


DeepSeek 开源周的第三天,带来了专为 Hopper 架构 GPU 优化的矩阵乘法库 — DeepGEMM。这一库支持标准矩阵计算和混合专家模型(MoE)计算,为 DeepSeek-V3/R1 的训练和推理提供强大支持,在 Hopper GPU 上达到 1350+FP8 TFLOPS 的高性能。
DeepGEMM 的设计理念是简洁高效,核心代码仅约 300 行,同时在大多数矩阵尺寸下性能优于现有解决方案。该库支持三种数据排列方式:标准排列和两种专为混合专家模型设计的特殊排列(连续排列和掩码排列)。DeepGEMM 采用即时编译技术,不需要在安装时进行编译,代码结构清晰易懂,非常适合学习 GPU 优化技术。
01
性能表现
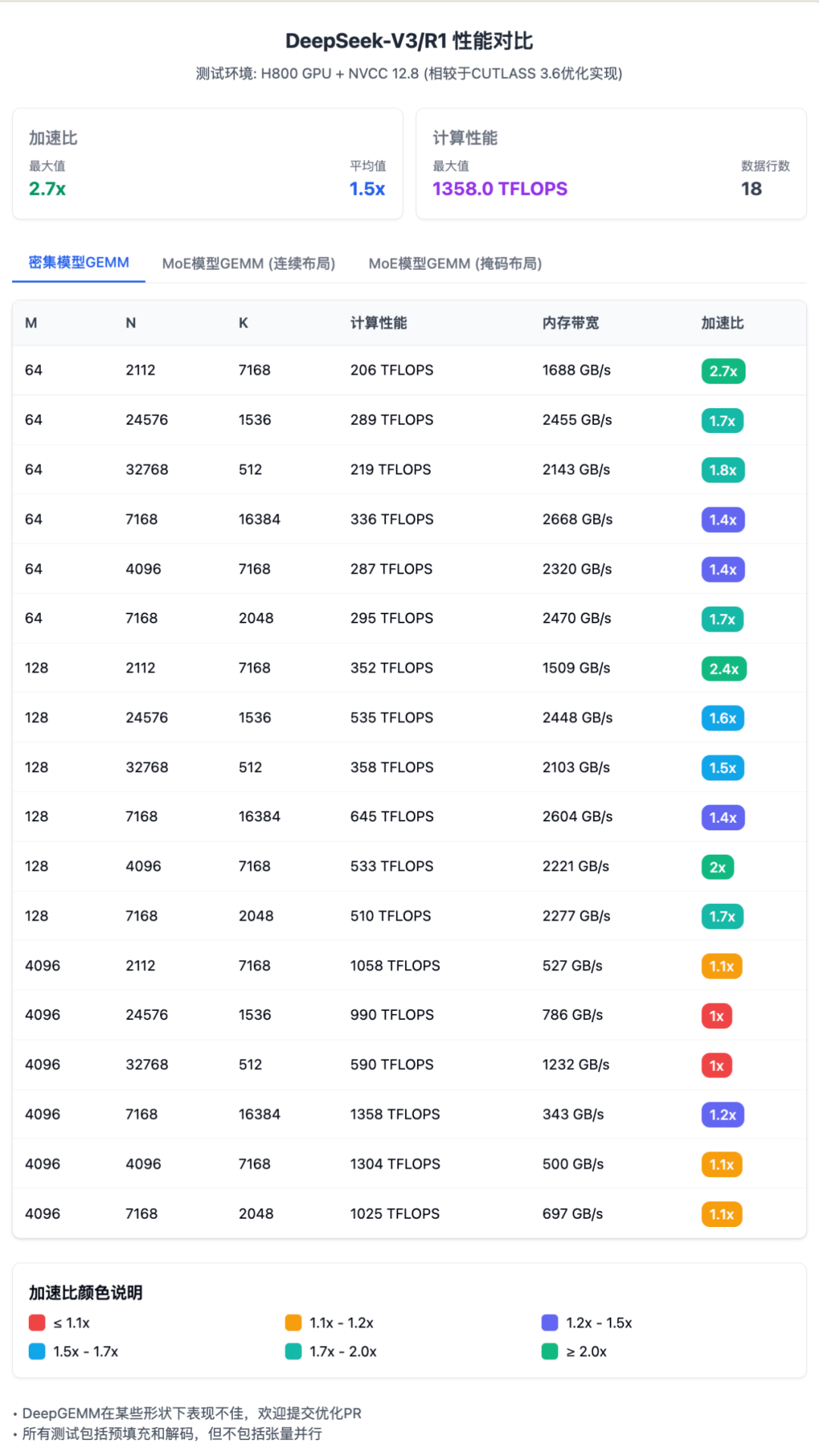
DeepGEMM 在各种计算场景下表现出色。 对于标准矩阵乘法,与基于 CUTLASS 3.6 的优化实现相比,速度提升 1.0 到 2.7 倍不等。小批量数据处理(M=64 或 128)获得了最显著的加速,最高达到 2.7 倍。
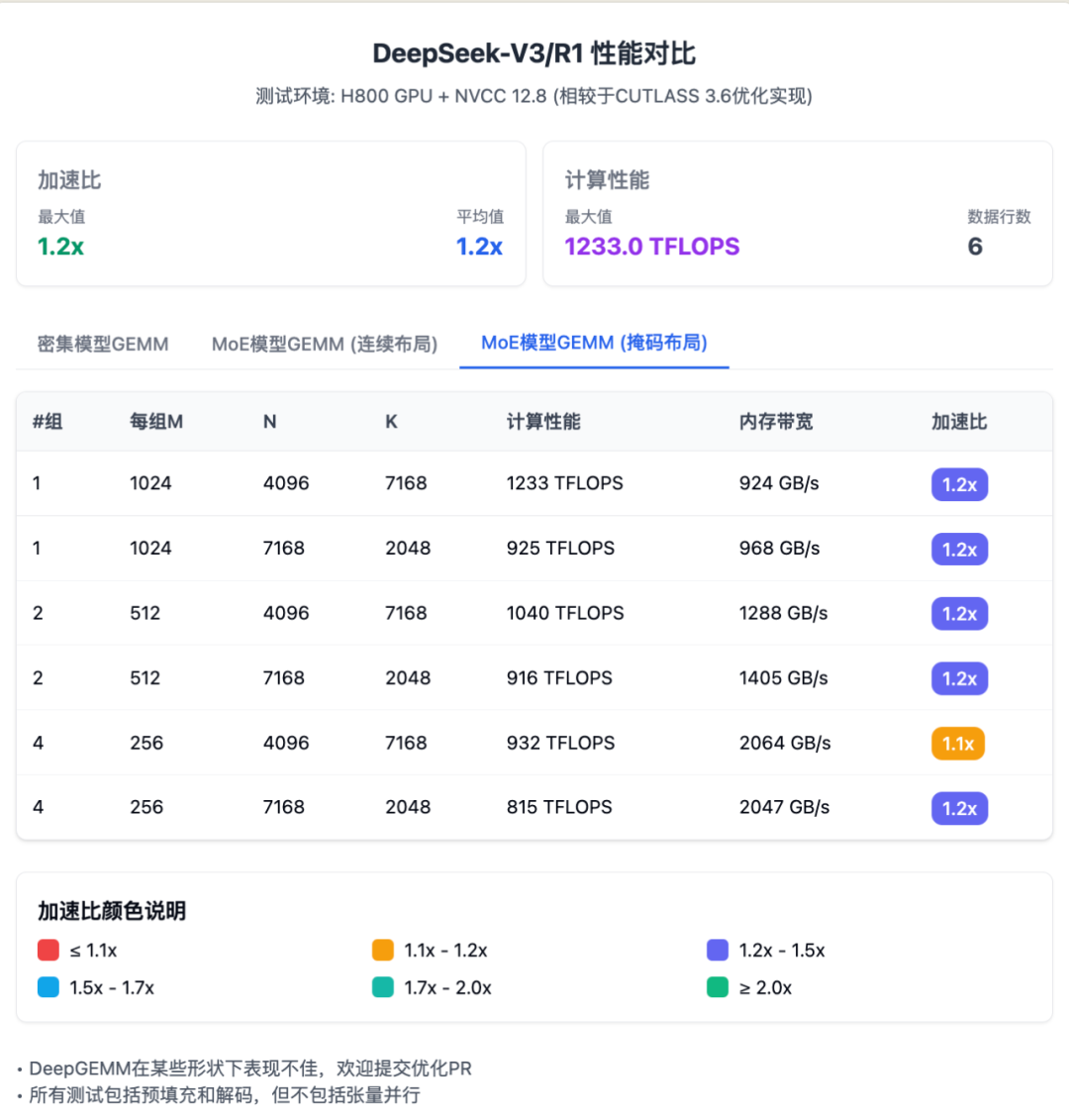
对于混合专家模型的计算,DeepGEMM 提供的两种特殊数据排列方式也有明显优势。 连续排列方式适用于训练和批量推理阶段,速度提升约 1.1 到 1.2 倍;掩码排列方式专为实时推理设计,支持与 CUDA 图技术配合使用,同样能提速 1.1 到 1.2 倍。
考虑到官方的数据不太易读,我给重新做了 3 张,请叫我赛博菩萨:

02
技术创新点
DeepGEMM 包含多项先进技术创新:
非标准块大小
统一调度系统
DeepGEMM 设计了一套统一的计算任务调度系统,采用特殊的排布策略,增强缓存重用效率,减少内存访问,提高整体性能。
03
一些技术点科普
什么是 FP8 和 GEMM?
在计算机中,数值需要用二进制位存储,存储方式决定了精度和所需空间。传统上,AI 计算使用 32 位浮点数(FP32),这提供了很高的精度,但占用较多存储空间和计算资源。
研究表明,很多 AI 任务实际上不需要这么高的精度。16 位浮点数(FP16)已被广泛采用,而 8 位浮点数(FP8)是更进一步的精度降低。虽然 FP8 精度较低,但对许多 AI 任务已经足够,同时能大大减少内存使用并提高计算速度。 这就像用较粗的刻度测量大物体,虽然精度降低,但速度快得多,且在大多数情况下已经足够准确。
GEMM(通用矩阵乘法)是深度学习中最基础也最常见的计算操作。简单来说,它计算两个数据表格(矩阵)相乘的结果。这看似简单,但在 AI 计算中,这些矩阵可能非常庞大,含有数百万个元素,使得矩阵乘法成为整个系统中最耗时的部分之一。几乎所有神经网络层的计算本质上都包含矩阵乘法操作。
DeepGEMM 专门优化了 FP8 精度的矩阵乘法,同时解决了 Hopper 架构在处理 FP8 计算时可能出现的精度问题,确保计算结果准确可靠。
标准矩阵乘法与混合专家模型计算
标准矩阵乘法处理的是完整矩阵之间的运算,适用于传统神经网络架构,所有数据都经过统一处理。
而混合专家模型(MoE)是一种特殊的神经网络架构,它包含多个”专家”网络和一个”门控”网络。 门控网络负责决定将输入数据分配给哪些专家处理,而不是所有数据都经过所有专家。这种方法允许模型规模大幅增长,同时保持计算效率,因为每次处理只激活部分模型而非全部。
针对 MoE 模型,DeepGEMM 提供了两种特殊数据排列方式:
-
• 连续排列:适用于训练和批量推理,将不同专家处理的数据连接成单一数据块 -
• 掩码排列:适用于实时推理,通过标记指示哪些数据需要处理,特别适合与 CUDA 图技术结合使用
Hopper GPU 与张量核心
NVIDIA 的 Hopper GPU 是专为人工智能和高性能计算设计的最新硬件平台,提供了多项关键技术改进:
张量核心是 GPU 内部的特殊计算单元,专门针对矩阵运算进行了优化,能大幅加速深度学习计算。Hopper 架构的张量核心支持 FP8 计算,比前代产品提供更高性能。
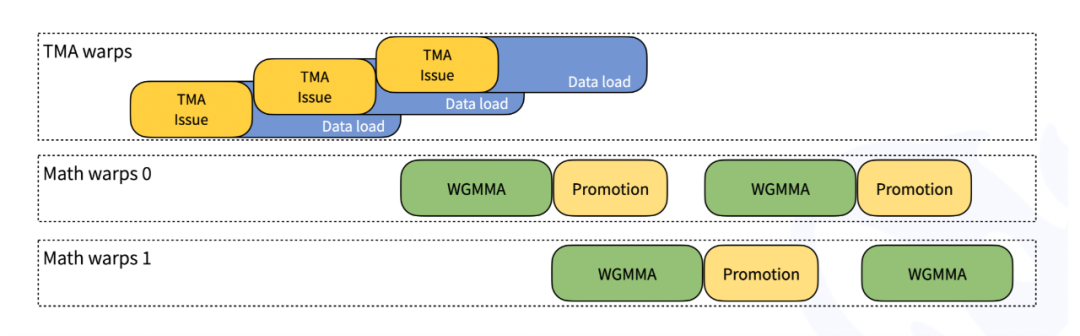
TMA(张量内存加速器)是 Hopper 架构引入的新功能,用于更快速、异步地移动数据。DeepGEMM 充分利用 TMA 技术加载和存储数据,并使用 TMA 多播和描述符预取等高级功能进一步提升性能。
即时编译技术
即时编译(Just-In-Time)是一种程序在运行时才进行编译的技术,而非传统的在安装或部署时预先编译。DeepGEMM 采用完全即时编译设计,所有计算内核都在实际运行时进行编译,这带来几个优势:
-
• 可以将矩阵形状、块大小等作为编译时常量处理,从而节省计算资源并允许更多编译优化 -
• 自动为当前任务选择最佳参数配置,而无需人工调整 -
• 完全展开计算流水线,让编译器有更多优化空间,特别有利于处理小规模矩阵
这种即时编译方法显著提高了小矩阵形状的计算性能,技术思路类似于 Triton 等现代编译器。
CUDA 与 CUTLASS
CUDA 是 NVIDIA 开发的并行计算平台和编程模型,允许开发者利用 GPU 强大的并行处理能力。这是编写 GPU 程序的基础工具。
CUTLASS 是 NVIDIA 的开源矩阵乘法库,提供了高性能的矩阵计算模板。DeepGEMM 借鉴了 CUTLASS 的一些思路,但没有直接依赖其复杂的模板系统,而是自行实现了一套更简洁的代码,既保证性能又易于理解和学习。
线程专业化技术
DeepGEMM 采用了线程专业化技术,这是一种高效的任务分工方法。在这种设计中,不同的计算线程被分配专门负责特定任务:一些负责数据移动,一些负责核心计算,一些负责结果处理。
这种分工使得数据移动、计算和后处理能够同时进行,形成高效的流水线,大大提高整体性能。
04
使用 DeepGEMM
使用 DeepGEMM 需要支持 sm_90a 的 Hopper 架构 GPU、Python 3.8 以上、CUDA 12.3 以上(推荐 12.8 以上获得最佳性能)、PyTorch 2.1 以上以及 CUTLASS 3.6 以上。
Development
# Submodule must be cloned
git clone --recursive git@github.com:deepseek-ai/DeepGEMM.git
# Make symbolic links for third-party (CUTLASS and CuTe) include directories
python setup.py develop
# Test JIT compilation
python tests/test_jit.py
# Test all GEMM implements (normal, contiguous-grouped and masked-grouped)
python tests/test_core.pyInstallation
python setup.py install最后, import deep_gemm 就行了
DeepGEMM 提供了清晰的 Python 编程接口,包括:
-
• 标准矩阵乘法函数:用于普通神经网络计算 -
• 连续排列分组函数:用于混合专家模型训练和批量推理 -
• 掩码排列分组函数:用于混合专家模型实时推理
同时,库提供多个实用工具函数,用于设置计算资源和数据格式,让开发者能根据具体需求进行配置。
05
回顾与展望
DeepGEMM 作为 DeepSeek 开源周的第三日发布,为 Hopper 架构 GPU 提供了高效的 FP8 矩阵乘法实现。 通过精心设计的 300 行核心代码,这个库在多种场景下超越了现有解决方案,为普通神经网络和混合专家模型提供了强大的计算基础。
同时,其清晰的代码,也堪称是学习 GPU 优化技术的优质资源。
目前,DeepGEMM 专门针对 Hopper 架构 GPU 优化,未来可能扩展到更多硬件平台。

-
高浓度的主流模型(如 DeepSeek 等)开发交流; -
资源对接,与 API、云厂商、模型厂商直接交流反馈的机会; -
好用、有趣的产品/案例,Founder Park 会主动做宣传。
(文:Founder Park)