
 关注我,记得标星⭐️不迷路哦~
关注我,记得标星⭐️不迷路哦~
✨ 1: DeepSeek-R1
DeepSeek-R1是一款基于大规模强化学习的推理模型,在数学、代码和推理任务上表现优异。
一、模型概述
DeepSeek-R1 是由深度求索公司开发的第一代推理模型系列,包括 DeepSeek-R1-Zero 和 DeepSeek-R1 两个主要模型。
DeepSeek-R1-Zero: 该模型是通过大规模强化学习(RL)训练,无需预先进行监督微调(SFT),展现出强大的推理能力,并自然涌现出多种推理行为,例如自我验证、反思和生成长链推理(CoT)。 这是第一个公开的研究,验证了大型语言模型(LLM)的推理能力可以通过纯 RL 激励,而无需 SFT,为该领域未来的发展铺平道路。
DeepSeek-R1: 为解决 DeepSeek-R1-Zero 存在的无限重复、可读性差和语言混杂等问题,DeepSeek-R1 在 RL 之前引入了冷启动数据。 DeepSeek-R1 在数学、代码和推理任务上的表现可与 OpenAI-o1 相媲美。
为了支持研究社区,深度求索公司开源了 DeepSeek-R1-Zero、DeepSeek-R1 以及六个基于 Llama 和 Qwen 的 DeepSeek-R1 蒸馏模型。 其中,DeepSeek-R1-Distill-Qwen-32B 在各种基准测试中超越了 OpenAI-o1-mini,为稠密模型树立了新的技术水平。
二、 模型训练
DeepSeek-R1 的训练流程包含以下关键步骤:
基于基础模型的大规模强化学习: 直接在基础模型上应用强化学习,无需预先进行监督微调,使模型能够探索使用长链推理(CoT)来解决复杂问题。
两阶段强化学习: 分别用于发现改进的推理模式和与人类偏好保持一致。
两阶段监督微调: 作为模型推理和非推理能力的种子。
三、模型蒸馏
DeepSeek-R1 的研究表明:
大型模型的推理模式可以被蒸馏到小型模型中,从而获得比小型模型通过 RL 发现的推理模式更好的性能。
使用 DeepSeek-R1 生成的推理数据微调研究社区广泛使用的几种稠密模型,评估结果表明蒸馏的小型稠密模型在基准测试中表现出色。
深度求索公司向社区开源了基于 Qwen2.5 和 Llama3 系列的 1.5B、7B、8B、14B、32B 和 70B 蒸馏模型 checkpoints。
四、模型评估
DeepSeek-R1 系列模型在多个基准测试中表现出色,包括:
英文: MMLU、MMLU-Redux、MMLU-Pro、DROP、IF-Eval、GPQA-Diamond、SimpleQA、FRAMES、AlpacaEval2.0、ArenaHard
代码: LiveCodeBench、Codeforces、SWE Verified、Aider-Polyglot
数学: AIME 2024、MATH-500、CNMO 2024
中文: CLUEWSC、C-Eval、C-SimpleQA
评估结果表明,DeepSeek-R1 在多个任务上优于其他模型,包括 GPT-4o、Claude-3.5-Sonnet-1022 和 OpenAI-o1。 蒸馏模型也表现出色,DeepSeek-R1-Distill-Qwen-32B 在多个基准测试中超越 OpenAI-o1-mini。
五、如何使用
可以通过以下方式使用 DeepSeek-R1:
聊天网站: 在深度求索官方网站 chat.deepseek.com 上与 DeepSeek-R1 聊天,并开启 “DeepThink” 功能。
API 平台: 在 DeepSeek 平台 platform.deepseek.com 上使用 OpenAI 兼容的 API。
本地运行: DeepSeek-R1 模型可以参考 DeepSeek-V3 仓库的信息进行本地运行。DeepSeek-R1-Distill 模型可以使用与 Qwen 或 Llama 模型相同的方式使用,例如使用 vLLM 或 SGLang 启动服务。
地址:https://github.com/deepseek-ai/DeepSeek-R1
地址:https://huggingface.co/deepseek-ai/DeepSeek-R1
✨ 2: GitAgent
GitAgent 是一个个人化的 Git 智能助手,支持代码搜索、重构、自动注释等功能。
GitAgent 非常适合开发者在日常工作中使用,特别是当需要对代码进行快速搜索、重构或生成文档时。无论是初学者还是经验丰富的开发者,GitAgent 都能提升工作效率,减少手动操作的繁琐。
地址:https://github.com/SuperMK15/GitAgent
✨ 3: mini_qwen
mini_qwen是一个大型语言模型项目,具有1B参数,支持预训练、微调和偏好优化,且显存需求低。
mini_qwen是一个具有1B参数的开源大型语言模型(LLM),旨在提供高效且可访问的模型训练体验。该项目分为三个主要部分:预训练(PT)、微调(SFT)和直接偏好优化(DPO)。其全流程训练要求相对较低,仅需12G显存即可进行预训练和微调,而直接偏好优化则需要14G显存,这使得普通的T4显卡用户能够顺利进行训练。
mini_qwen的构建基于Qwen2.5-0.5B-Instruct模型,通过增加模型的层数、维度和注意力头数,将参数数量扩大至1B,并进行随机初始化。训练数据包括来自北京智源人工智能研究院的多种高质量数据集,项目利用最新的训练技术,如flash_attention_2和deepspeed,进行了高效的训练。
通过这一系列的功能和应用,mini_qwen为用户提供了一个灵活的平台来研究和实践大型语言模型的使用。
地址:https://github.com/qiufengqijun/mini_qwen
✨ 4: AI ContentCraft
AI ContentCraft 是一款多功能内容创作工具,支持故事、播客脚本、语音和图像生成。
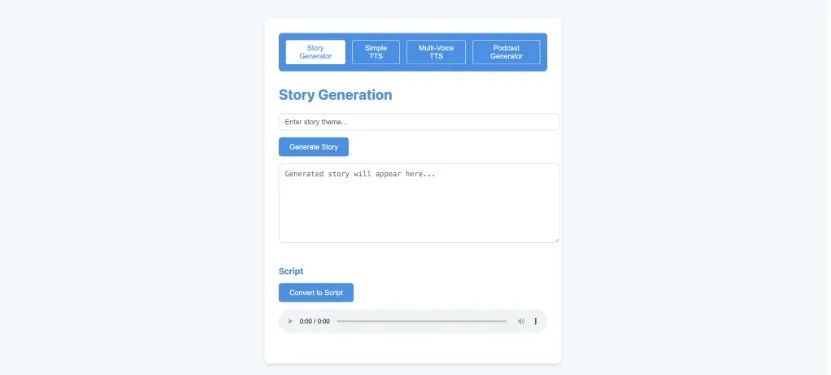
AI ContentCraft 是一款多功能的内容创作工具,集成了文本生成、语音合成和图像生成等多种功能。该工具旨在帮助创作者快速生成故事、播客脚本及其配套的音频和视觉内容。通过其强大的功能,用户可以轻松完成创作过程,提高工作效率。
地址:https://github.com/nicekate/AI-ContentCraft
✨ 5: Story-Adapter
Story-Adapter是一个无训练、迭代的长篇故事可视化框架,通过逐步优化生成图像以保持语义一致性。

Story-Adapter 是一个无须训练的迭代框架,旨在进行长篇故事的可视化生成。随着文本到图像模型(尤其是扩散模型)的发展,故事可视化技术取得了显著进展。然而,在处理长篇故事(可达100帧)时,保持语义一致性、生成高质量的细致交互和确保计算可行性依然面临挑战。Story-Adapter 的核心创新在于其迭代机制,该机制通过不断整合文本提示和前一轮生成的所有图像来优化生成过程,并引入了一种无训练的全局参考跨注意力模块,确保整个故事在语义上的一致性,同时降低计算成本。通过这样的方法,Story-Adapter 能够逐步生成更精确、更细致的图像。
Story-Adapter 的设计目标是解决长幅故事可视化中存在的挑战,使得生成的作品在艺术性和叙事性上都能达到较高的水平。
地址:https://github.com/UCSC-VLAA/story-adapter
(文:每日AI新工具)