近年来,机器人操控作为机器人学习领域的重要研究方向,受到广泛关注。
随着深度学习等相关技术的快速发展,机器人操控能力已实现了从传统的抓取、放置等简单任务向更加复杂、精细操作的拓展。然而,当前大多数研究的重点仍主要集中在机器人末端执行器(相当于人类的手部)与环境之间的交互上。
那么,机器人能否有效利用手臂的其他部位(除手部之外)来完成诸如抓取、支撑等需要精确关节级控制以调整机器人整体姿态的任务呢?
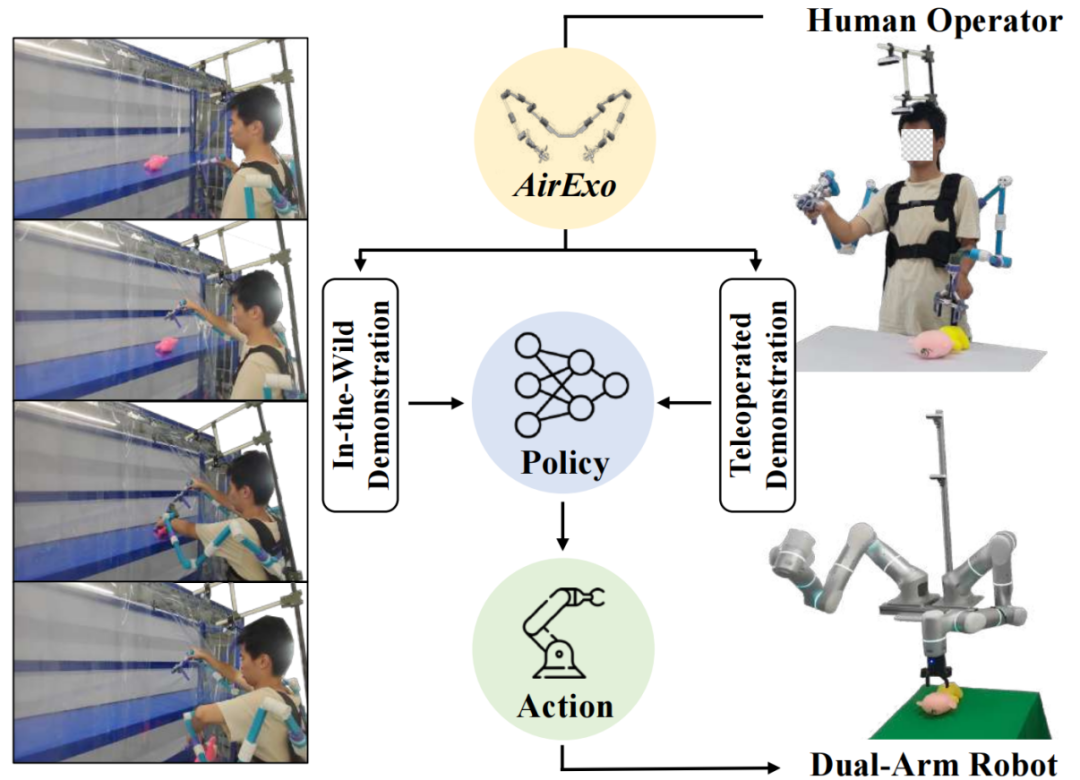
针对这一问题,穹彻智能与上海交通大学卢策吾团队展开合作,共同开发出了一种低成本、高适应性且便于携带的双臂外骨骼系统——AirExo。该系统不仅能为双臂机器人提供精确的关节级遥操作支持,并用于遥操作演示数据的采集,还能在真实(野外)环境中收集演示数据,极大地简化了数据收集流程,并将机器人手臂的操作范围拓展至非结构化环境,使机器人能够从与人类的互动中学习并适应各种情况。
图 1:团队提出的基于低成本外骨骼AirExo的野外学习框架,使人类操作者不仅能够控制双臂机器人收集遥操作演示数据,还能直接记录野外演示数据。与传统遥操作演示数据相比,该框架充分利用了广泛且经济的野外演示数据进行策略学习,从而使训练出的策略比仅依赖更多遥操作演示数据的策略更具通用性和鲁棒性。
在野外学习框架下,仅通过3分钟的遥控演示,并结合AirExo系统收集的多样、广泛的野外数据,机器人便能学习到一种有效策略。所训练的机器人策略在性能上不仅能与通过超20分钟遥操作演示学习的策略相媲美,甚至在某些情况下表现更为出色。
为了更全面地验证AirExo的性能,研究团队对不同方法在“收集球”任务以及“从带帘架子上抓取”任务中的表现进行了评估。实验结果表明,研究团队提出的方法能够在任务学习的各个阶段帮助模型获得更具通用性、更稳健的策略,特别是在存在扰动的情况下,显著提高任务完成的成功率。
模仿学习在机器人学习中得到了广泛应用,特别是在通过观察和模仿人类专家演示来训练机器人执行各种任务时。行为克隆是其中最简单的实现方法之一,它通过监督学习直接从演示中学习策略,而无需考虑任务的意图和结果。
在机器人操控中,遥操作演示数据尤为重要,特别是对于基于模仿学习的算法。这些演示数据通常通过人类遥操作机器人执行任务的方式收集,是一种自然且常见的获取方法。然而,传统的机器人系统往往价格昂贵且缺乏便携性,给大规模数据收集带来了显著挑战。
为了解决这一问题,先前的研究开始探索从交互式人类演示中学习的可行性,从而推动了机器人操控在野外学习场景中的应用。这些研究不仅降低了数据收集的成本和复杂性,还为机器人学习的普及开辟了新的可能性。
▍AirExo: 开源、便携、适应性强、低成本且稳健的外骨骼系统
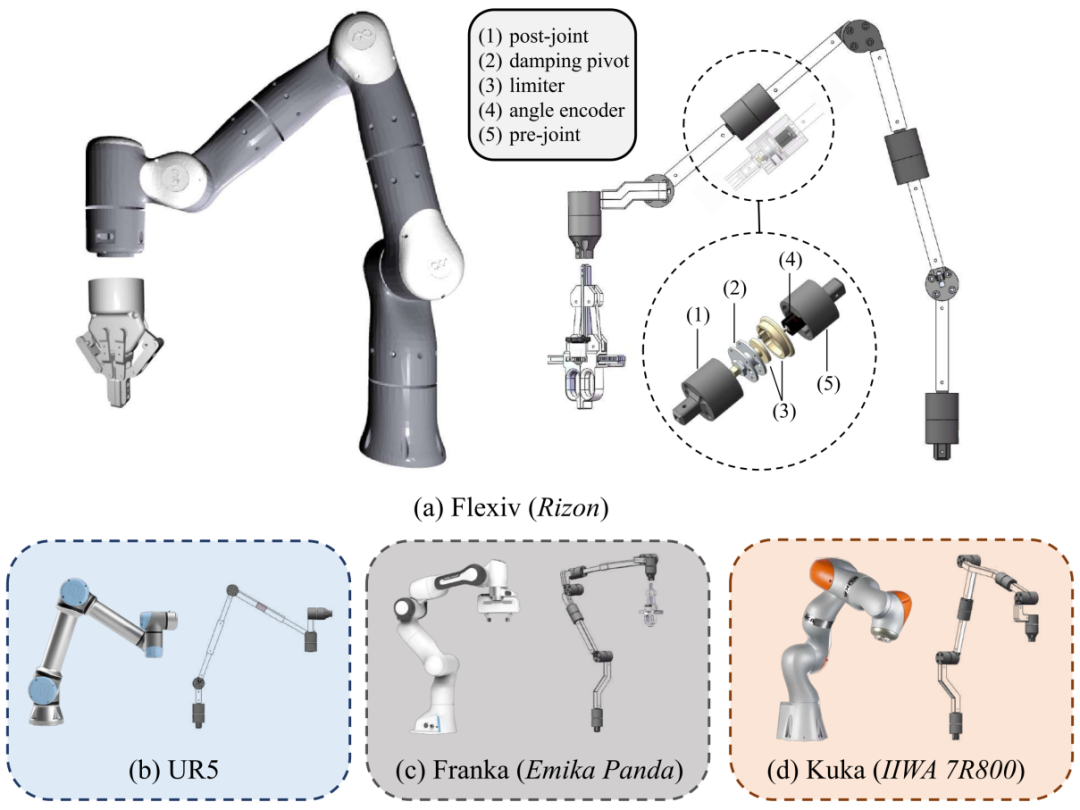
基于低成本、高适应性、强便携性、持久耐用及易维护这五大核心目标,团队开发了AirExo。该系统的设计已针对机械臂规格进行了优化,实验中使用了Flexiv Rizon机械臂。AirExo还具备高度的可调性,可轻松适配其他机器人(如UR5、Franka Panda和Kuka IIWA 7R800,见图2)。
图 2:AirExo模型适用于不同类型的机器人。需注意,关节的内部结构是标准化的,只有连杆部分根据不同的机械臂配置进行了调整。
AirExo由两只对称的外骨骼设备组成,每个单臂的初始7个自由度(DoF)对应于机械臂的关节自由度,末端设计有可选的双指夹爪,用于模拟末端执行器的功能。为优化穿戴体验和任务效率,AirExo的尺寸设计为机器人尺寸的80%,更符合人类手臂的比例,并结合人体工学设计,有效减轻操作员手臂负担并增强灵活性。
AirExo的关节采用双层结构,外壳分为预关节和后关节,通过金属阻尼枢轴连接,实现稳定的关节运动。每个关节配备高精度角度编码器,能够实现精确的运动捕捉,确保低延迟与高精度的性能表现。除紧固件和电子元件外,所有部件均采用PLA塑料通过3D打印制作。这种材料具有高强度和低密度的特点,确保外骨骼既轻便且坚固,满足多样化应用需求。
AirExo的校准过程简便高效。通过将机器人手臂置于特定位置,并同步调整外骨骼的姿态,即可记录机器人的关节位置与外骨骼编码器的读数。在遥操作过程中,外骨骼编码器读数可实时转换为对应的机器人关节位置,确保操作的精准性与可靠性。
经过校准,外骨骼能够覆盖机器人手臂的大部分有效角度范围,从而满足绝大多数任务的需求。对于超出常规范围的特殊任务,可通过调整控制系数扩展操作范围,并在任务特定的运动学约束下进一步提升性能,确保更高的灵活性与适应性。
在全臂操控学习中,AirExo通过安装摄像头模拟机器人摄像头的位置。这种配置使遥操作演示与现实(野外)环境演示的图像结构高度相似,有助于策略的有效学习。团队提出了在现实环境中,基于AirExo的全臂操控两阶段训练方法:
在此阶段,团队利用大量人类演示数据以及外骨骼编码器记录的动作数据对策略进行预训练,从而学习任务的高层次策略。
在此阶段,通过包含机器人动作的遥操作演示进一步优化策略,增强其实际执行能力。
研究表明,外骨骼尺寸的调整对策略学习的影响非常有限,因为核心运动学结构未发生变化。此外,AirExo提供的视觉-动作配对数据足以支持预训练阶段,无需对人类演示与机器人图像进行精确对齐。实验结果进一步表明,预训练显著提高了机器人的任务性能,并大幅提升了遥操作的样本效率。
团队通过两个全臂操作任务对所提出的学习方法进行了性能评估,所有演示数据均由AirExo收集完成。
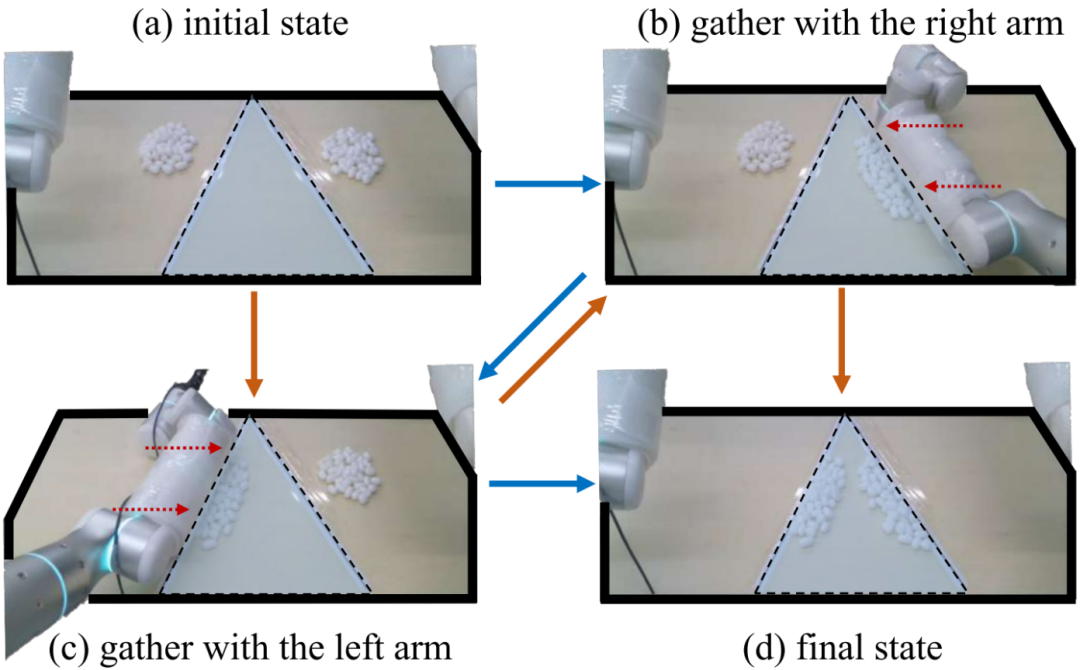
任务:在该任务中,桌子两侧随机放置两组棉球(每组40个),要求操作机器人双臂将所有棉球收集到指定的中央三角形区域内。任务过程中涉及多样化且复杂的接触操作,如图3所示。
图 3:收集球任务的定义:任务目标是将球收集到中央三角区域,该区域以浅蓝色突出显示。红色虚线箭头表示机器人手臂的动作。团队使用海绵垫包裹机器人手臂外表面,以减少接触产生的机械故障。值得注意的是,任务的多模态性使得操作可以通过沿蓝色箭头或橙色箭头的路径完成。
团队将任务完成率定义为被成功收集到中央三角形区域内的球的比例(若球正好落在边界线上,则计为一半),这一指标同时计算左臂和右臂的完成情况。任务成功率则定义为任务完成率超过某个阈值δ的比例。本实验中,团队设置δ为40%、60%和80%。此外,碰撞率被用来衡量操作的精确性的指标。
在评估中,团队采用了VINN及其变体(如使用不同视觉表征的版本)作为非参数方法,其他对比方法包括ConvMLP、BeT和ACT。这些方法均适用于关节空间控制,或可通过简单调整以适应关节空间控制需求。
团队将提出的野外学习框架应用于ACT方法:利用野外演示数据进行初步训练,并结合遥操作演示数据对策略进行微调,从而实现性能优化。
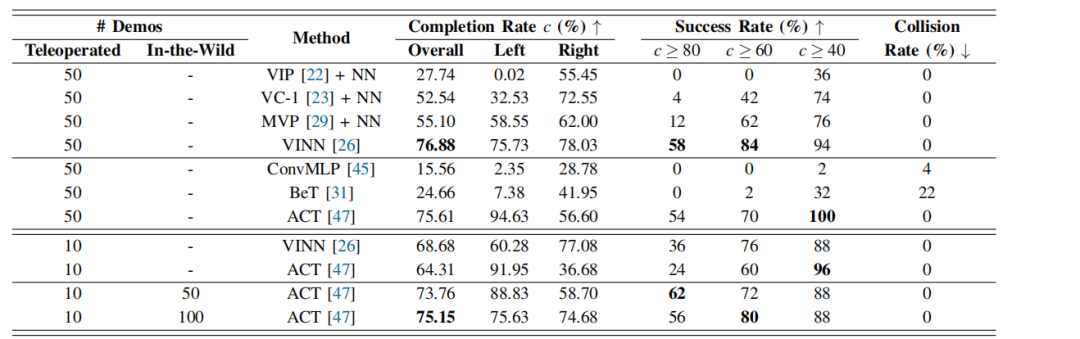
实验结果如表1所示。在使用50次遥控演示进行策略训练时,VINN在所有非参数方法中表现最佳,而ACT在所有参数方法中表现最佳。尽管BeT在基于状态的仿真环境中表现出色,但在现实世界应用中却因碰撞问题表现较差。团队认为,这可能是由于BeT缺乏有效的状态提取器,难以应对复杂的图像输入。
当训练数据减少至10次遥操作演示时,VINN和ACT的性能均有所下降。然而,通过应用团队提出的野外学习框架,ACT在仅使用10次遥控演示的情况下,仍能达到与50次演示相当的性能。这一结果证明,该框架显著提升了策略的样本效率。
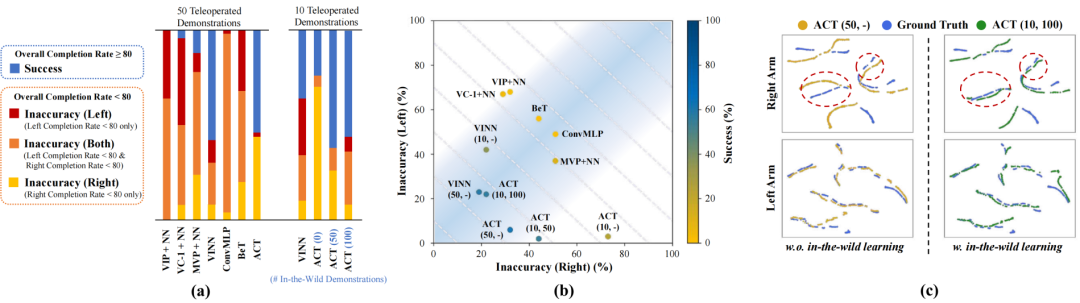
图 4:收集球任务中各方法的分析。将整体完成率超过80%定义为成功。(a) 分析了每个方法在每次试验中的失败原因。(b) 将不准确率(左臂和右臂)均匀分配到左臂不准确率和右臂不准确率中,并绘制了不同方法的失败模式对比图。(x, y) 表示策略是通过y次野外演示和x次遥控演示进行训练的。虚线表示具有相同成功率的等高线,浅蓝色背景区域表示左臂和右臂之间更加平衡的策略。(c) t-SNE可视化展示了真实动作和带/不带野外学习的策略动作在验证集上的表现。
进一步分析实验中的失败案例(如图4所示),团队发现ACT策略在两臂动作间存在不平衡现象,尤其是在遥操作演示数量较少的情况下。通过引入野外学习框架,策略能够在两臂间实现更均衡的准确性,同时对右臂动作的学习表现出更强的专注性(如图3(c)所示)。团队认为,这得益于AirExo提供的多样化且高精度的野外演示数据,使策略在预训练阶段能够掌握高层次的策略知识,从而在微调阶段更高效地优化具体动作。
该任务要求机器人用右臂推开遮帘,抓取遮帘下的棉质玩具并将其放入箱子中。任务分为多个阶段(如图5所示),并以每个阶段结束时的平均成功率作为评估指标。实验选用VINN和ACT两种方法,同时结合团队提出的野外学习框架应用于ACT策略进行测试。
图 5:遮帘架抓取任务的定义。机器人需要:(a)用右臂伸向透明遮帘,(b)推开遮帘,然后(c)用左臂接近物体,(d)抓取物体,最后(e)投掷物体。
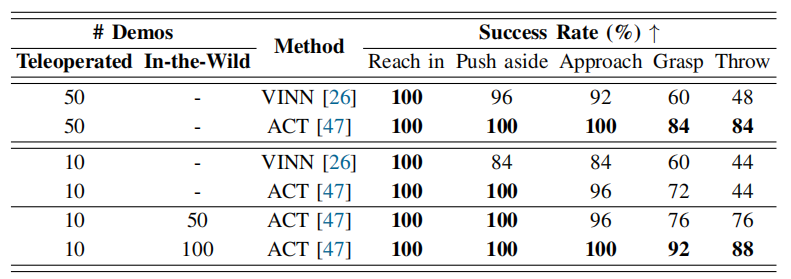
如表2所示,随着遥操作演示次数的减少,VINN和ACT的成功率均有所下降,特别是在“throw”阶段表现尤为明显。然而,结合野外学习框架后,ACT在“grasp”和“throw”阶段的成功率显著提升,甚至超越了使用50次遥操作演示训练的效果。值得注意的是,仅通过10次遥操作演示,ACT即可达到与50次演示相当的表现。这充分证明了野外学习框架在提升多阶段全臂操作任务成功率方面的有效性。
为评估野外学习框架对策略鲁棒性和泛化能力的提升,团队设计了三种环境扰动进行实验。表3显示,野外学习框架通过多样化的野外演示,显著增强了策略的鲁棒性,使其能够更有效地适应不同类型的环境扰动。这一结果表明,该框架在应对复杂场景和未知变化方面具备优越性。
团队开发了AirExo,一款开源、低成本、通用、便携且稳健的外骨骼设备,支持双臂机器人的关节级遥操作和野外环境中的全臂操控学习。为减少对资源密集型遥操作演示的依赖,团队提出了一种全新的野外学习框架。实验结果表明,通过该框架学习的策略能够更深刻地理解任务需求,在多阶段全臂操控任务中展现出卓越性能,甚至优于仅依赖大量遥操作演示从零开始训练的策略。此外,在多种扰动条件下,使用改框架训练的策略表现出更高的鲁棒性。未来,团队计划进一步研究如何缩小野外人类演示数据与机器人遥操作数据之间的图像差距,以实现机器人直接通过AirExo在野外演示中学习,从而进一步降低学习成本。
(文:机器人大讲堂)