

极市导读
重新思考了 3×3 卷积这种最简单但是最快的模块,来实现基于纯卷积的扩散模型。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文目录
1 DiC:重新思考扩散模型中的 3×3 卷积
(来自北大,北京华为诺亚方舟实验室)
1 DiC 论文解读
1.1 DiC 研究背景
1.2 使用 3×3 卷积作为模型基本组成
1.3 架构探索:使用 Encoder-Decoder Hourglass 架构
1.4 Conditioning 方面的改进
1.5 实验设置
1.6 实验结果
1.7 缩放性能
太长不看版
纯卷积实现且用于图像生成扩散模型。
最近的一些工作把扩散模型从传统的 U 型的 CNN-Attention 的混合结构转变为完全基于 Transformer 的架构。虽然这些模型表现出了很强的扩散性和强大的性能,但是其复杂的 Self-Attention 操作会导致推理速度变慢。
本文重新思考了 3×3 卷积这种最简单但是最快的模块,来实现基于纯卷积的扩散模型。
具体而言,作者发现 Encoder-Decoder Hourglass 的设计优于 Isotropic 的架构,但仍然表现不佳,低于原来的预期。作者引入了 Sparse Skip Connection 来减少冗余并提高模型的可扩展性。基于这个架构,本文进一步提出 Stage-Specific Embeddings,Mid-Block Condition Injection, 和 Conditional Gating 的技术,得到最终的 Diffusion CNN (DiC)。实验表明,DiC 在性能方面大大超过了现有的 Diffusion Transformer,同时保持了良好的速度优势。
1 DiC:重新思考扩散模型中的 3×3 卷积
论文名称:DiC: Rethinking Conv3x3 Designs in Diffusion Models
论文地址:
http:///arxiv.org/pdf/2501.00603
项目主页:
http://github.com/YuchuanTian/DiC
1.1 DiC 研究背景
Self-Attention 机制在最近的许多扩散模型中起重要的作用。早期的扩散模型的工作[1]将卷积 U-Net 结构与 Self-Attention 融合。U-ViT[2]和 DiT[3]等架构完全过渡到基于 Self-Attention 的设计,完全放弃了卷积 U-Net。这些模型展示了显著的生成能力,尤其是在扩大规模的时候。
较新的文生图或者文生视频模型,包括 Stable Diffusion 3[4]、FLUX[5]、PixArt[6]和 OpenSora[7],也采用了完全基于 Transformer 架构,实现了很高的生成质量。
不幸的是,在扩大规模时,结合 Self-Attention 的扩散模型面临着显着的计算开销和延迟。复杂的 Transformer 架构对实时、资源受限的应用程序造成了很大的挑战,其中大规模 Transformer 模型由于巨大的时间成本而变得不切实际。
所以很多工作会加速扩散模型中的 Self-Attention,比如 PixArt-Σ[6]实现了高效的 Self-Attention 机制。但是,这种方法仍局限于 Self-Attention 的范式。生成图片的速度仍然有提升的空间,未能满足实时或大规模应用的需求。
在这项工作中,本文重新思考了简单有效的完全基于卷积的扩散模型,该架构提供了显著的速度优势。而卷积作为 Self-Attention 的对应,被认为硬件友好,在各种平台上都有很好的支持。在众多的卷积操作中,规范的 3×3 Stride1 卷积因其卓越的速度而脱颖而出,这主要是由于 Winograd 加速[8]等广泛的硬件优化技术。例如,RepVGG[9]等工作已经证明了简单的卷积如何实现高效率和具有竞争力的性能。
但是,3×3 卷积有它固有的局限性,尤其是感受野受约束,可能会阻碍其在复杂生成任务中的可扩展性。作者首先进行了一些初始的实验,在现有的架构上面扩展基于 3×3 卷积的 CNN,但是发现这样得到的结果仍然不如对应的 Diffusion Transformer。
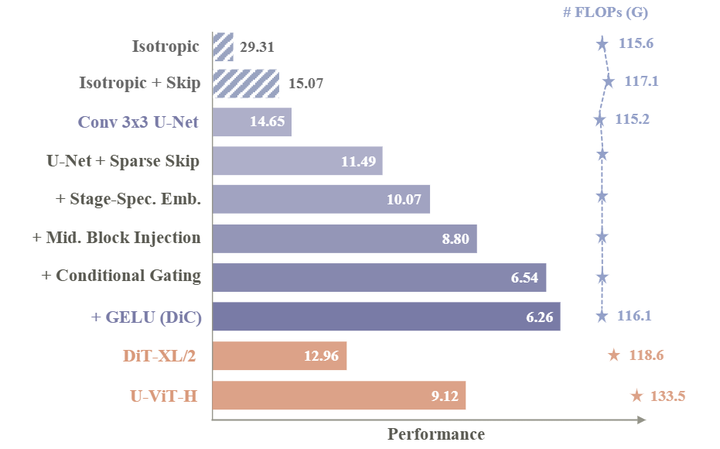
为了解决这个问题,作者对传统的 ConvNets 进行了一系列适配,专门为了缩放扩散模型进行了一系列定制化设计,形成了图 1 所示的 Roadmap。首先,作者专注于改进模型架构以更好地利用 3×3 卷积。现有的设计分为 3 类:Isotropic 架构,如 DiT;具有 skip connection 的 Isotropic 架构,如 U-ViT;以及 CNN 和 Self-Attention 混合模型中使用的 Encoder-Decoder Hourglass 结构。实验结果表明,Hourglass 结构对纯 3×3 卷积模型更有效,因为编码器的下采样和上采样扩大了感受野,弥补了 3×3 卷积感受野窄的问题。Skip connection 也至关重要,但作者认为传统的 Skip connection 的做法过于密集,无法对大 ConvNet 有效。为了解决这个问题,作者引入了 Sparse Skip Connection,减少了 skip 的数量,同时确保基本信息流从 Encoder 有效流向 Decoder。
除此之外,作者专注于改进 Condition,以更好地拟合 ConvNet。在现有模型中,一组 Condition Embedding 通常映射到不同阶段的不同 Block。然而,在 Encoder-Decoder ConvNets 中,每个 Stage 在不同的特征空间中运行。因此,作者引入了 Stage-Specific Embedding,确保每个 Stage 使用独立的、不重叠的 Condition Embedding 表示。作者还仔细检查了 Condition 注入的位置,建议在中间的 Block 中注入 Condition 以获得更好的性能。此外,作者对内部块结构进行了改进,将所有激活函数替换为 GELU。
通过上面的改进最终得到了 DiC,一种由 Conv3×3 组成的扩散模型,以上的改进使之能够在保持速度优势的同时取得出色的结果。
1.2 使用 3×3 卷积作为模型基本组成
作者选择正常的 Stride-1 full 3×3 卷积作为模型的主要成分。Stride-1 3×3 卷积的速度令人难以置信,主要是由于现代深度学习框架中广泛的硬件和算法优化。操作优化受益于 Winograd 算法[8],将常见卷积操作所需的乘法次数减少了 5/9 。对于 3×3 卷积核,该方法通过利用有效的矩阵变换显着加快了计算速度。
而且,与 Depthwise 卷积不同,3×3 卷积实现了高度的计算并行性,允许现代 GPU 充分利用它们的处理能力。这种并行性与最小的显存访问开销相结合,使得 stride-1 3×3 卷积特别有效。与更大或更复杂的卷积操作相比,3×3 卷积在计算成本和表征能力之间提供了理想的权衡,使其成为实时应用和大规模模型的实用选择。
1.3 架构探索:使用 Encoder-Decoder Hourglass 架构
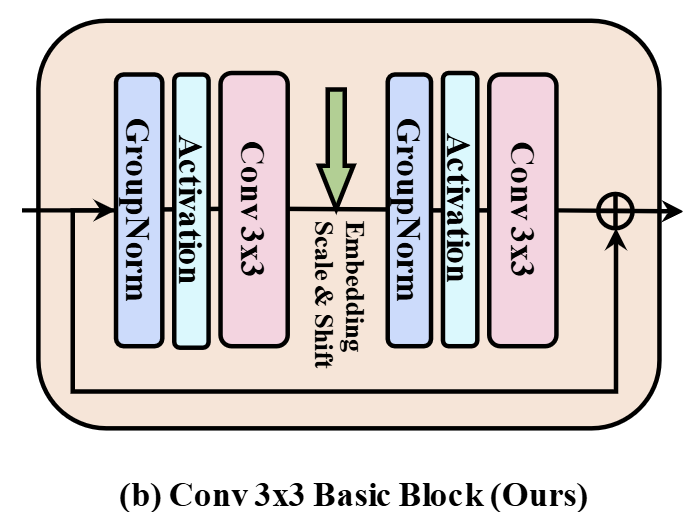
已有的工作[10]也有基于 3×3 卷积的扩散模型。但是,这些模型并非是完全基于 CNN 的:模型中的 Basic Block 由两个连续的 3×3 卷积组成,然后是关注整个图像的 Self-Attention 模块。在每个卷积之前,使用 GroupNorm 对输入进行归一化,然后传递给 SiLU 的非线性激活函数。整体采用残差结构。
本文提出的 DiC 的 Roadmap 从上面提到的 Basic Block 开始。为了满足路线图的最终目标,作者在卷积后去除Self-Attention 层,形成一个由 2 个 3×3 卷积组成的 Basic Block,其他块设计暂时保持不变,如图 2 所示。
目前,基于 3×3 卷积实现的有 3 种主流的架构,分别是:
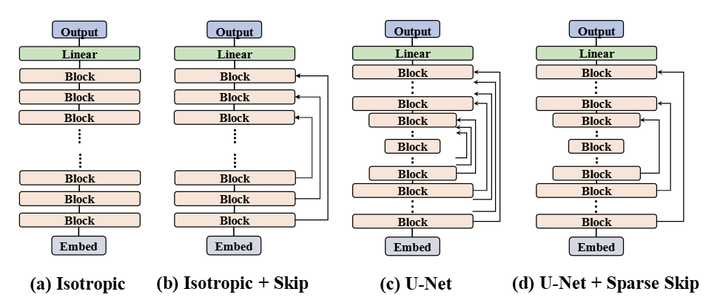
Isotropic 架构 (以 DiT 为代表): 简单、垂直堆叠。Patchify 之后,整个模型中不会改变中间特征图的大小。它因其公认的可扩展性而被广泛采用。
具有 Skip Connection 的 Isotropic 架构 (以 U-ViT 为代表): 通过引入非相邻层之间的长跳跃连接。与传统的U-Net不同,尽管使用 Skip Connection,但该结构在整个网络中保持了一致的空间分辨率,避免了任何上采样或者下采样操作。
U-Net Hourglass 架构 (以 ADM 为代表): 这个经典的设计[11]由一个编码器和一个解码器组成,形成一个 Hourglass 的形状。Encoder 逐步对特征维度进行下采样,而 Decoder 对称地对空间维度进行上采样。除了 Hourglass 主干之外,Encoder 中的每个 Block 都通过 Skip Connection 连接到其对应的 Decoder Block。
实验分析
使用基本的 Conv 3×3 Basic Block,作者对上述架构选择进行了实验,结果总结在图 4 中。这些实验揭示了几种模式,为设计有效的基于 3×3 卷积的扩散模型提供了有价值的见解。
首先,对于仅由 3×3 卷积组成的扩散模型,Encoder-Decoder Hourglass 架构是必不可少的。这可能由于 3×3 卷积受限的感受野。在 Isotropic 的标准 Transformer 架构的设置中,每个 3×3 卷积在每个方向上仅扩展一个像素的感受野。因此,实现全局感受野将需要深度的卷积堆叠,导致计算和参数效率低下。
相比之下,Encoder-Decoder 架构显著地降低了这个限制。通过 Decoder 中的上采样和 Encoder 中的下采样操作,较高 stage 的 3×3 卷积可以有效地感知较大区域,大大增加了模型的感受野。这种分层方法允许模型有效地捕获本地和全局上下文,这使得它对生成任务更有效。
而且,Skip Connection 在基于 Conv 3×3 的架构中至关重要。一方面,在 Encoder-Decoder 结构中,它们通过将特征图直接传递给 Decoder 来减轻下采样过程中的信息损失,丰富了其表示。另一方面,Skip Connection 通过提供额外的梯度路径并保留重要特征来加速训练并提高生成质量,从而实现更高效和有效的扩散建模。
但是,缩放基于 Conv 3×3 的扩散模型需要堆叠很多层,使得密集的 Skip Connection 成为瓶颈。因为 Skip Connection 的特征需要在 channel 维度拼接起来,这样会消耗过多的计算成本。这样的低效率的做法阻碍了模型的可扩展性。为了解决这个问题,本文提出跨步 Skip Connection,其中 Skip Connection 每隔几个块用一下,而不是所有的块都使用。
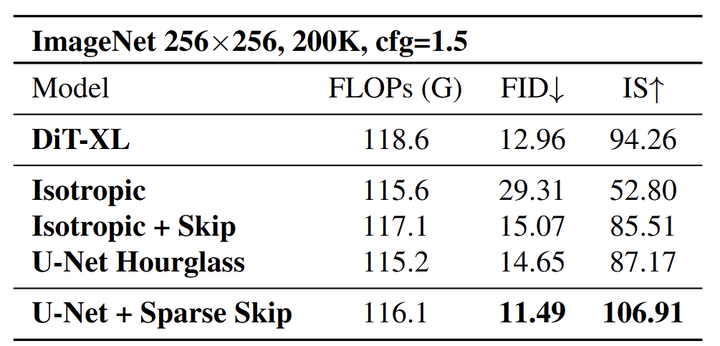
如图 4 所示,实验结果表明,与密集连接的跳过设计相比,稀疏 Skip Connection 得到了更好的结果。
1.4 Conditioning 方面的改进
作者认为模型缩放知乎,Conditioning 方面也需要进一步改进。
Stage-Specific Embedding
在传统扩散模型中,以前的模型共享一个唯一的 Embedding。Conv3×3 模型依靠 Encoder-Decoder 结构来扩展感受野。Encoder-Decoder 结构的每个 stage 都使用不同的 channel 进行操作,反映了 stage 之间显著的结构和功能差异。鉴于特征维度因 stage 而异,在不同阶段的所有块上均匀地应用相同的 Condition Embedding 可能不是理想的。单个 Embedding 可能无法充分捕获每个 stage 的不同特征,因此对不同 stage 定制 Condition Embedding 可能更有效。
作者提出使用 Stage-Specific 的 Condition Embedding,对每个 stage 使用不一样的 Embedding,Embedding 的维度与这个 stage 的特征维度对齐。值得一提的是,作者分析了 Stage-Specific 的 Embedding 引入的开销。结果显示增加的开销很小。只会令模型大小增加了 14.06M 参数,仅占总模型大小的 2%。引入的计算开销仅增加了 12M FLOPs,对整体计算效率的影响很小。
Condition 注入的位置
另一个重要的点是确定注入 Condition 信息的最佳位置。扩散模型中有两种流行的条件注入策略。第一种方法在每个 Block 的一开始就注入条件,通常通过 LayerNorm,如 DiT 等模型。第二种方法在 Block 中间引入条件,如 ADM。
通过实验,作者发现对于全卷积扩散架构,将条件注入每个 Block 内的第 2 个卷积层会产生最佳性能。此放置有效地调制特征表示,在不影响其效率的情况下增强模型的生成质量。
Conditional Gating
作者还采用了 DiT 的 AdaLN 的条件门控机制。AdaLN 引入了一个门控向量,该向量沿通道维度扩展特征,为调节过程提供更动态和更细粒度的控制。这种改进增强了模型适应不同条件的能力,提高了整体生成质量。本文的实验表明,这种增强产生了显着的性能提升,进一步证明了这种调节策略在扩散模型中的有效性。
其他小改动
作者重新审视整个模型中的激活函数。受 ConvNeXt 的启发,将常用的 SiLU 激活替换为 GELU。这种变化也改进了性能。
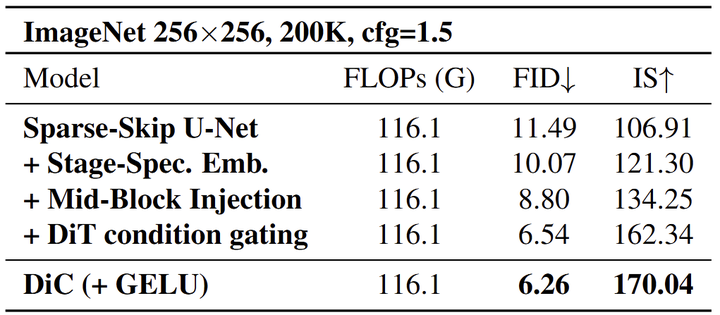
1.5 实验设置
为了针对现有的 DiT 模型进行基准测试,我们设计了我们不同尺度的架构:Small (S)、Big (B) 和 Extra Large (XL),它在 FLOP 和参数计数方面与 DiT-S/2、DiT-B/2 和 DiT-XL/2 对齐,如图 6 所示。此外,作者引入了一个更大的模型 Huge (H),用于缩放性能的评估。DiC-S 提供了一种轻量级的解决方案,使用 32.8M 参数和 5.9G FLOPs,类似于 DiT-S/2,具有高效的 Encoder-Decoder 配置。DiC-H 旨在评估 DiC 模型的潜力。
除了正常的 FLOPs 计算外,作者还记录了考虑了 Winograd 之后的实际 FLOPs。Winograd 可以将 Stride-1 3×3 卷积的计算减少 5/9。可以观察到 Winograd 可以将所提出的 DiC 的理论 FLOPs 减少大约一半。

在实验中使用 256 的 global batch size,学习率为 1e-4,weight decay 为 0。
1.6 实验结果
如图 7 所示,DiC 模型在所有测试尺度上都优于相应的 DiT 模型。具体来说,DiC-S 的 FID 显着降低,从 67.40 下降到 58.68,同时在 IS 上也优于 DiT-S/2,从 20.44 增加到 25.82。同样,DiC-B 的性能明显优于 DiT-B/2,FID 从 42.84 降低到 32.33,并将 IS 从 33.66 增加到 48.72。
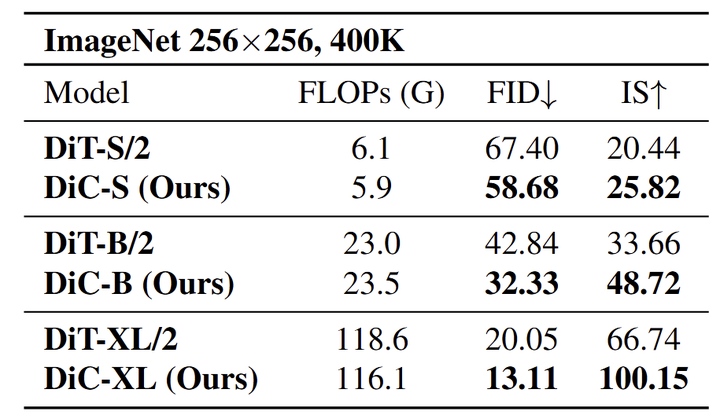
在大模型中,DiC-XL 比 DiT-XL/2 提供了显著的改进,FID 从 20.05 下降到 13.11,IS 从 66.74 下降到 11.15。这些结果突出了我们的 DiC 模型的有效性,它在图像质量和多样性方面都始终取得卓越的性能,同时保持计算效率。
与 Diffusion Transformer 的比较
由于不同的模型使用不同的设置,包括训练超参数、采样器选择、训练迭代次数等,作者根据 U-DiT[12]采用普遍对齐的设置 (DiT 代码库上的 400K 次迭代)。如图 8 所示,DiC 模型在 ImageNet 256×256 上始终优于基线扩散架构。
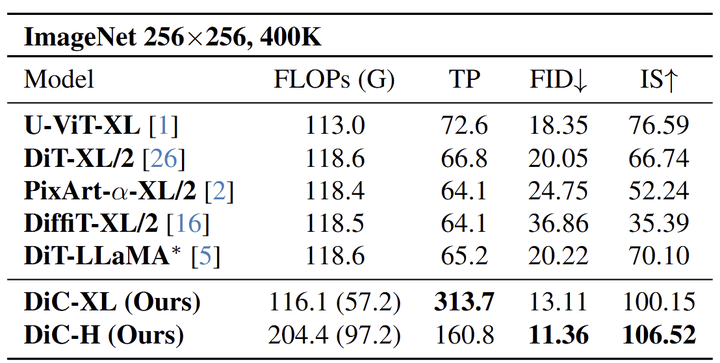
除了性能之外,DiC 的速度很快。尽管扩散模型的计算量很大,但 DiC-XL 的吞吐量为 313.7,反映了 Conv3×3 高度优化的操作的使用。这种架构利用了卷积的固有速度特点,在效率和质量之间提供了很好的平衡。
DiC-H 在模型大小和速度之间取得了显着的权衡,将最先进的 FID 为 11.36,IS 为 106.52,吞吐量提高了 160.8。实际应用中,这些速度优势使 DiC 成为高质量图像合成的实用解决方案。
此外,作者在图 9 中试验了 DiC 模型的条件生成能力。DiC-XL 仅在 400K 次迭代时实现了 3.89 的 FID,大大超过了具有竞争力的 Diffusion Transformer 基线,结果来自具有 cfg=1.5 的条件生成样本。
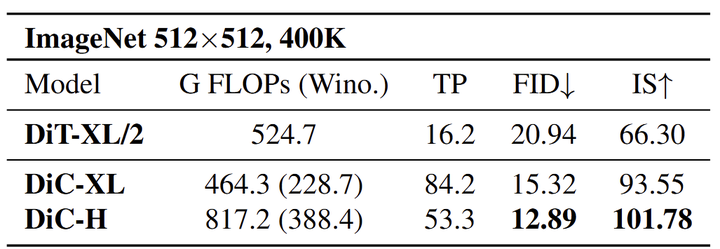
图 10 报告了 DiC 模型与 DiT 在 ImageNet 512×512 上的比较结果。关键结论是 DiC 模型的计算效率。DiT-XL/2 需要 524.7G FLOPs (使用 Winograd 优化),DiC-XL 模型在 FID 和 IS 方面表现明显更好,只有 464.3G FLOPs (Winograd 优化后 228.7G)。在 DiC-H 中,改进变得更加明显,显著降低了 FID (12.89),并实现了比 DiT-XL/2 更少的 FLOPs 和更高的 IS (101.78)。
DiC 和 DiT 计算复杂度的关键区别在于它们的底层架构。DiC 使用纯卷积方法,随图像大小线性缩放。相比之下,DiT 采用 Self-Attention,会导致图像大小的二次复杂度。因此,对于较大的图像,例如 512×512,DiC 和 DiT 之间的计算差距变得更加明显。尽管如此,令人惊讶的是,DiC 模型仍然可以与 DiT 保持良好的差距。另一方面,DiC 的优势在吞吐量方面也表现出色。
1.7 缩放性能
图 11 展示了随着训练的进行,DiC-H 在 ImageNet 256×256 上的性能。随着训练的进行,DiC-H 的性能稳步提高。在 600K 步时,FID 下降到 9.73,在 7M 训练步骤中匹配 DiT-XL/2 的性能;在 800K 步,DiC-H 显示出最佳性能,FID 为 8.96。该表展示了 DiC-H 的快速收敛,其中 FID 和 IS 都随着训练的进行不断改进。
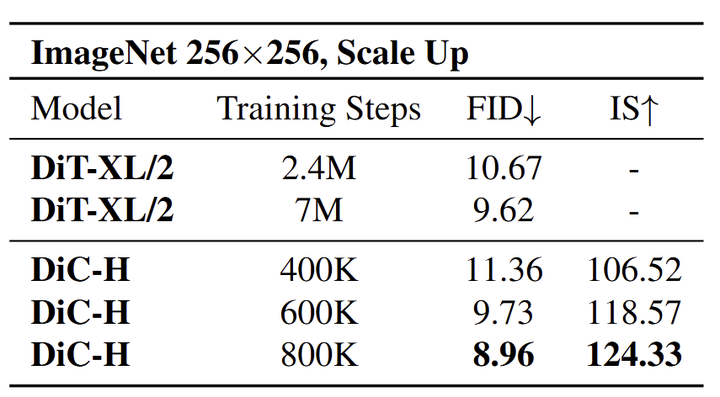
图 12 展示了各种模型在 ImageNet 256×256 上的性能的比较,因为训练迭代被扩大。提出的关键指标是吞吐量 (TP)、Batch Size × Iteration (BS×Iter) 和 FID (Fréchet Inception Distance),这是生成模型质量的常用度量。
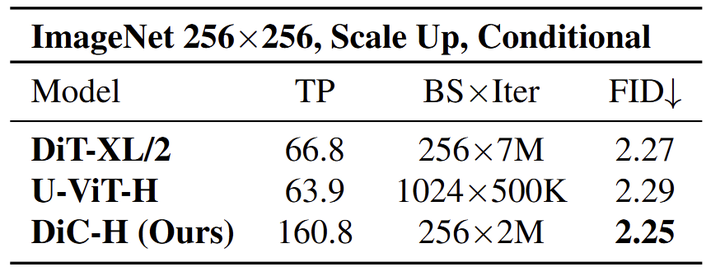
基线模型 DiT-XL/2 的吞吐量为 66.8,得到 2.27 的 FID 分数。U-ViT-H 模型虽然吞吐量略低 63.9,但 FID 略高达到了 2.29。相比之下,DiC-H 模型使用 256 的 Batch Size,训练 2M 次,性能显示出了显著的改进。DiC-H 可以达到 2.25 的 FID,吞吐量为 160.8。这些结果表明 CNN 可以达到不比 Diffusion Transformer 差的性能。
参考
-
^Denoising Diffusion Probabilistic Models -
^All are Worth Words: A ViT Backbone for Diffusion Models -
^Scalable Diffusion Models with Transformers -
^Scaling Rectified Flow Transformers for High-Resolution Image Synthesis -
^Black Forest Labs. Flux, 2024 -
^abPixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation -
^Open-sora: Democratizing efficient video production for all -
^abFast Algorithms for Convolutional Neural Networks -
^RepVGG: Making VGG-style ConvNets Great Again -
^Diffusion Models Beat GANs on Image Synthesis -
^U-net: Convolutional networks for biomedical image segmentation -
^U-dits: Downsample tokens in u-shaped diffusion transformers
(文:极市干货)