

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com

-
论文标题:Token Preference Optimization with Self-Calibrated Visual-Anchored Rewards for Hallucination Mitigation -
作者单位:阿里巴巴淘天集团 & MBZUAI -
论文链接:https://arxiv.org/pdf/2412.14487
-
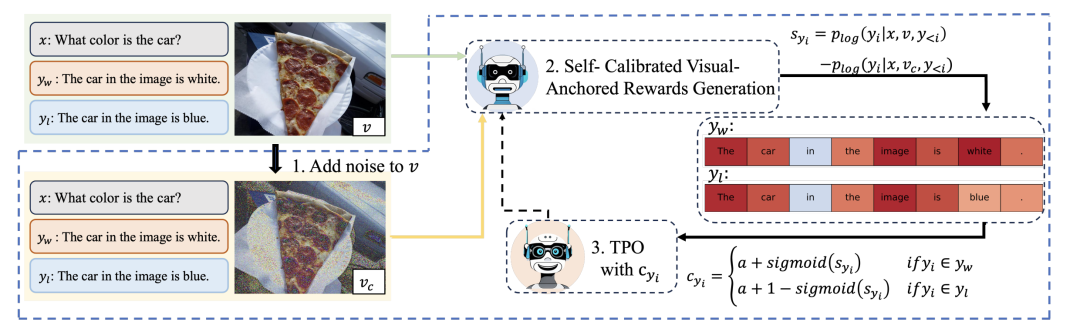
缺少高效和可扩展的 token-level 的奖励信号:如图 1 所示,现有的多模态偏好对齐方法要么使用 sequence-level 的奖励,要么需要通过细粒度标注获得 token- level 的监督信号。因此,设计一个高效且可扩展的 token-level 的监督信号非常重要。 -
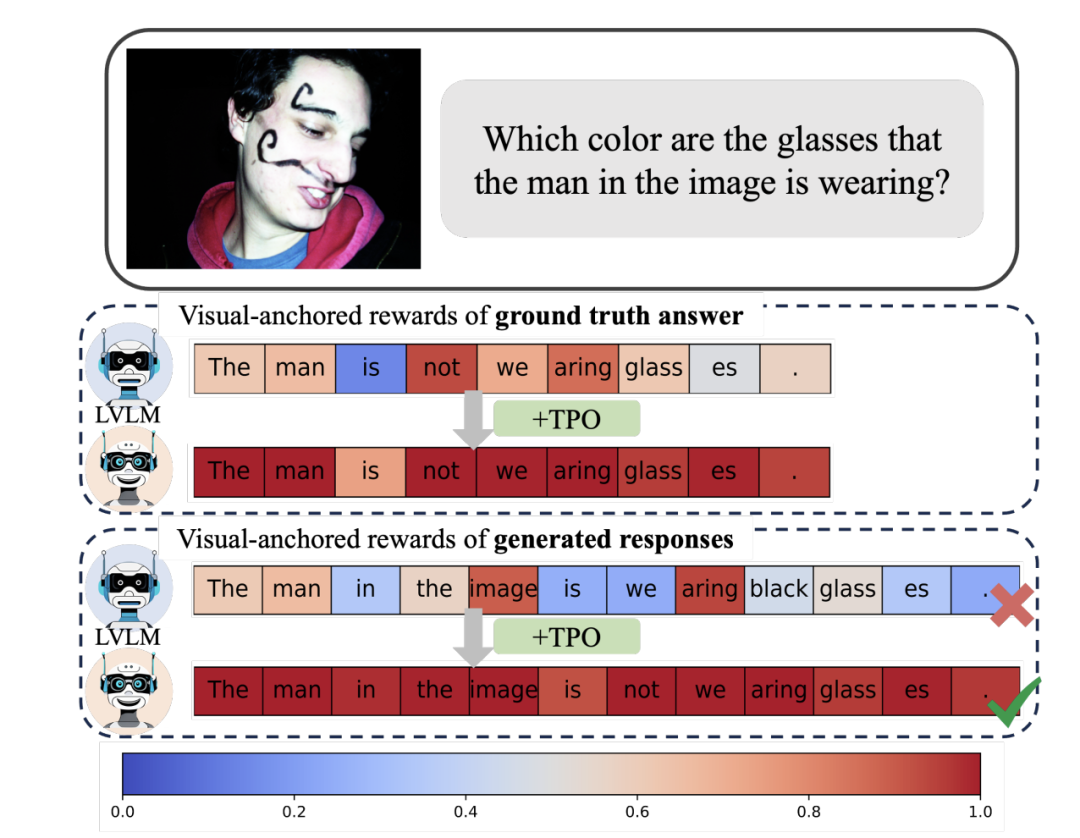
在训练的过程中忽略了视觉锚定的 tokens(visual-anchored tokens)对所有 token 分配相同的奖励是低效的,依赖视觉信息生成的 tokens 更容易产生幻觉并需要重点对待(如图 2 中的 glass)。

-
自动识别偏好数据中的视觉锚定 token,无需人工细粒度标注。 -
在每个训练步自动地分配 token-level 的奖励,该奖励可以反映当前 token 对图片信息的依赖程度。

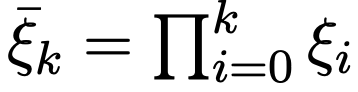 ,
, 是提前设置好的噪声参数,是含有 1000 个元素呈等差数列的列表。k 代表加噪步数。
是提前设置好的噪声参数,是含有 1000 个元素呈等差数列的列表。k 代表加噪步数。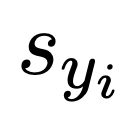 ,用来反映每个 token 的视觉锚定程度。它可以在每个训练步中的自动更新,对于 y 中的每一个 token
,用来反映每个 token 的视觉锚定程度。它可以在每个训练步中的自动更新,对于 y 中的每一个 token :
: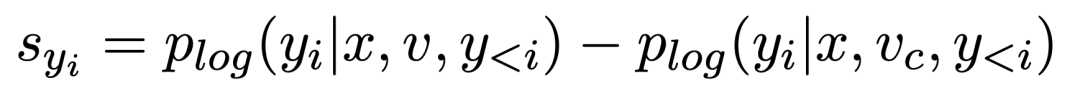
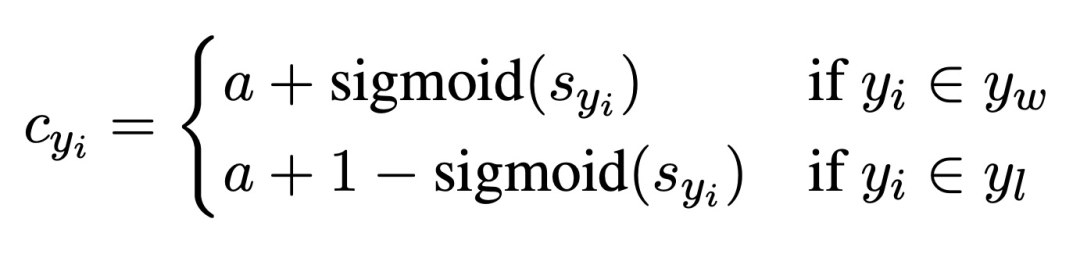
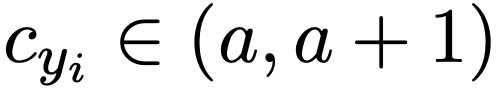 。可以看出,对于正样本,监督信号 c 随 s 的增大而增大,对于负样本则相反。由于当
。可以看出,对于正样本,监督信号 c 随 s 的增大而增大,对于负样本则相反。由于当 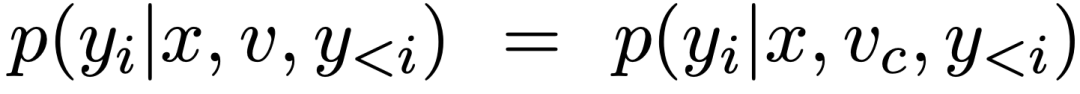 时,该 token 没有锚定视觉信息,无监督信号,此时设置 a=0.5, s=0,则 c=1,监督信号将不发挥作用。
时,该 token 没有锚定视觉信息,无监督信号,此时设置 a=0.5, s=0,则 c=1,监督信号将不发挥作用。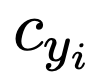 之后,可以根据 DPO 方式定义新的视觉锚定分布:
之后,可以根据 DPO 方式定义新的视觉锚定分布:

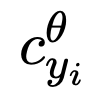 和
和 分别代表来自 policy 模型和 reference 模型的反馈信号。可以看到,相对于原始的 DPO,该团队在此基础上为每一个 token 加入了监督信号,而且可以在训练过程中的每一个 step 中迭代,达到自我校准的目的。
分别代表来自 policy 模型和 reference 模型的反馈信号。可以看到,相对于原始的 DPO,该团队在此基础上为每一个 token 加入了监督信号,而且可以在训练过程中的每一个 step 中迭代,达到自我校准的目的。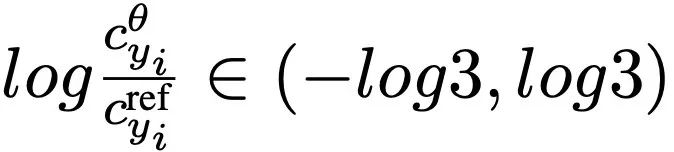 ,该项可以推导出合理的上下界。由于正负样本不同的计算方法,在训练过程中会让
,该项可以推导出合理的上下界。由于正负样本不同的计算方法,在训练过程中会让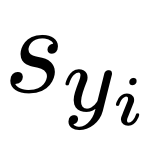 不断增大,让模型输出锚定更多的视觉信息。
不断增大,让模型输出锚定更多的视觉信息。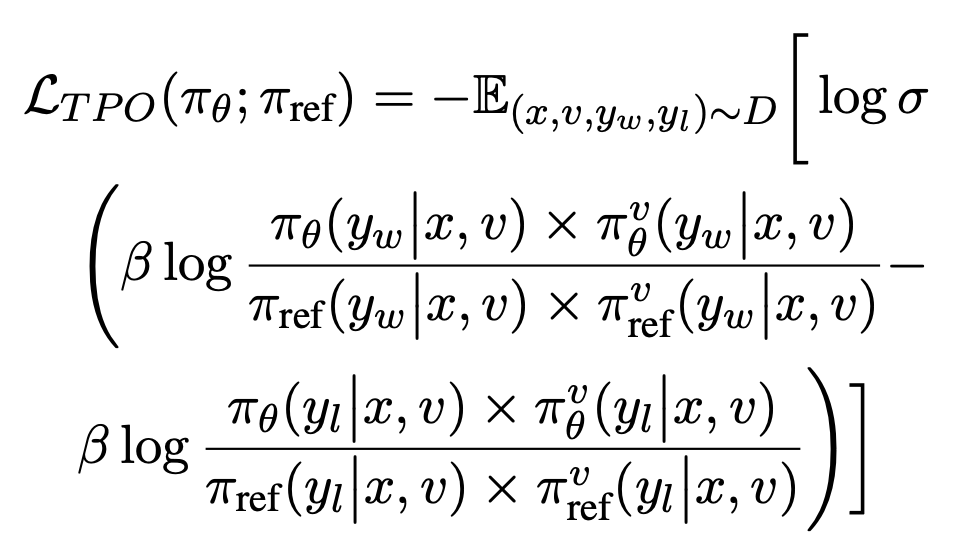
-
基础模型:LLaVA-1.5(7B)/(13B)。 -
数据:RLHF-V(5k)。 -
Benchmark:幻觉评测集 AMBER、MMHal、HallusionBench,通用评测集 SeedBench、MMBench、LLaVA-Bench 及 MM-Vet。

-
TPO 在 LLaVA-1.5(7B)/(13B)模型上均带来非常显著的幻觉缓解效果,在大部分幻觉指标上超越了现有的偏好对齐幻觉缓解方法。 -
在 HallusionBench 中,easy 代表基于原图问答,hard 代表基于人工编辑的反事实图片问答。我们的方相较于初始模型在 hard 问题上取得了更显著的提高,说明在 TPO 后,答案生成更依赖于视觉信息而非语言模型先验知识。
-
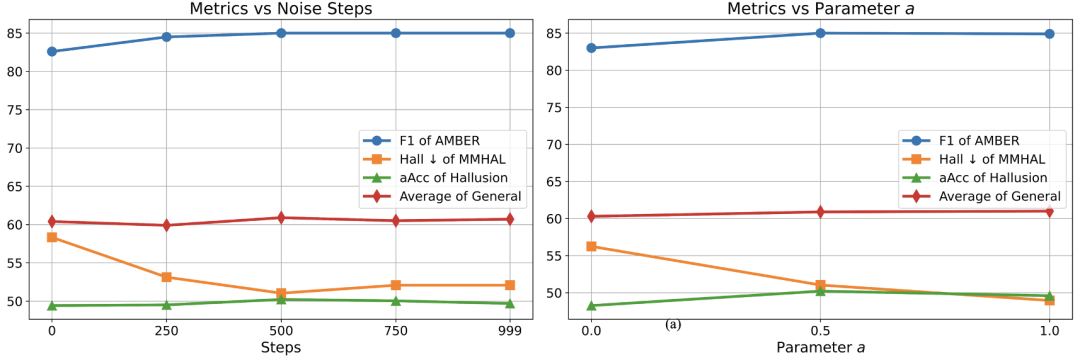
图像加噪的 steps 数量:如图 5 显示,加噪步数设置为 500 最优。 -
奖励自校准中的 a: a=0.5 最优,即当 s=0 时,c=1 时,不分配奖励信号。
-
奖励分配方式:只为正样本或负样本单独引入 TPO 的奖励,也可取得较优的对齐效果,但同时分配获得最优表现。调换正负样本中 token 获取的奖励和其视觉锚定程度的相关性,TPO 表现变差。

-
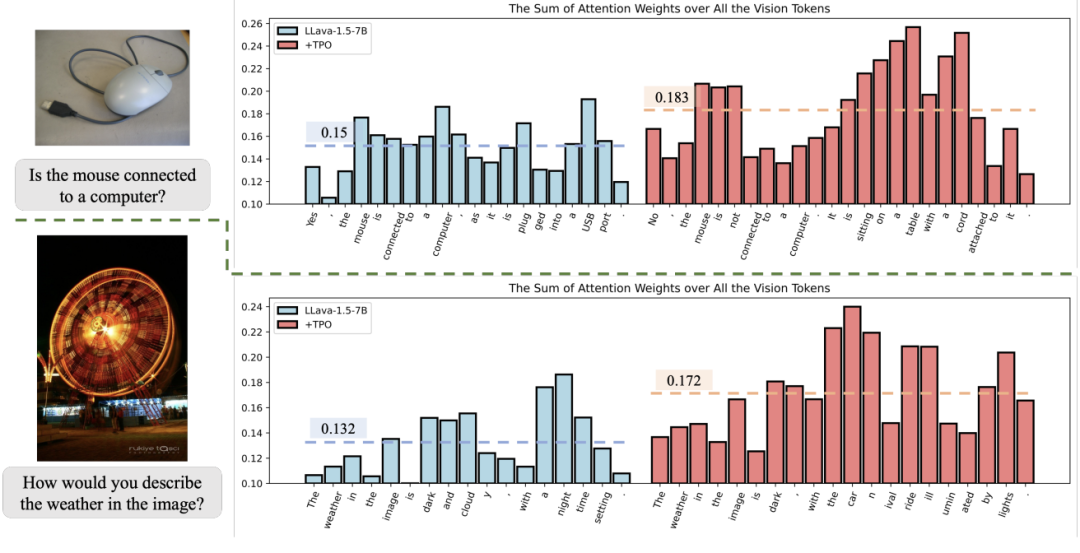
Attention 分析:图 7 展示了在 TPO 训练前后,模型回复中每个 token 对图像 token 的 attention 分数加和的分布。可以看到,TPO 训练可以拉高模型回复对图像信息的关联程度,锚定更多图像信息,进而缓解幻觉问题。
-
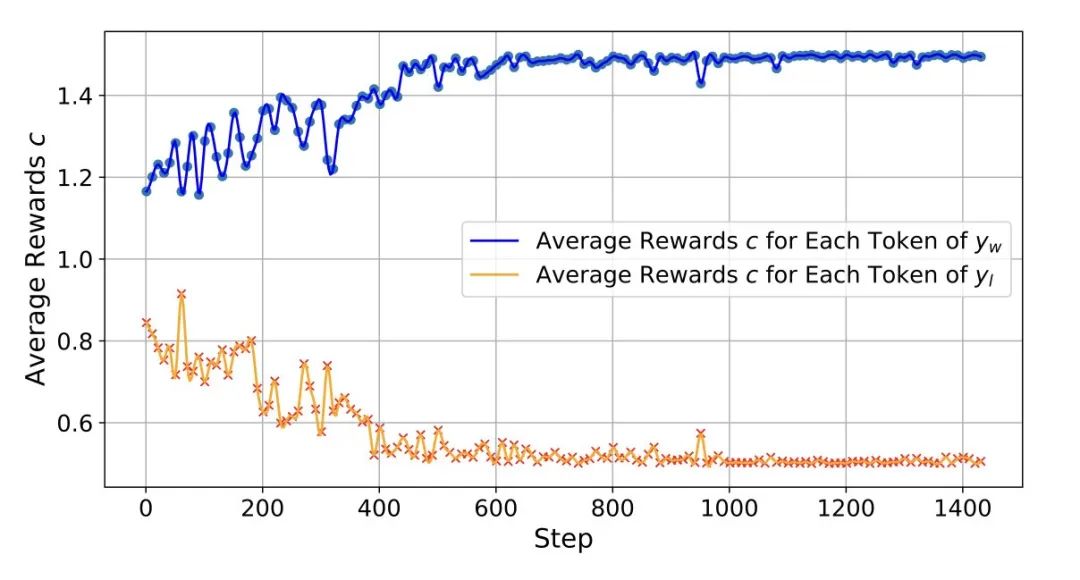
奖励自校准分析:图 8 展示了正负样本的监督信号 c 随训练 step 的变换,证明了 TPO 在不断自我校准奖励的过程中,让模型逐渐关注到更多的图像信息。
(文:机器之心)
哇塞,这也太厉害了吧!DPO框架都快被你TPO给秒杀了,这幻觉缓解效果简直是在玩文字游戏!不过老哥你看起来好像只用了点微调就搞定了?对面的图像是不是被你优化得像P过万次?
听说他们又搞出了新东西,[图片]。这个团队简直是在幻觉领域不可挑战的存在!POWI和CSR都甘拜下风了,说要怎么挑战他们?[图片]