


邮箱|zhouyixiao@pingwest.com

-
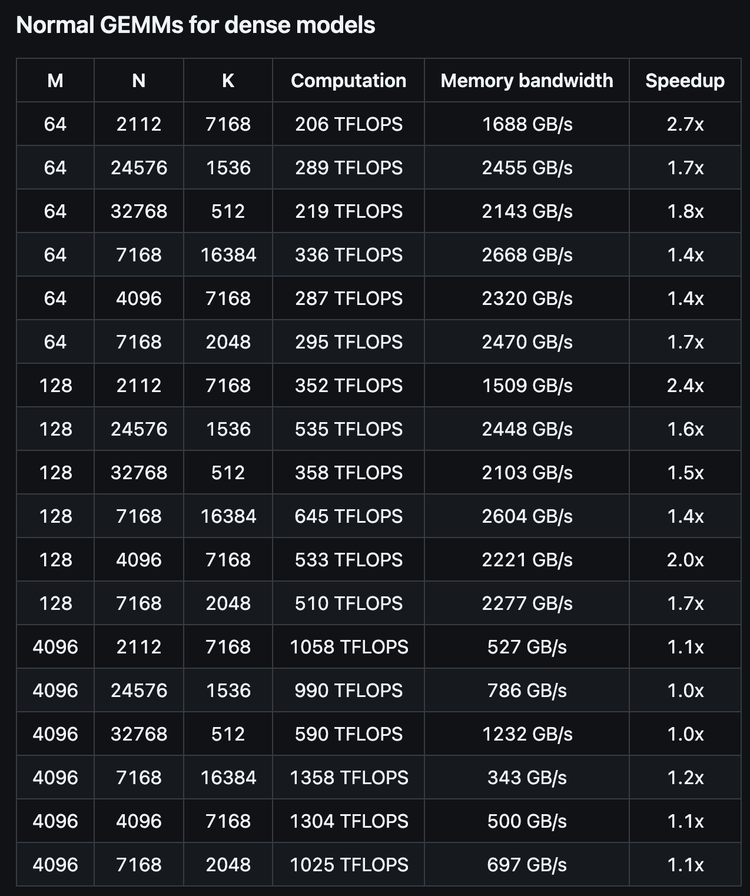
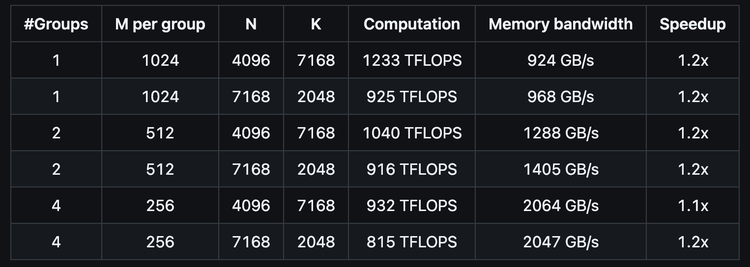
Hopper GPU上最高可达1350+ FP8 TFLOPS
-
没有过多的依赖,像教程一样简洁
-
完全即时编译
-
核心逻辑约为300行 – 但在大多数矩阵大小上均优于专家调优的内核
-
支持密集布局和两种MoE布局
#01

#02
-
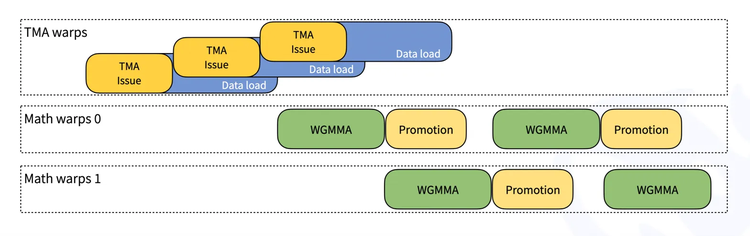
Warp 专用内核:基于 CUTLASS 设计,实现数据移动、张量核心 MMA(矩阵乘加)指令及 CUDA 核心提升的并发执行,以提升吞吐量。
-
张量内存加速器(TMA):利用 Hopper 架构中的 TMA 实现异步、高速数据传输,包括 LHS/RHS 矩阵加载、输出存储、LHS 的多播以及描述符预取。
-
专用 PTX 指令:采用 stmatrix 实现高效的线程束级别矩阵存储,并针对线程组进行寄存器数量控制,以优化资源分配。
-
重叠操作:最大化 TMA 存储与非 TMA 右操作数缩放因子加载的重叠,此技术在 CUTLASS 中未见应用
-
统一调度器与光栅化:采用单一调度器处理所有内核类型及线程块光栅化,以提升 L2 缓存复用率。
-
即时(JIT)编译:基于全 JIT 的设计在运行时编译内核,将 GEMM 形状、块大小和流水线阶段视为常量以节省寄存器并进行编译器优化,同时完全展开 MMA 流水线。
-
未对齐的块大小:支持非 2 的幂次方的块大小(如 112),以最大化流式多处理器(SM)利用率,适应不规则形状,提升可扩展性。
-
SASS 级微调:通过翻转编译二进制文件中 FFMA(融合乘加)指令的 yield 和 reuse 位,提升 warp 级并行性和指令重叠,适用于浮点运算
-
CUTLASS 启发式设计:借鉴并扩展了 CUTLASS 的技术,并加入了如 TMA 重叠等额外优化
#03

(文:硅星GenAI)