从 0 手撕 LLM 分布式训练:DP, ZeRO, TP, PP, CP, EP

小冬瓜AIGC发布的X-R1开源框架课程,手撕PyTorch的五大并行算法DP、TP、PP、CP、EP,并实现分布式训练中的关键算法如Backward和MoE。该课程包含实操项目及多个测评工具,适合对LLM技术有兴趣的学员。
小冬瓜AIGC发布的X-R1开源框架课程,手撕PyTorch的五大并行算法DP、TP、PP、CP、EP,并实现分布式训练中的关键算法如Backward和MoE。该课程包含实操项目及多个测评工具,适合对LLM技术有兴趣的学员。

现高校LLM对齐研究课程介绍,涵盖手撕PyTorch五大并行算法DP、TP、PP、CP和EP,以及Backward梯度计算与重叠通信技术。课程内容丰富,提供多卡DeepSpeed RLHF训练及垂域大模型实操项目。

近期研究提出COAT方法利用FP8量化技术,通过动态范围扩展和混合粒度精度流优化大型模型训练中的内存占用和加速速度,保持模型精度的同时显著减少显存使用并提升训练效率。
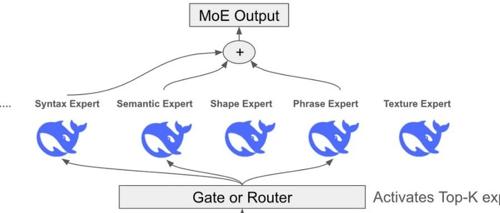
DeepSeek 开源周第二天,带来了 DeepEP 通信库,旨在优化混合专家系统和专家并行模型的高效通信。其亮点包括高效的全员协作通道、专为训练和推理预填充设计的核心以及灵活调控GPU资源的能力,显著提升MoE模型的性能和效率。