

极市导读
本文介绍了港科大和地平线联合提出的DrivingWorld模型,该模型基于视频GPT构建,能够实现自动驾驶场景的可控生成和长时序生成,通过创新的空间-时间解耦机制和高效的编码解码模块,显著提升了视频生成的质量和长度,为自动驾驶技术的发展提供了新的支持。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
DrivingWorld的主要作者是来自香港科技大学和地平线公司的研究团队,他们专注于世界模型和自动驾驶技术的研究,力求在这两个领域做出更多的贡献。

论文地址:https://arxiv.org/abs/2412.19505
代码地址:https://github.com/YvanYin/DrivingWorld
1. 背景介绍:
世界模型(World Model) 是一种可以模拟世界动态的模型,能够基于过去的观测实现对未来状态的预测,因此被视为实现AGI的关键途径。世界模型在自动驾驶领域展现了巨大的潜力,不仅具备对环境和驾驶状态的深刻理解,还为未来轨迹预测与自动驾驶决策提供了重要支持。然而,要通过World Model实现高逼真度的驾驶场景生成并非易事。香港科技大学与地平线联合推出的基于自回归架构的DrivingWorld模型,为构建精准的自动驾驶世界模型带来了全新突破。
2. 为什么世界模型要采用自回归模型?
同样是输出未来的视频,为什么不采用扩散生成模型(Diffusion Model),而是采用自回归模型?为了回答这个问题,小编向GPT-4o询问了这个问题。
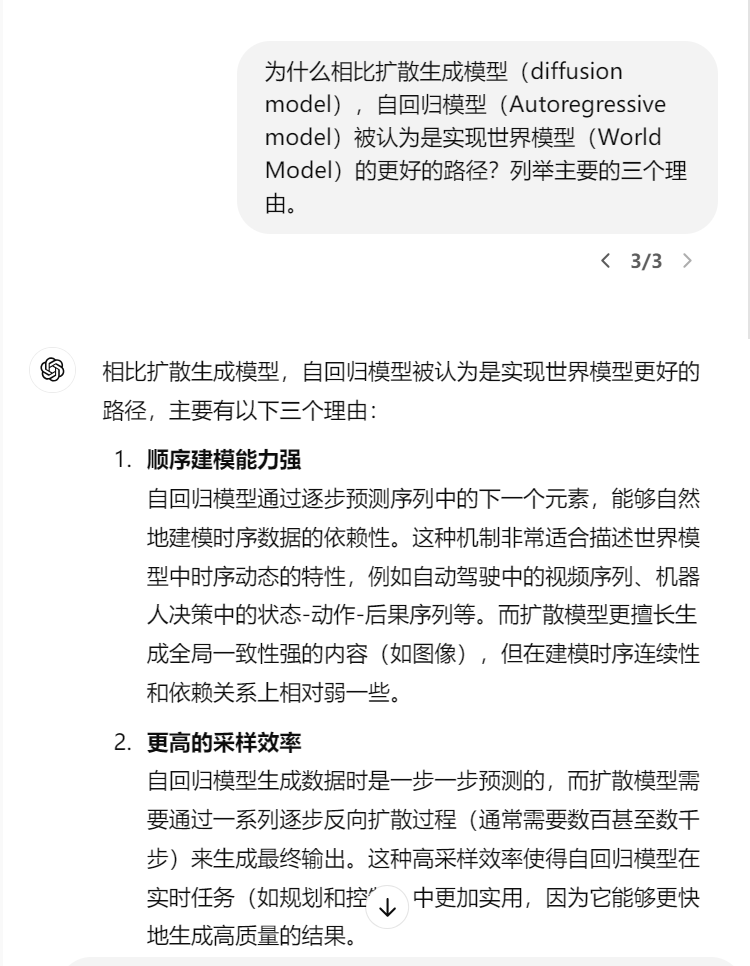

3. 如何实现这一步呢?
美国知名公司Wayve率先展示了针对自动驾驶的世界模型GAIA-1。该模型采用了自回归路线,但是由于其采用的传统GPT框架缺乏空间与时间动态建模能力,其生成视频质量与时间都有很大提升空间。
为解决这个问题,DrivingWorld创新性地引入空间-时间先解耦后融合的机制,提出了一种基于Next-State自回归式框架的方法,用于实现超长时序视频预测和可控的视频生成。尽管相关领域已有一些研究,但是DrivingWorld在视频生成长度方面仍然取得了明显突破。
-
高效的视频可量化的编码和解码模块:首次提出视频可量化编码解码器,相比于单张图压缩方案,在降低视频抖动和提升连续性方面取得了明显改进,FID指标上相对于SOTA提升了17%; -
解耦时序信息和多模态信息实现可控预测和超长时序预测:DrivingWorld能够生成未来>40s的video,相较于当前的SOTA方法(最长15s)在时序长度上有了显著提升; -
高效的自回归模型设计以实现并行化预测:DrivingWorld采用了空间-时间先解耦后融合的设计,采用next-state prediction的自回归策略,有效降低了token预测的时间复杂度,在复杂视频生成任务中展现了良好的性能表现。
4. 实验结果:
4.1 长时序生成
以下展示了一个长时序视频生成的示例。DrivingWorld在不同帧之间能够捕捉到连贯的3D场景结构。

4.2 解决Drift问题
在生成长序列时,模型经常会因为误差积累导致显著的drift问题。DrivingWorld引入了一种有效的mask token策略,可以缓解drift的影响,从而提升生成质量。

4.3 生成质量评估
DrivingWorld与现有的SOTA方法在NuScenes验证集上进行了性能比较。其中,蓝色表示 NuScenes数据被包含在模型的训练集中,橙色则代表zero-shot测试结果。“w/o P”指未使用私有数据进行训练的情况。具体对比结果如下:

从结果可以看出,DrivingWorld 模型不仅能够生成更长的视频序列(最长达40s / 400帧),同时在FID和FVD上也展现出了较强的竞争力。
4.4 更多Demos展示
4.4.1 可控生成
4.4.2 长时序生成demo
5. 未来工作:
展望未来,DrivingWorld 还有很大的发展潜力。DrivingWorld 的研究团队计划进一步融入更多模态信息,如车辆传感器数据、地图信息等,并整合多视图输入,如不同角度的摄像头画面。通过全方位融合多模态和多视角数据,有望进一步提升模型在复杂驾驶环境下的理解能力、动作控制精度以及视频生成的准确性,从而推动自动驾驶系统整体性能和可靠性迈向新的高度,为自动驾驶技术的广泛应用奠定坚实基础。

(文:极市干货)