
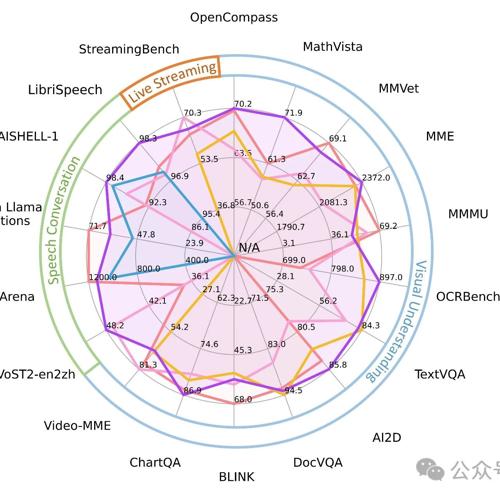
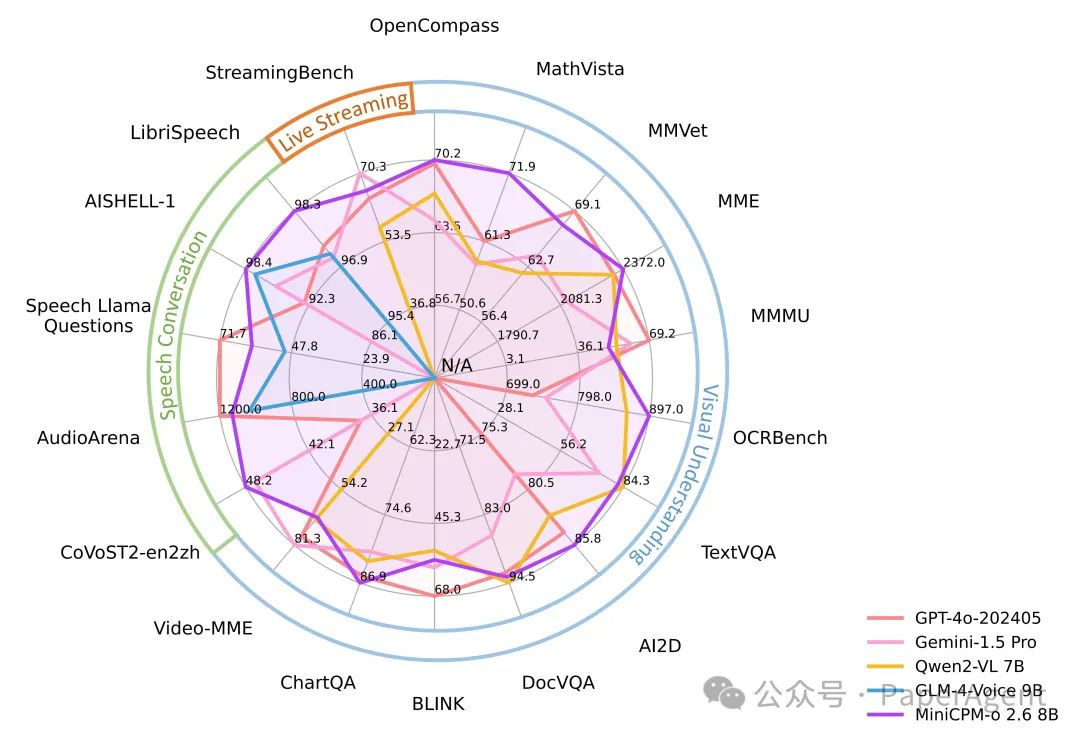
模型架构
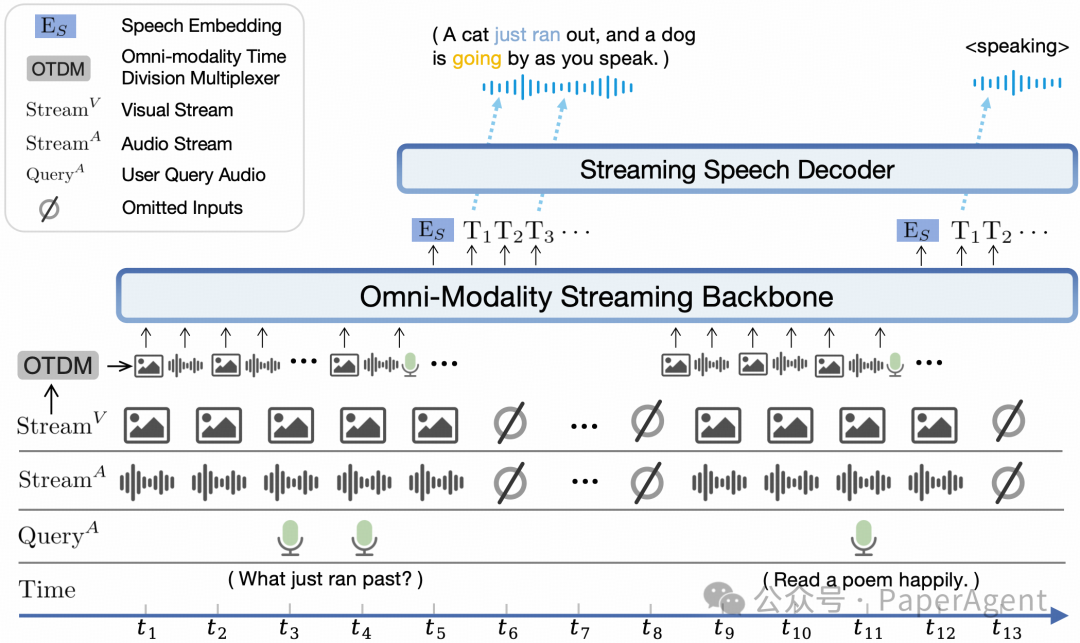
-
端到端全模态架构。 通过端到端的方式连接和训练不同模态的编/解码模块以充分利用丰富的多模态知识。
-
全模态流式机制。 (1) 我们将不同模态的离线编/解码器改造为适用于流式输入/输出的在线模块。(2) 我们针对大语言模型基座设计了时分复用的全模态流式信息处理机制,将平行的不同模态的信息流拆分重组为周期性时间片序列。
-
可配置的声音方案。 我们设计了新的多模态系统提示,包含传统文本系统提示词,和用于指定模型声音的语音系统提示词。模型可在推理时灵活地通过文字或语音样例控制声音风格,并支持端到端声音克隆和音色创建等高级能力。



https://github.com/OpenBMB/MiniCPM-o/tree/main
(文:PaperAgent)