
0x0. 序
本篇文档的来源:https://github.com/stas00/ml-engineering 。这篇文档是NVIDIA GPU故障排查的实用指南,主要包含以下干货内容:
-
Xid错误的识别和处理:文档详细解释了如何通过系统日志识别Xid错误,以及如何使用nvidia-smi命令查看错误计数和具体情况。 -
ECC错误处理:介绍了单比特(SBE)和双比特(DBE) ECC错误的区别,以及如何通过nvidia-smi -q命令检查和处理这些错误。 -
GPU诊断工具使用:详细介绍了如何使用DCGM工具进行GPU诊断,包括不同级别(-r 2/3/4)的诊断方法和各自适用场景。 -
硬件信息查询:包括如何获取VBIOS信息、检查PCIe带宽、验证NVLink连接状态等实用命令。 -
GPU使用率监控:介绍了如何通过dcgm-exporter获取真实的GPU使用率指标,而不是仅仅依赖nvidia-smi显示的假的GPU使用率。
这些内容对于从事大规模机器学习训练的工程师特别有用,可以帮助我们更好地监控和维护GPU集群,及时发现和解决硬件问题。文档提供的命令和工具都非常实用,可以作为GPU运维的重要参考。总的来说,是非常实用的一个资料,推荐给读者。下面是全文:
NVIDIA GPU 故障排除
术语表
-
DBE: 双位 ECC 错误 -
DCGM: NVIDIA 数据中心 GPU 管理器 -
ECC: 错误校正码 -
FB: 帧缓冲器 -
SBE: 单位 ECC 错误 -
SDC: 静默数据损坏
Xid 错误
没有完美的硬件,有时由于制造问题或磨损(尤其是因为暴露在高温环境中),GPU 很可能遇到各种硬件问题。许多这些问题会自动纠正,无需真正了解发生了什么。如果应用程序继续运行,通常没有什么需要担心的。但如果应用程序因硬件问题而崩溃,了解原因并采取相应行动就很重要。
对于只使用少量 GPU 的普通用户来说,可能永远不需要了解 GPU 相关的硬件问题。但如果你进行大规模机器学习训练,可能会使用数百到数千个 GPU,那么你肯定会想要了解不同的硬件问题。
在系统日志中,你可能会偶尔看到类似这样的 Xid 错误:
NVRM: Xid (PCI:0000:10:1c): 63, pid=1896, Row Remapper: New row marked for remapping, reset gpu to activate.
获取这些日志可以通过以下方式之一:
sudo grep Xid /var/log/syslog
sudo dmesg -T | grep Xid
通常,只要训练不崩溃,这些错误往往表示可以被硬件自动纠正的问题。
完整的 Xid 错误列表及其解释可以在这里找到(https://docs.nvidia.com/deploy/xid-errors/index.html)。
你可以运行 nvidia-smi -q 查看是否报告了任何错误计数。例如,在 Xid 63 的情况下,你会看到类似这样的内容:
Timestamp : Wed Jun 7 19:32:16 2023
Driver Version : 510.73.08
CUDA Version : 11.6
Attached GPUs : 8
GPU 00000000:10:1C.0
Product Name : NVIDIA A100-SXM4-80GB
[...]
ECC Errors
Volatile
SRAM Correctable : 0
SRAM Uncorrectable : 0
DRAM Correctable : 177
DRAM Uncorrectable : 0
Aggregate
SRAM Correctable : 0
SRAM Uncorrectable : 0
DRAM Correctable : 177
DRAM Uncorrectable : 0
Retired Pages
Single Bit ECC : N/A
Double Bit ECC : N/A
Pending Page Blacklist : N/A
Remapped Rows
Correctable Error : 1
Uncorrectable Error : 0
Pending : Yes
Remapping Failure Occurred : No
Bank Remap Availability Histogram
Max : 639 bank(s)
High : 1 bank(s)
Partial : 0 bank(s)
Low : 0 bank(s)
None : 0 bank(s)
[...]
在这里我们可以看到 Xid 63 对应的是:
ECC page retirement or row remapping recording event
这可能有3个原因:硬件错误 / 驱动程序错误 / 帧缓冲器(FB)损坏
这个错误意味着其中一个内存行出现故障,在重启和/或 GPU 重置时,将使用 640 个备用内存行(在 A100 中)之一来替换故障行。因此,我们在上面的报告中看到只剩下 639 个存储体(共 640 个)。
ECC Errors 报告中的 Volatile 部分指的是自上次重启/GPU 重置以来记录的错误。Aggregate 部分记录了自 GPU 首次使用以来的相同错误。
现在,有两种类型的错误 – 可纠正和不可纠正。可纠正的是单比特 ECC 错误(SBE),尽管内存有故障,但驱动程序仍然可以恢复正确的值。不可纠正的是多于一个比特出现故障,称为双比特 ECC 错误(DBE)。通常,如果在同一内存地址发生 1 次 DBE 或 2 次 SBE 错误,驱动程序将退役整个内存页。有关完整信息,请参阅此文档(https://docs.nvidia.com/deploy/dynamic-page-retirement/index.html)
可纠正的错误不会影响应用程序,不可纠正的错误会导致应用程序崩溃。包含不可纠正 ECC 错误的内存页将被列入黑名单,在 GPU 重置之前无法访问。
如果有页面被安排退役,你将在 nvidia-smi -q 的输出中看到类似这样的内容:
Retired pages
Single Bit ECC : 2
Double Bit ECC : 0
Pending Page Blacklist : Yes
每个退役的页面都会减少应用程序可用的总内存。但是退役页面的最大数量总共只有4MB,所以它不会显著减少可用的GPU总内存。
要更深入地了解GPU调试,请参考这个文档(https://docs.nvidia.com/deploy/gpu-debug-guidelines/index.html) – 它包含了一个有用的分类图表,可以帮助确定何时需要RMA GPU。这个文档还包含了关于Xid 63类似错误的额外信息。
例如它会提示:
如果与 XID 94 关联,应用程序遇到错误需要重启。所有其他系统上的应用程序可以保持运行,直到有一个合适的时间重启以激活行重映射。 请参阅下面的指引来确定何时需要基于行重映射失败来RMA GPU。
如果重启后,同样的条件再次出现,意味着内存重映射失败,并且会再次发出Xid 64。如果这继续,你有一个硬件问题,无法自动修复并且GPU需要RMA’ed。
有时你可能会遇到Xid 63或64错误并且应用程序会崩溃。这通常会产生额外的Xid错误,但大多数情况下意味着该错误是不可纠正的(即它是DBE类型的错误,然后会变成Xid 48)。
如前所述,要重置GPU,你可以简单地重启机器,或者运行:
nvidia-smi -r -i gpu_id
其中 gpu_id 是你想要重置的 GPU 的序列号,例如第一个 GPU 的 0。如果不使用 -i 参数,所有 GPU 都将被重置。
遇到不可纠正的 ECC 错误
如果你遇到以下错误:
CUDA error: uncorrectable ECC error encountered
与上一节一样,这次检查 nvidia-smi -q 的输出,查看 ECC Errors 条目,可以告诉你哪个 GPU 是有问题的。但如果你需要快速检查,以便在节点至少有一个 GPU 存在此问题时进行回收,你可以这样做:
$ nvidia-smi -q | grep -i correctable | grep -v 0
SRAM Uncorrectable : 1
SRAM Uncorrectable : 5
在一个正常的节点上,这应该返回空值,因为所有计数器应该为 0。但在上面的例子中,我们有一个损坏的 GPU – 因为完整记录是:
ECC Errors
Volatile
SRAM Correctable : 0
SRAM Uncorrectable : 1
DRAM Correctable : 0
DRAM Uncorrectable : 0
Aggregate
SRAM Correctable : 0
SRAM Uncorrectable : 5
DRAM Correctable : 0
DRAM Uncorrectable : 0
这里的第一个条目是 Volatile (错误计数器从 GPU 驱动程序重新加载后开始计数),第二个是 Aggregate (整个生命周期内的错误计数器)。在这个例子中,我们看到 Volatile SRAM Uncorrectable 错误计数为 1,Aggregate 为 5 – 该错误不是第一次出现。
这通常意味着它是 Xid 94 错误,但通常不会有 Xid 48 错误。
为了解决这个问题,你可以重置这个 GPU:
nvidia-smi -r -i gpu_id
重启机器将产生相同的效果。
现在,对于累计 SRAM 不可纠正错误,如果你有超过 4 个,通常就是需要 RMA 该 GPU 的理由。
运行诊断
如果你怀疑一个给定节点上有一个或多个 NVIDIA GPU 出现故障,dcgmi 是一个快速找出任何故障 GPU 的好工具。
NVIDIA® 数据中心 GPU 管理器(DCGM)的文档在这里(https://docs.nvidia.com/datacenter/dcgm/latest/user-guide/index.html),可以从这里下载(https://github.com/NVIDIA/DCGM#quickstart)。
这里是一个 slurm 脚本示例,它将运行非常深入的诊断(-r 3),在一个 8-GPU 节点上大约需要 10 分钟完成:
$ cat dcgmi-1n.slurm
#!/bin/bash
#SBATCH --job-name=dcgmi-1n
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=1
#SBATCH --cpus-per-task=96
#SBATCH --gres=gpu:8
#SBATCH --exclusive
#SBATCH --output=%x-%j.out
set -x -e
echo"START TIME: $(date)"
srun --output=%x-%j-%N.out dcgmi diag -r 3
echo"END TIME: $(date)"
现在在特定节点上运行它:
sbatch --nodelist=node-115 dcgmi-1n.slurm
sbatch --nodelist=node-151 dcgmi-1n.slurm
sbatch --nodelist=node-170 dcgmi-1n.slurm
编辑 nodelist 参数以指向要运行的节点名。
如果节点被排除或下线,你可以直接在该节点上运行命令行:
dcgmi diag -r 3
如果诊断没有发现问题,但应用程序仍然无法正常工作,请重新运行诊断,级别为 4,这将需要更长时间(约 1 小时):
dcgmi diag -r 4
注:显然静默数据损坏(SDC)只能通过 dcgmi diag -r 4 检测到,即使这样也可能会漏掉一些。这个问题偶尔会发生,你甚至可能不知道你的 GPU 有时会搞乱 matmul。我很确定我们遇到过这种情况,因为我们在训练过程中遇到了奇怪的故障,我花了很多天与 NVIDIA 团队一起诊断问题,但我们都没能找出原因 – 最终问题消失了,可能是因为有问题的 GPU 由于报告的故障被替换了。
例如,如果你遇到重复的 Xid 64 错误,诊断报告可能会包括:
+---------------------------+------------------------------------------------+
| Diagnostic | Result |
+===========================+================================================+
|----- Deployment --------+------------------------------------------------|
| Error | GPU 3 has uncorrectable memory errors and row |
| | remappings are pending |
所以如果重新映射失败,你现在知道要对那个有问题的 GPU 进行 RMA。
但实际上,我发现大多数情况下 -r 2 已经能够检测到故障 GPU。而且它只需几分钟就能完成。以下是故障节点上 -r 2 输出的一个例子:
| GPU Memory | Pass - GPUs: 1, 2, 3, 4, 5, 6, 7 |
| | Fail - GPU: 0 |
| Warning | GPU 0 Thermal violations totaling 13.3 second |
| | s started at 9.7 seconds into the test for GP |
| | U 0 Verify that the cooling on this machine i |
| | s functional, including external, thermal mat |
| | erial interface, fans, and any other componen |
| | ts.
dcgmi 工具包含多个其他级别的诊断,其中一些在几分钟内完成,可以作为 SLURM 作业的尾声进行快速诊断,以确保节点准备好为下一个 SLURM 作业工作,而不是等到用户启动作业并崩溃后再发现。
在提交 RMA 报告时,你将被要求运行 nvidia-bug-report 脚本,其输出需要与 RMA 请求一起提交。
我通常也会保存日志以备后用,使用以下其中之一:
dcgmi diag -r 2 | tee -a dcgmi-r2-`hostname`.txt
dcgmi diag -r 3 | tee -a dcgmi-r3-`hostname`.txt
dcgmi diag -r 4 | tee -a dcgmi-r4-`hostname`.txt
如何获取 VBIOS 信息
在研究问题时,GPU VBIOS 版本可能很重要。让我们将名称和总线 ID 添加到查询中,我们得到:
$ nvidia-smi --query-gpu=gpu_name,gpu_bus_id,vbios_version --format=csv
name, pci.bus_id, vbios_version
NVIDIA H100 80GB HBM3, 00000000:04:00.0, 96.00.89.00.01
[...]
NVIDIA H100 80GB HBM3, 00000000:8B:00.0, 96.00.89.00.01
提示:要查询其他许多内容,请运行:
nvidia-smi --help-query-gpu
如何检查你的 GPU 的 PCIe 生成是否受支持
检查系统启动消息中的 PCIe 带宽报告:
$ sudo dmesg | grep -i 'limited by'
[ 10.735323] pci 0000:04:00.0: 252.048 Gb/s available PCIe bandwidth, limited by 16.0 GT/s PCIe x16 link at 0000:01:00.0 (capable of 504.112 Gb/s with 32.0 GT/s PCIe x16 link)
[...]
[ 13.301989] pci 0000:8b:00.0: 252.048 Gb/s available PCIe bandwidth, limited by 16.0 GT/s PCIe x16 link at 0000:87:00.0 (capable of 504.112 Gb/s with 32.0 GT/s PCIe x16 link)
在这个例子中,由于 PCIe 5 规范是 504Gbps,你可以看到在此节点上只有一半的可用带宽,因为 PCIe 开关是 gen4。对于 PCIe 规范,请参见此(https://github.com/BBuf/ml-engineering/tree/master/network#pcie)。
由于大多数情况下你有 NVLink(https://github.com/BBuf/ml-engineering/tree/master/network#nvlink)连接 GPU 到 GPU,这不会影响 GPU 之间的通信,但它会减慢与主机之间的数据传输,因为数据速度受到最慢的链路限制(504Gbps)。
如何检查 NVLink 链接的错误计数器
如果你对你的 NVLink 有任何担忧,你可以检查其错误计数器:
$ nvidia-smi nvlink -e
GPU 0: NVIDIA H100 80GB HBM3 (UUID: GPU-abcdefab-cdef-abdc-abcd-abababababab)
Link 0: Replay Errors: 0
Link 0: Recovery Errors: 0
Link 0: CRC Errors: 0
Link 1: Replay Errors: 0
Link 1: Recovery Errors: 0
Link 1: CRC Errors: 0
[...]
Link 17: Replay Errors: 0
Link 17: Recovery Errors: 0
Link 17: CRC Errors: 0
另外一个有用的命令是:
$ nvidia-smi nvlink --status
GPU 0: NVIDIA H100 80GB HBM3 (UUID: GPU-abcdefab-cdef-abdc-abcd-abababababab)
Link 0: 26.562 GB/s
[...]
Link 17: 26.562 GB/s
这个命令告诉你每个链接的当前速度。
运行 nvidia-smi nvlink -h 来发现更多功能(报告,重置计数器等)。
如何检查节点是否缺少 GPU
如果你获得了新的虚拟机,有时候你会得到少于预期的 GPU 数量。这里是如何快速测试你是否有 8 个 GPU 的方法:
cat << 'EOT' >> test-gpu-count.sh
#!/bin/bash
set -e
# test the node has 8 gpus
test $(nvidia-smi -q | grep UUID | wc -l) != 8 && echo "broken node: less than 8 gpus" && false
EOT
然后:
bash test-gpu-count.sh
如何检测是否一次又一次获得相同的故障节点
这主要与租用 GPU 节点的云用户相关。
你启动了一个新的虚拟机,发现它有一个或多个损坏的 NVIDIA GPU。你将其丢弃并启动了一个新的,但 GPU 又出现故障。
很可能你得到了相同的节点和相同的故障 GPU。以下是你可以知道的方式。
在丢弃当前节点之前,请运行并记录:
$ nvidia-smi -q | grep UUID
GPU UUID : GPU-2b416d09-4537-ecc1-54fd-c6c83a764be9
GPU UUID : GPU-0309d0d1-8620-43a3-83d2-95074e75ec9e
GPU UUID : GPU-4fa60d47-b408-6119-cf63-a1f12c6f7673
GPU UUID : GPU-fc069a82-26d4-4b9b-d826-018bc040c5a2
GPU UUID : GPU-187e8e75-34d1-f8c7-1708-4feb35482ae0
GPU UUID : GPU-43bfd251-aad8-6e5e-ee31-308e4292bef3
GPU UUID : GPU-213fa750-652a-6cf6-5295-26b38cb139fb
GPU UUID : GPU-52c408aa-3982-baa3-f83d-27d047dd7653
这些 UUID 是每个 GPU 的唯一标识符。
当你重新创建虚拟机时,运行此命令 – 如果 UUIDs 相同 – 你知道你有相同的损坏 GPU。
要自动化此过程,以便始终有此数据,你必须在启动过程中的某个地方添加:
nvidia-smi -q | grep UUID > nvidia-uuids.$(hostname).$(date '+%Y-%m-%d-%H:%M').txt
你可能希望将日志文件保存在某个持久文件系统上,以便在重启后仍能保留。如果没有这样的文件系统,可以将其保存在本地并立即复制到云中。这样,当你需要时,它将始终可用。
有时候,仅重启节点就能获得新硬件。在某些情况下,几乎每次重启都会获得新硬件,而在其他情况下,则不会发生这种情况。这种行为可能因提供商而异。
如果你不断获得相同的故障节点,一种克服这一问题的技巧是分配一个新的虚拟机,同时保持故障虚拟机在运行状态,当新虚拟机启动后,再丢弃故障的虚拟机。这样,你肯定会获得新的 GPU——但不能保证它们也不会出现故障。如果使用场景适合,可以考虑建立一个静态集群,在那里更容易保持良好的硬件。
这种方法在 GPU 不立即故障而是在使用一段时间后故障时尤为关键,这使得发现问题并非易事。即使你向云提供商报告了此节点,技术人员可能也不会立即注意到问题,并将故障节点重新投入使用。因此,如果你没有使用静态集群,并且倾向于按需获取随机虚拟机,你可能需要记录故障 UUID,以便立即知道你得到了一个故障节点,而不是在使用节点 10 小时后才发现。
云提供商通常有报告故障节点的机制。因此,除了丢弃故障节点外,报告故障节点对你自己和其他用户都有帮助。由于大多数用户只是丢弃故障节点,下一个用户会得到它们。我在某些情况下看到用户获得非常高比例的故障节点。
如何获取实际的 GPU 使用量
为了获取 GPU 的实际使用量,你可以尝试使用 Volatile GPU-Util 列在 nvidia-smi 输出中。
你想要测量的是 GPU 对可用容量的利用率,也称为“饱和度”。遗憾的是,这些信息并不由 nvidia-smi 提供。要获取这些信息,你需要安装 dcgm-exporter(https://github.com/NVIDIA/dcgm-exporter), 而这又需要一个较新的 Golang 和 DCGM(datacenter-gpu-manager),以及 root 权限。
请注意,这个工具仅适用于高端数据中心的 NVIDIA GPU,因此如果你使用的是消费级 GPU,则无法使用。
在安装了相关依赖项后,我构建了该工具:
git clone https://github.com/NVIDIA/dcgm-exporter.git
cd dcgm-exporter
make binary
然后,我能够使用这个 dcgm-exporter 配置文件获取文章中描述的“真实”利用率指标:
$ cat << EOT > dcp-metrics-custom.csv
DCGM_FI_PROF_SM_OCCUPANCY, gauge, The ratio of number of warps resident on an SM.
DCGM_FI_PROF_PIPE_TENSOR_ACTIVE, gauge, Ratio of cycles the tensor (HMMA) pipe is active.
DCGM_FI_PROF_PIPE_FP16_ACTIVE, gauge, Ratio of cycles the fp16 pipes are active.
DCGM_FI_PROF_PIPE_FP32_ACTIVE, gauge, Ratio of cycles the fp32 pipes are active.
EOT
然后,我启动了 daemon (root 是必要的):
$ sudo cmd/dcgm-exporter/dcgm-exporter -c 500 -f dcp-metrics-custom.csv
[...]
INFO[0000] Starting webserver
INFO[0000] Listening on address="[::]:9400"
-c 500 每 0.5 秒刷新一次
现在我可以通过以下命令来轮询它:
watch -n 0.5 "curl http://localhost:9400/metrics"
在一个控制台中运行它,并在另一个控制台中启动 GPU 工作负载。输出的最后一列是这些指标的利用率(其中 1.0 == 100%)。
来自存储库的 etc/dcp-metrics-included.csv 包含所有可用的指标,因此你可以添加更多指标。
这是一个快速的方法,但是目的是使用 Prometheus(https://prometheus.io/) ,它将为你提供漂亮的图表。例如,文章中包括了一个示例,其中你可以在图表的第二行中看到 SM 占用率、Tensor core、FP16 和 FP32 Core 利用率:
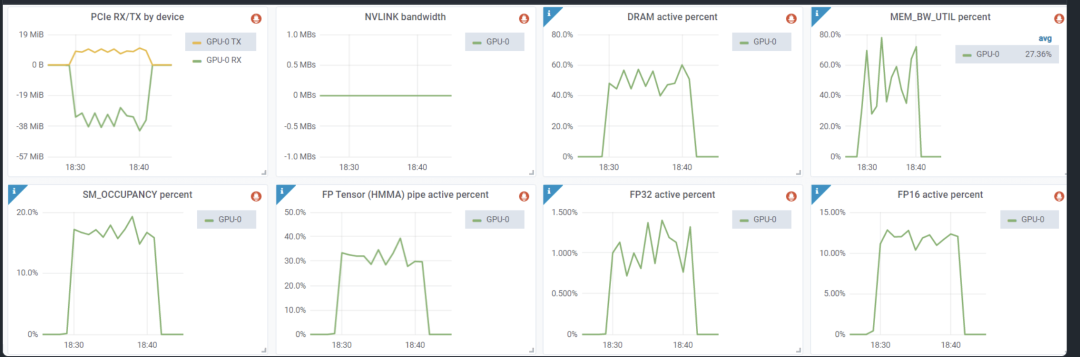
(来源(https://arthurchiao.art/blog/understanding-gpu-performance/))
为了完整起见,这里是来自同一篇文章的一个示例,显示了 100% 的 GPU 利用率,尽管一个 CUDA kernel实际上没有进行任何计算,只是占用了一个单一的流式多处理器(SM):
$ cat << EOT > 1_sm_kernel.cu
__global__ void simple_kernel() {
while (true) {}
}
int main() {
simple_kernel<<<1, 1>>>();
cudaDeviceSynchronize();
}
EOT
编译一下:
nvcc 1_sm_kernel.cu -o 1_sm_kernel
在窗口A运行:
$ ./1_sm_kernel
在窗口B:
$ nvidia-smi
Tue Oct 8 09:49:34 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.90.12 Driver Version: 550.90.12 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA A100 80GB PCIe Off | 00000000:01:00.0 Off | 0 |
| N/A 32C P0 69W / 300W | 437MiB / 81920MiB | 100% Default |
| | | Disabled |
你可以看到 100% 的 GPU 利用率。在这里,使用了 1 个 SM,而 A100-80GB PCIe 具有 132 个 SM!而且它甚至没有进行任何计算,只是在运行一个无限循环,不做任何事情。
(文:GiantPandaCV)