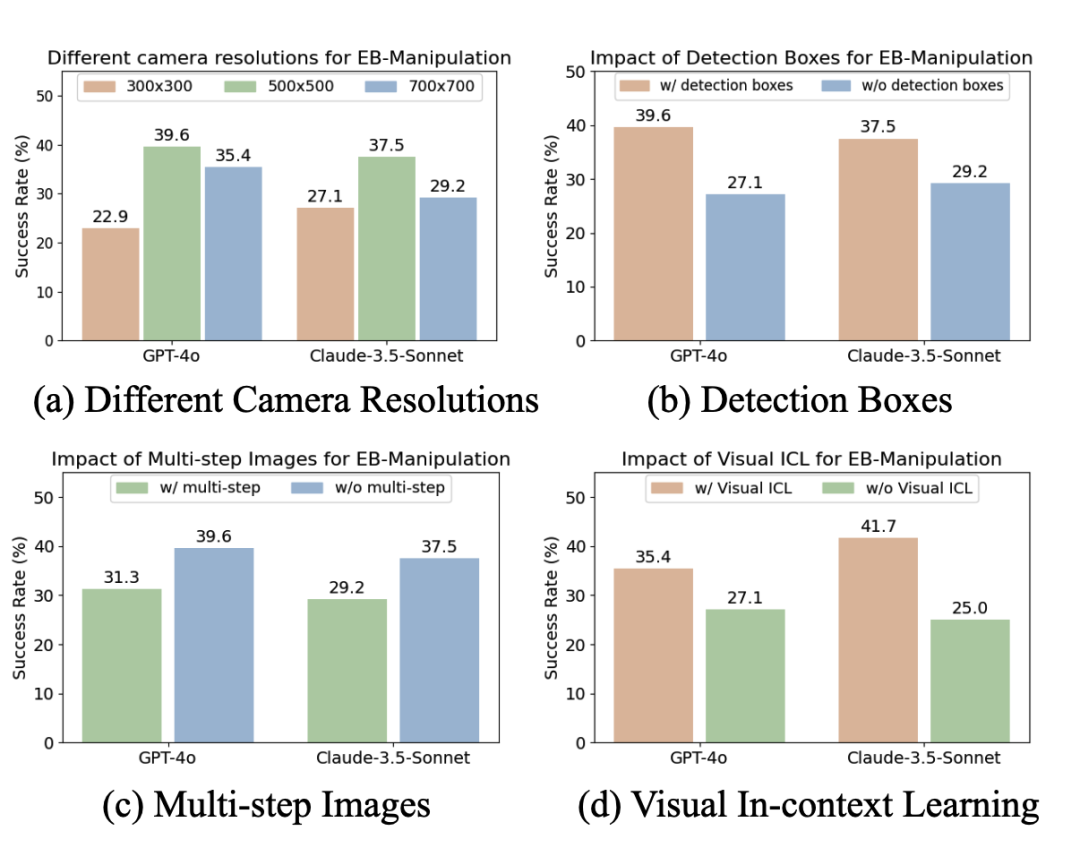
通过 YOLO 等检测算法为图像中的物体生成带有索引的边界框,帮助机器人精准地识别与定位目标。 这样做能减少对文字描述定位的依赖,成功率可提升 10%-12%。
-
分辨率优化
将图像分辨率固定在 500×500 像素,兼顾清晰度和处理速度。 如果分辨率过低(如 300×300),可能遗漏关键细节;如果过高(如 700×700),则会带来不必要的噪声和算力开销。
3.2 如何规划
3.2.1 Embodied-Aware CoT Prompting
通过“思考链(Chain of Thought)”的方式,让系统依次完成以下四个步骤,实现更符合实际环境的决策。在具体实现中,我们使用 “Structured Json Output” 来规范模型的输出格式,来保证按顺序完成下列推理轨迹:
Visual State Description:描述当前场景中重要的视觉元素,如物体位置、环境布局等。
Reasoning and Reflection:根据视觉信息和任务目标进行推理和反思,思考可能的方案以及可行性。
Language Plan:以语言或符号的形式输出具体的执行计划,方便后续转化成可执行命令。
Executable Plan:将上一步的计划进一步拆分成机器人可执行的动作指令(如移动、抓取、旋转等)。
通过各部分的配合(输入融合、规划决策、反馈调整),该框架能够在实际环境中高效地完成多模态指令下的各类操作任务。



实验:有哪些有意思的发现
经过对这 19 个模型的大量实验,我们展示以下发现:
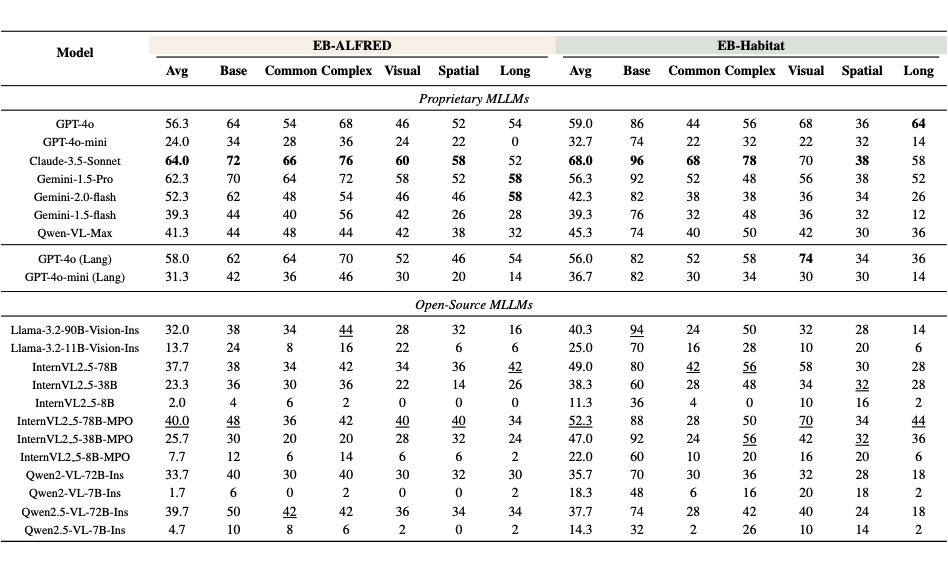
4.1.1 高层次任务表现优异,低层次抓取仍是短板:
总体而言,MLLM 模型在高层语义任务上表现出色。例如,给模型一个需要规划步骤的家庭场景指令,大多数模型都能合理地分解任务并给出接近正确的行动序列。
然而,在低层次物体操作等精细任务上,它们的表现远不如高层次任务。尤其是涉及机械臂精确操作、连续控制的任务,当前模型的成功率很低。例如,即便是表现最好的 GPT-4 模型,在这些低层次操作任务上的平均成功率也不到 30%。这表明虽然大模型“懂”要做什么,但在“如何动手做”上依然面临巨大挑战。
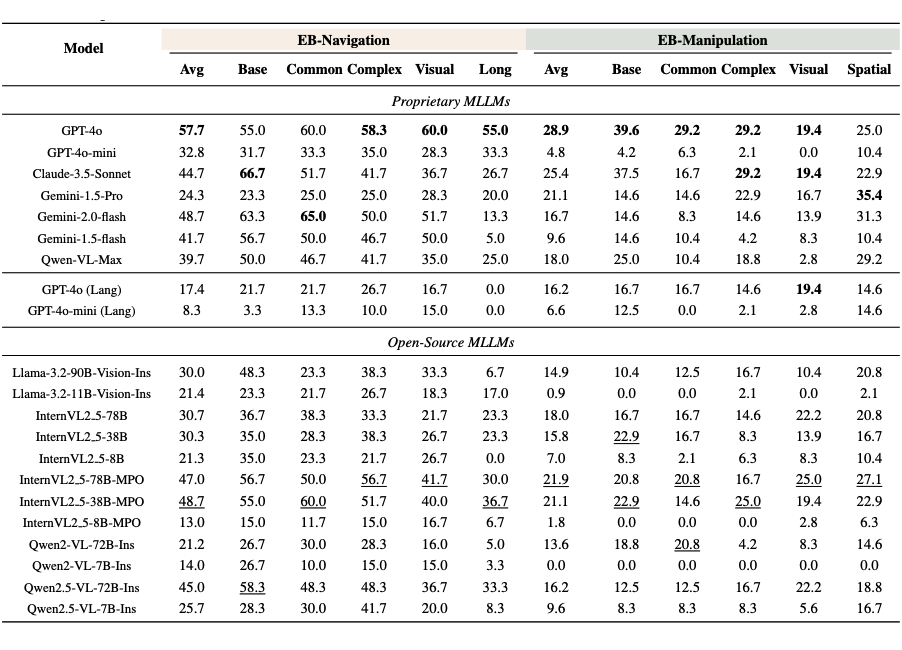
4.1.2 长程规划任务表现不佳,是当前瓶颈:
在所有任务类型中,需要长远规划的任务对模型来说最具挑战。EmbodiedBench 专门设计了需要十几步乃至数十步行动才能完成的复杂任务来测试模型的长程规划能力。结果显示,几乎所有模型在这类任务上的成功率都大幅下降,远低于短程任务。这意味着让模型在较长的时间跨度内保持连贯的计划仍然是难点。
模型常常在执行一系列步骤后出现策略混乱或遗漏关键步骤的情况,难以可靠地完成长链条任务。这一发现揭示了当前 MLLMs 在处理长序列决策时的局限,需要进一步的模型优化来提升其“全局思维”能力。
4.1.3 视觉输入对低层任务至关重要,对高层任务影响较小:
这表明在此类任务中,模型需要从视觉中获取对象位置、环境状态等关键信息,才能制定正确的低层行动决策。相比之下,在高层次任务(如家庭场景的指令执行)中,即使不给模型实际的环境图像,模型仅凭借常识和对指令的理解也能较好地规划步骤,视觉信息对成绩提升相对有限。
这一发现很有趣地表明:当前大模型解决高层抽象任务时受限于认知和推理能力,而解决低层具体任务时受限于对视觉世界的感知和操作能力。
在低层次任务上,我们测试了不同视觉维度对于任务表现的影响,总结为下列发现:


最后,基于 EmbodiedBench,我们能做些什么?
-
提升低级任务执行和空间推理能力:现有模型在空间推理和低级控制方面存在不足,未来研究可结合 3D 视觉定位和对齐技术,提升智能体的精细操作能力。
-
强化长远规划能力:现有智能体在执行复杂的长步骤任务时表现不佳,未来可研究分层规划、记忆增强方法和世界模型,以提升长远规划和执行能力。
-
优化多步/多视角图像理解:当前模型难以处理多步、多视角的视觉信息,未来研究可借助视频预训练技术提升时间推理和空间理解能力。
-
改进视觉上下文学习(ICL):视觉ICL有助于提高智能体的适应性,无需额外训练即可增强决策能力,未来研究可探索更高效的方法,使其在具体任务中的应用更广泛。
-
训练多模态智能体:当前研究主要关注评估,未来可研究如何针对具体任务优化 MLLMs,包括预训练、模仿学习、强化学习等,从而提高其决策能力,并实现端到端学习,使感知、推理和行动自然结合。
-
提升模型的鲁棒性和泛化能力:为了确保在现实世界中的可靠性,未来研究可引入对抗训练、动态环境生成和领域迁移等方法,以增强智能体在不同环境下的稳定性和适应性。
EmbodiedBench 已开源包括所有代码,数据(Comprehensive Benchmarking Multi-modal Large Language Models for Vision-Driven Embodied Agents),我们期待与社区共同推动多模态具身智能的前沿探索。
(文:PaperWeekly)