

数学比赛AI新冠军诞生了!
在数学竞赛级别的AIME测试中,一个名叫DeepSeek-R1-Distill-Qwen-1.5B的开源模型,以28.9%的成绩打败了GPT-4和Claude 3.5-Sonnet!

这不是开玩笑。更让人惊讶的是,这个模型仅有1.5B的参数量,却在MATH测试中取得了83.9%的惊人成绩。
这个打破纪录的模型来自DeepSeek公司最新发布的DeepSeek-R1系列。
蒸馏魔法
DeepSeek的研究人员采用了一个堪称「魔法」的技术:知识蒸馏(Knowledge Distillation)。
这项技术让他们成功将671B参数的大模型智慧,浓缩进了更小的模型中。就像把一锅汤熬制成浓缩精华,营养全都保留了下来。
更神奇的是,DeepSeek-R1系列不仅发布了这个1.5B的「小精灵」,还开源了整个模型家族:
-
基于Qwen的1.5B、7B、14B和32B版本
-
基于Llama的8B和70B版本
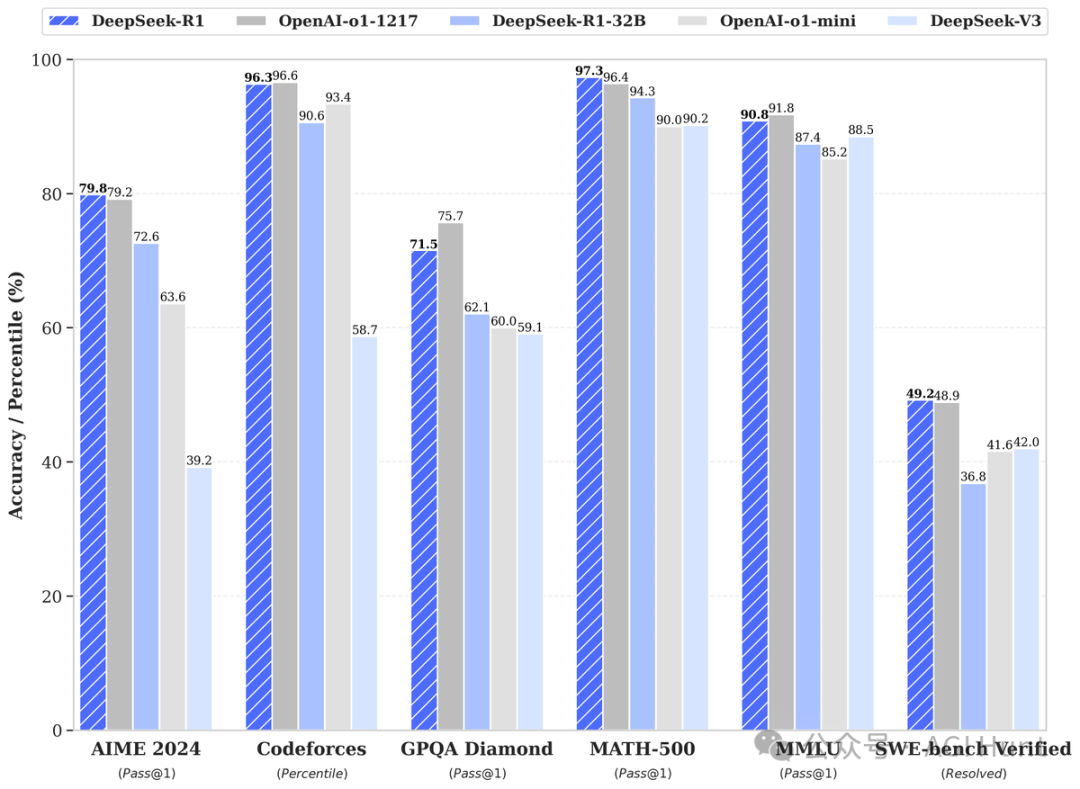
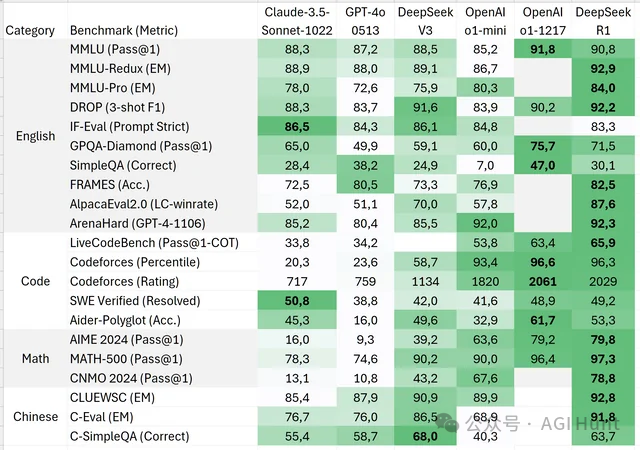
其中,DeepSeek-R1-Distill-Qwen-32B的表现更是惊艳,在多个测试中超越了OpenAI的o1-mini!
MIT许可证
DeepSeek团队的大方程度让人感动。他们不仅完全开源了模型,还采用了MIT许可证,这意味着:
-
可以免费商用
-
允许任意修改和衍生开发
-
支持进行二次蒸馏训练
难怪AI工程师Rohan Paul忍不住感叹:「蒸馏真是一个神奇的概念。」
The AI Veteran也表示:「热爱蒸馏技术,它能做出一些有趣的事情。」
而Dobby the Builder则更进一步指出:「蒸馏技术不仅让AI模型更高效,还能显著提升其性能。」
技术细节大揭秘
DeepSeek-R1的成功不是偶然。团队在技术报告中透露,他们采用了一些独特的训练方法:
-
使用大规模强化学习直接作用于基础模型
-
无需预先进行监督微调
-
开发出特殊的训练流程,包含两个强化学习阶段和两个监督微调阶段
现在,你可以在chat.deepseek.com上亲自体验这个强大的模型,只需打开「DeepThink」开关即可。
这个开源的小模型为什么能在数学和推理能力上超越那些重量级选手?
DeepSeek团队补充说到:
「小模型也能变得很强大。」
(文:AGI Hunt)
蒸馏技术果然名不虚传!这个开源小模型竟然在数学竞赛中击败大神,AI世界真是个神奇的地方。