

在AI问答场景,尤其是大数量级的AI数据处理场景,html直接喂给AI是行不通的,消耗资源太多了。
我们曾经也面临这个问题,解决方案很简单,最好的方式就是把html转成Markdown格式。
只不过之前图省事,我们直接调用了JinaAI的API,先把html转换成Markdown再喂给AI去处理。
今天突然发现,JinaAI开源了ReaderLM-v2,这意味着成本又降低了啊!
当然在效果上也有很大的提升。
扫码加入AI交流群
获得更多技术支持和交流
(请注明自己的职业)

项目简介
ReaderLM-v2是由JinaAI开源的一个1.5B参数的语言模型,它能够将原始HTML内容精准转换为格式优美的Markdown或JSON。该模型专为HTML解析、转换和文本提取任务而训练。可处理长达512K tokens的输入输出,且在生成长序列时稳定性更强。通过Reader API、Google Colab和本地部署都能便捷使用,实现高效的内容转换与提取。
DEMO及对比
·HTML转markdown
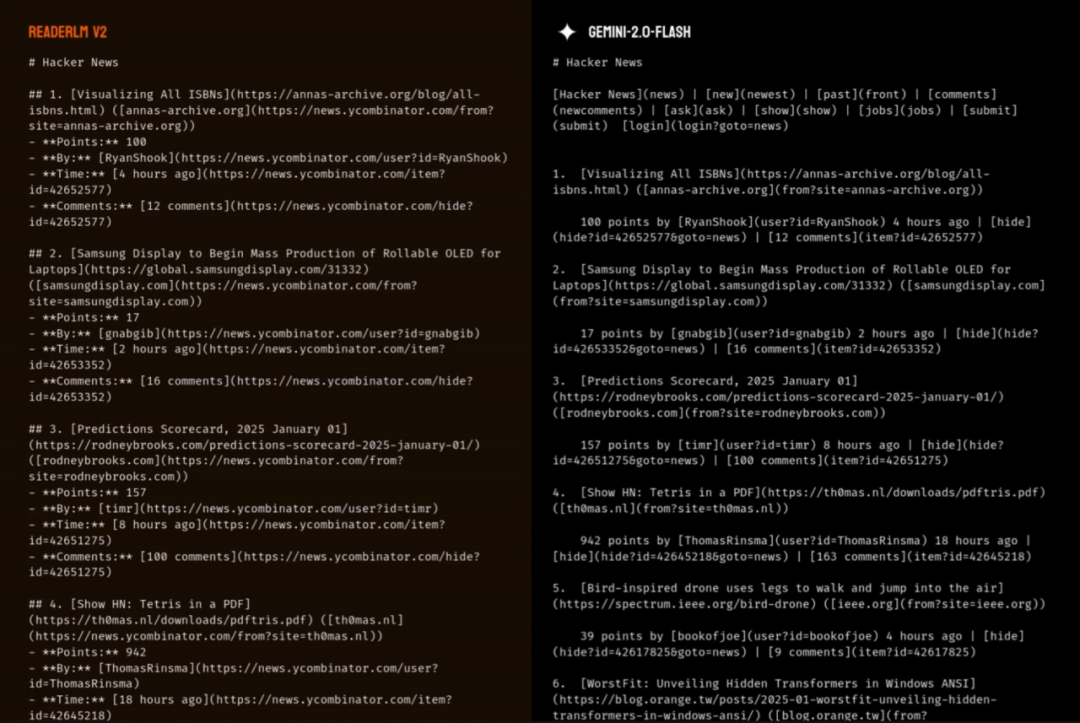
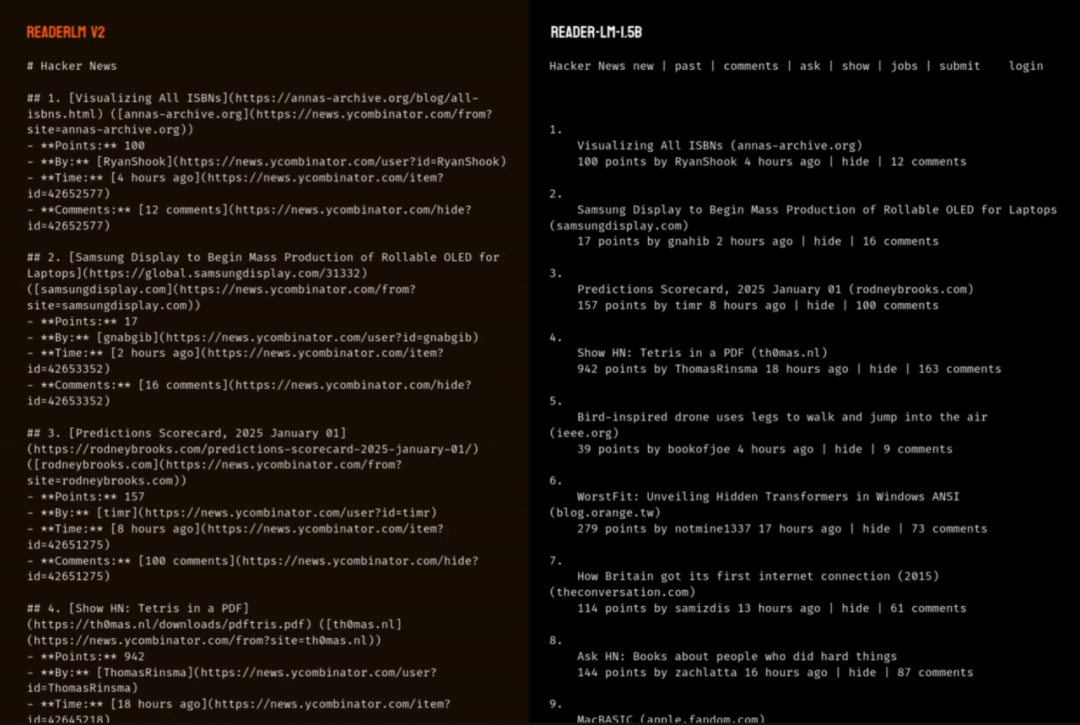

·HTML转JSON

功能升级
相较于V1版本,ReaderLM-v2做了很多的升级。
1、更好的Markdown生成
使用了新的训练范式和更高质量的训练数据,虽然V1版本将 HTML 转 Markdown 的转换视为一个”选择性复制”任务,但v2 将其视为真正的翻译过程。这种转变使模型能够熟练运用 Markdown 语法,擅长生成代码框、嵌套列表、表格和 LaTex 方程式等复杂元素。
2、JSON输出
新增加了直接从HTML到JSON的生成,使用预定义的模式,消除了中间Markdown转换的需要。
3、更长的上下文处理
能够处理长达512K tokens的组合输入和输出长度,在处理长篇内容时性能得到提升。
4、多语言支持
全面支持29种语言,包括英语、中文、日语、韩语、法语、西班牙语、葡萄牙语、德语、意大利语、俄语、越南语、泰语、阿拉伯语等。
5、更强的稳定性
通过训练过程中的对比损失,大大减轻了生成长序列后的退化问题。
项目链接
https://huggingface.co/jinaai/ReaderLM-v2
关注「开源AI项目落地」公众号
(文:开源AI项目落地)
技术再牛逼也要简单易用
JinaAI的ReaderLM-v2终于来啦!这波操作稳了, HTML转 Markdown/JSON的成本骤降,效率翻倍! markdown语法直接上分,告别中间转换环节,简直不要太爽!