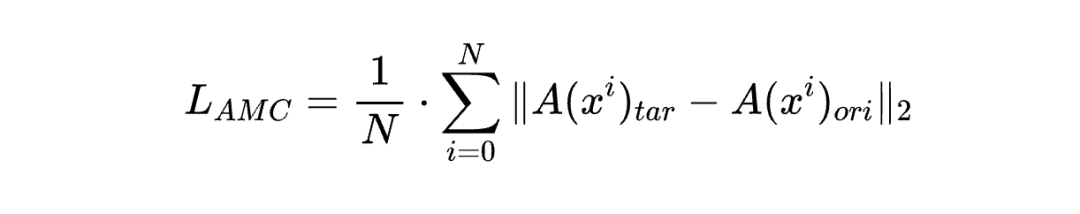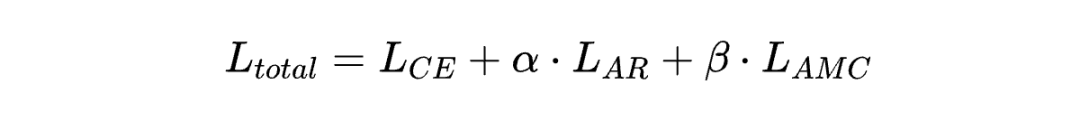Text-Guided Attention is All You Need for Zero-Shot Robustness in Vision-Language Models
论文作者:
余璐(天津理工大学),章海洋(天津理工大学),徐常胜(中科院自动化所)
收录会议:
论文链接:
https://arxiv.org/abs/2410.21802
代码链接:
https://github.com/zhyblue424/TGA-ZSR

前言概要
大规模预训练的视觉-语言模型(Pre-trained Vision-Language Models, VLMs)已经在人工智能领域展现了卓越的成功,这些模型通过融合视觉和文本数据,能够理解复杂的多模态信息。以 CLIP 模型为例,它证明了利用大型数据集进行预训练可以在多种跨模态任务中取得优越的性能。
然而,研究表明 CLIP 对于对抗攻击生成的对抗示例较为脆弱,可能导致错误分类或改变模型输出,这对下游任务的应用造成严重影响。随着视觉-语言模型在现实中的广泛应用,理解和缓解这种威胁对于保持人工智能系统的可靠性是至关重要的。
传统的提升模型对抗鲁棒性的方法通常依赖于对抗示例的生成,并通过这些样本对模型进行再训练以提高其对抗鲁棒性。这种方法面临两个主要挑战:一是需要访问原始数据以生成对抗示例;二是对抗示例的生成过程往往需要大量的计算资源。
因此,探索零样本对抗鲁棒性是一个潜在的研究方向,旨在提升模型鲁棒性的同时,无需直接访问原始数据或消耗大量资源生成对抗示例。而先前的研究未能利用视觉-语言模型中丰富的文本信息,从而限制了模型性能的进一步提升,并且在解释对抗攻击对模型鲁棒性的影响方面存在不足。
针对上述问题,作者首先通过比较对抗示例与干净示例的文本引导注意力图(text-guided attention maps),揭示了一个关键现象:尽管人眼难以区分两种示例,但它们的文本引导注意力图却显示出显著差异。
基于这一现象,作者提出了基于文本引导注意力的方法——Text-Guided Attention for Zero-Shot Robustness(TGA-ZSR),利用文本信息增强模型的对抗鲁棒性。
论文贡献总结如下:

研究内容
作者首先通过获取对抗示例与干净示例的文本引导注意力图(text-guided attention maps),揭示了一个关键现象:尽管从视觉上看,两种示例难以区分,但它们的文本引导注意力图却显示出显著的差异。
具体观察发现,对抗示例的文本引导注意力发生了明显变化,表现为注意力向其他物体或背景偏移,甚至在某些情况下出现了注意力消失的现象。

▲ 图 1: 对抗示例与干净示例及其对应的注意力图
基于这一现象,作者提出了基于文本引导注意力的方法 —— Text-Guided Attention for Zero-Shot Robustness(TGA-ZSR),旨在充分利用文本引导的注意力图来提升模型的对抗鲁棒性,同时保持在干净示例上的高性能。TGA-ZSR 的总体框架图如下所示:
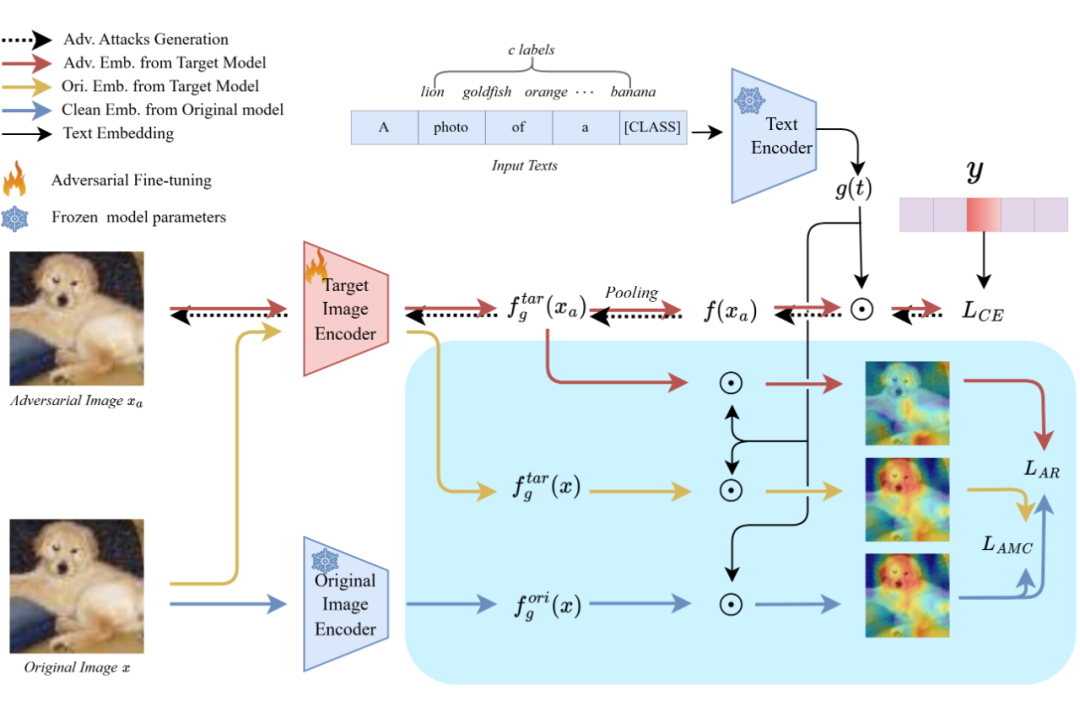
具体而言,主要的组件包含:
1. 注意力精炼模块 (Attention Refinement Module),
该模块专门设计用于校正对抗示例的文本引导注意力,这种注意力的偏差常常导致预测结果的改变。通过将对抗示例的注意力图与干净示例的注意力图对齐,该模块确保对抗示例能够获得与干净示例同样准确的注意力分布。这一简单而有效的策略有效地减轻了对抗扰动对于模型性能的影响。
具体步骤如下:首先,将对抗示例 输入目标模型 ,并将干净示例 输入原始模型 ,从而分别获得对抗示例的注意力图 和干净示例的注意力图 。最后,注意力精炼损失 定义为:
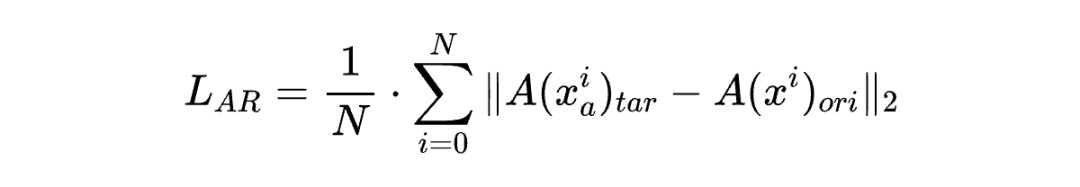
2. 基于注意力的模型约束模块(Attention-based Model Constraint Module),
虽然注意力精炼模块提升了模型的对抗鲁棒性,但可能会因为参数的变化而导致干净示例的准确性发生下降。为了保持视觉-语言模型的泛化能力,作者引入了基于注意力的模型约束模块。该模块的目标是避免干净图像性能下降,以确保模型的整体有效性和可靠性。
具体来说,将干净示例 同时输入目标模型 和原始模型 ,分别获得两种文本引导的注意力图 和 。为了避免与干净示例相关的重要参数发生变化,作者在两个注意力图之间施加了约束,该损失 定义为:
因此,最终的损失函数综合了交叉熵损失 、注意力精炼损失 和基于注意力的模型约束损失 :
其中, 和 是超参数,用于平衡不同损失项的重要性。

该研究在 Tiny-ImageNet 上微调预训练的 CLIP 模型,随后在 15 个数据集上验证模型的零样本对抗鲁棒性。这些数据集分为几类:
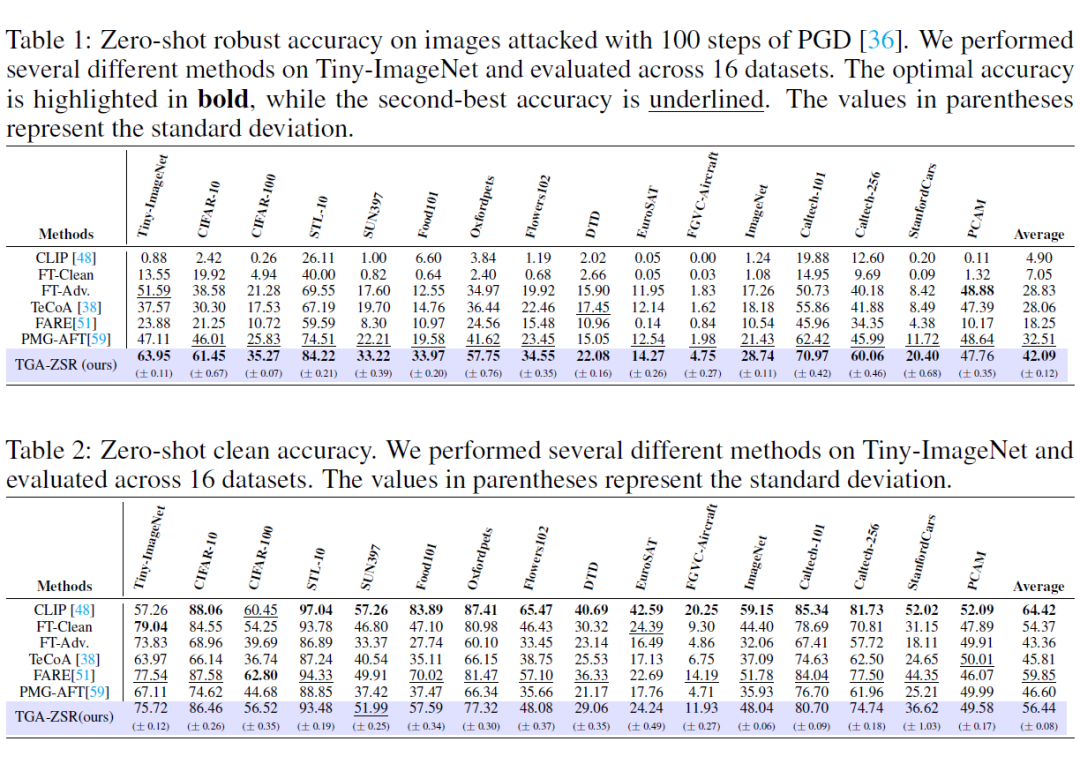
零样本对抗鲁棒准确性:表 1 显示,TGA-ZSR 的平均准确性比原始 CLIP 模型提高了 37.19%。与当前最佳的方法 PMG-AFT 相比,TGA-ZSR 提升了 9.58%。
总体而言,该方法在多个数据集上优于其他所有方法。此外,TGA-ZSR 在 Tiny-ImageNet 上获得了最佳的结果,尽管这不是一个严格的零样本测试,但是这一结果表明了 TGA-ZSR 对于已见和未见数据集都表现出强大的鲁棒性。
零样本干净准确性:表 2 展示了不同方法对于干净示例的准确性。TGA-ZSR 比 PMG-AFT 提升了 9.84%,并且在多个数据集上均有所提升。虽然,TGA-ZSR 的零样本干净示例准确性比 FARE 低 3.41%,这是因为 FARE 更加专注于零样本干净示例的准确性。然而,综合考虑两方面的性能,TGA-ZSR 远超 FARE,展现了更全面的优势。
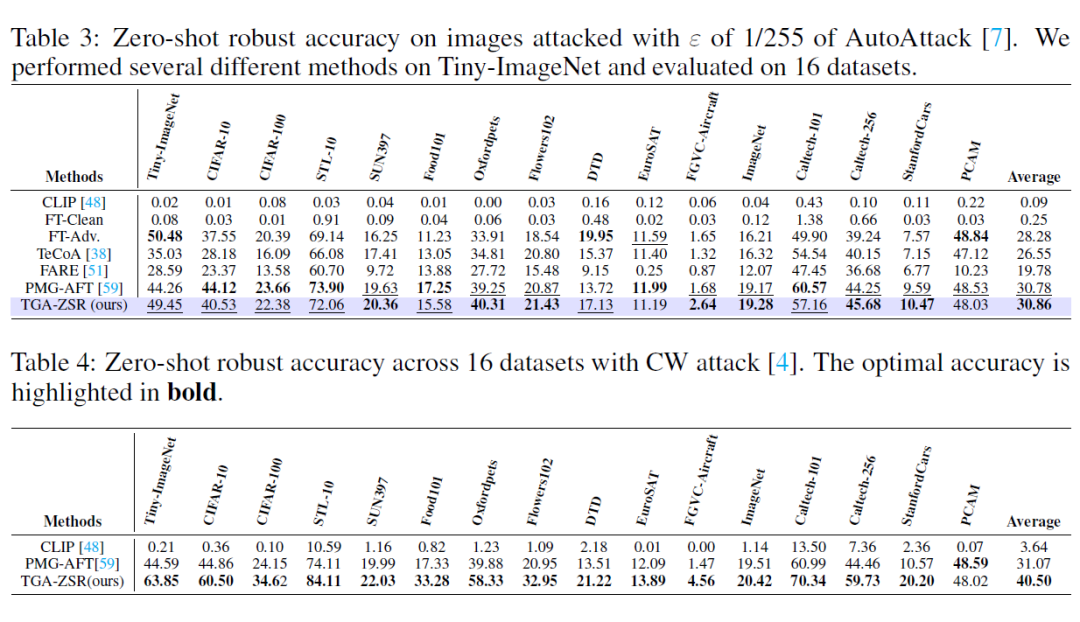
3.3 更多攻击类型的实验(Experiments on More Attack Types)— AutoAttack 实验结果
表 3 显示,在 AutoAttack 上,所有方法的性能都有所下降。尽管 TGA-ZSR 也表现出一定的性能下降,但仍明显优于其他方法,实现了 30.86% 的零样本对抗鲁棒准确性,证明了它在面对更强有力的攻击时的有效性。
CW 实验结果:表 4 表明, TGA-ZSR 在对抗示例上的表现显著优于当前最佳的方法 PMG-AFT,实现了 40.50% 的最佳零样本对抗鲁棒准确性。
综上所述,无论是面对 AutoAttack 还是 CW 攻击,TGA-ZSR 均表现出显著的鲁棒性和有效性,确保了在复杂攻击环境下的稳定性能。
3.4 不同类型注意力的实验(Different Types of Attentions)
为了验证文本引导注意力的重要性,作者将其替换为根据 Grad-CAM 生成的基于视觉的注意力进行实验。表 5 显示,即使替换后,模型的零样本鲁棒准确性和干净准确性仍然可以与当前最佳的方法 PMG-AFT 相媲美,这一发现验证了该方法框架的有效性。
此外,实验结果也表明,文本引导注意力显著提升了模型的性能,证明了文本引导的优势,凸显了文本信息在多模态任务中的重要作用。
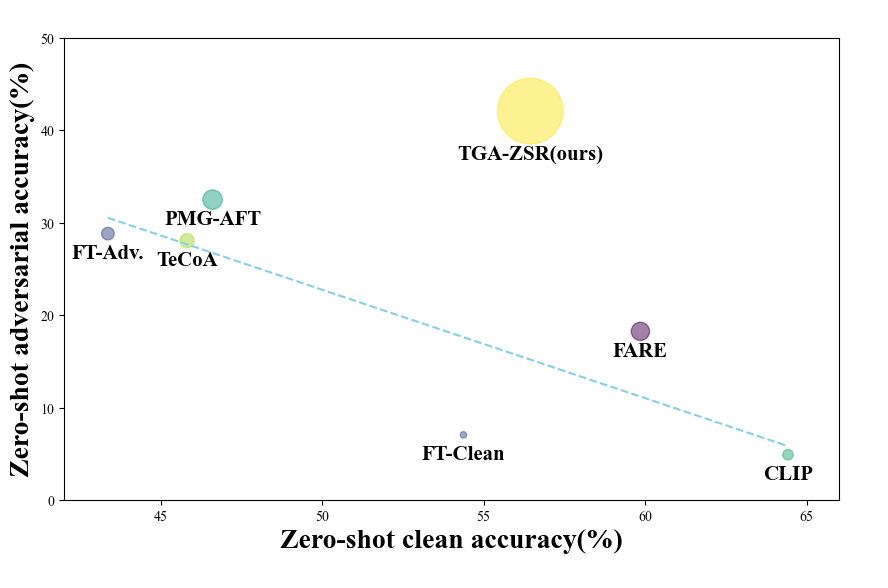
3.5 鲁棒性与干净准确性的权衡(Trade-off between Robust and Clean Accuracy)
在对抗训练过程中,实现鲁棒准确性和干净准确性之间的平衡至关重要。TGA-ZSR 不仅增强了模型的对抗鲁棒性,还保持了良好的干净准确性,从而实现了整体性能的显著提升。

在本文中,作者发现对抗攻击会导致文本引导注意力的偏移。基于这一现象,该研究引入了一种文本引导注意力的方法 —— TGA-ZSR(Text-Guided Attention for Zero-Shot Robustness),该方法结合了两个关键模块来进行对抗微调和约束模型。
这一策略不仅防止模型漂移,还显著增强模型的对抗鲁棒性。大量的实验验证了 TGA-ZSR 的有效性,表明其在多种攻击类型下均表现出色,在鲁棒性和泛化性之间实现了优越的平衡。
(文:PaperWeekly)