
MME-Finance: 专家级理解和推理的多模态金融基准

研究背景
金融领域首个多模态基准正式发布!近年来,多模态基准在通用领域的迅速发展为多模态模型的进步提供了强大助力。然而,金融领域具有其独特性:专业的图像(如K线图、MACD 指标图等)和丰富的行业术语(如成交量、换手率等)使得现有的通用基准难以有效评估金融多模态模型的表现,从而影响金融大模型的发展。为了弥补这一差距,同花顺研究院携手南京大学、帝国理工、北航和复旦大学,共同推出了中英双语金融多模态基准——MME-Finance。该基准涵盖 1171 个英文和 1103 个中文问题,问题被细分为 11 类金融相关子任务,涉及从基础的视觉感知能力到高层次的认知决策能力,全面评估多模态模型的表现。这些问题经过专家严格审查,确保高质量标准。同时,为了贴近实际应用,所有问题均采用开放形式。
MME-Finance 的创新之处主要体现在以下三个方面:
1. 首个金融领域的中英双语多模态基准,填补了行业空白。
2. 多层级能力划分,覆盖丰富多样的图像类型,紧密结合实际应用场景。
3. 开放问答形式结合自动化评估策略,显著提升模型评估的准确性。
基准介绍
❍能力维度
在金融领域的独特背景下,MME-Finance 将多模态大模型的能力精细划分为三个层次。最基础的层次是视觉感知能力,它指模型提取和理解图像中的视觉信息的能力,因此构成了多模态大模型的核心与通用能力。基于该能力,MME-Finance 设计了四类任务:图片摘要、OCR (光学字符识别)、实体识别和空间感知。中间层次则是逻辑推理能力,它代表了多模态大模型在金融领域进行数值计算的能力。本基准中的相关任务包括精确数值计算和估计数值计算。两者之间的主要区别在于,估计数值计算需要根据图像中的位置关系等线索来预估数值,而非直接提取。最高层次是复杂的认知决策能力,涵盖了风险提醒、投资建议、原因解释和金融知识问答四大任务。以下表格展示了每类任务的样本数量统计结果:

❍数据收集流程
为了确保收集的图片更贴近实际应用场景,MME-Finance 的所有图片均由专业标注人员从主流金融 APP 中获取。这些图片被分为六大常见类型: K 线图、技术指标图、表格、统计图、文档和混合图。为了丰富图片的风格,我们针对相同内容,分别采集了四种不同风格的图片,包括电脑截图、手机拍照、手机竖屏截图和手机横屏截图。具体流程如下图所示:
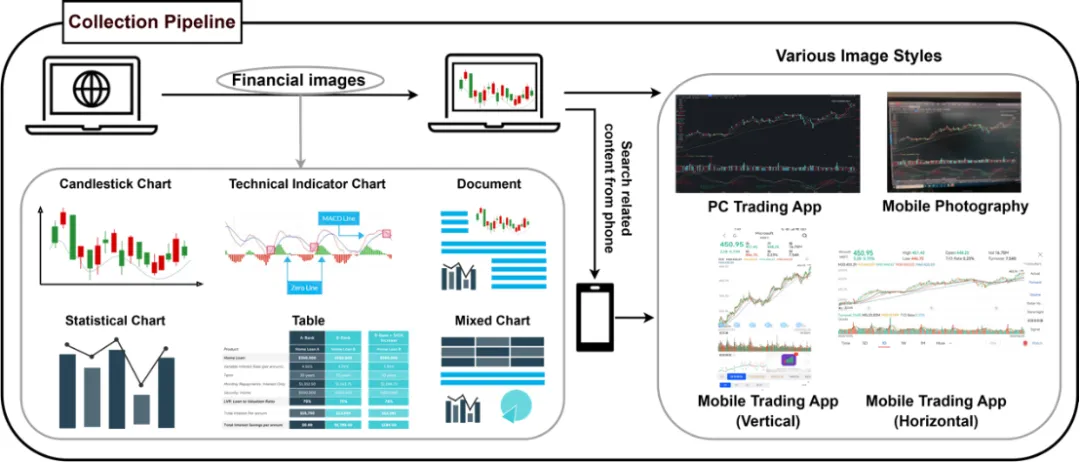
首先,标注人员通过电脑在APP中寻找合适的金融图片,并进行截图。然后,他们使用手机拍摄同一内容 (例如同一家公司的 K 线图),并分别进行竖屏和横屏的截屏。这一系列操作旨在保证图片风格的多样性。
各种图片类型及风格的数量如下图所示,图片类型中统计图的数量最多,混合图数量最少;图片风格中,电脑截图数量最多,手机竖屏截图数量最少。

❍问答对生成流程
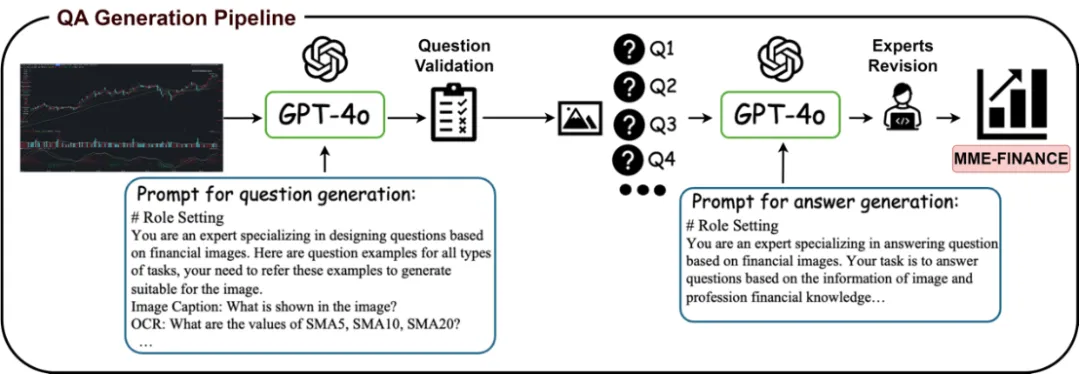
为了生成高质量的图片问题对,我们采用了一套结合 GPT-4o 与人工审核的标注流程。具体流程如下图所示:首先,我们将图片及生成问题的 prompt 输入 GPT-4o,以便其为每个任务生成相应的问题。这些生成的问题随后将经过人工审核,不合适的问题会被剔除或修改。经过筛选后的图片问题对及生成答案的 prompt,再次输入 GPT-4o,以获取初步的答案。接着,这些答案将由金融专家进行进一步的筛选和修正,最终形成高质量的数据集。
❍评估方式
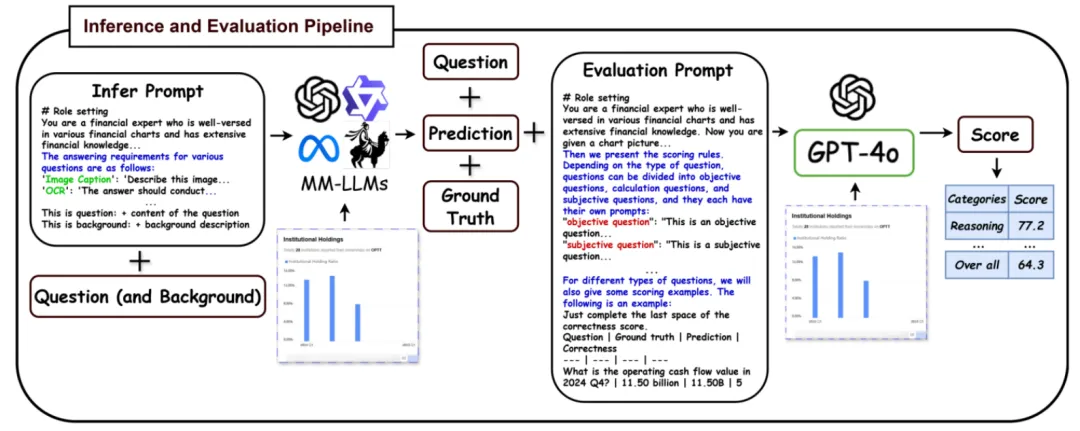
MME-Finance 的问题形式为开放类型,因此评估此类问题的答案相较于选择题类型更具挑战性。为此,我们设计了一整套流程,以提高评估的准确性。具体流程如下图所示:在模型推理过程中,我们对模型输出的形式进行了一定的限制,以便于后续的评估工作。我们采用大型模型进行评估,将问题、模型回答、标准答案、图片以及评估 prompt 一并输入评估模型。评估 prompt 中包含了每类任务的评估标准及相应的评估示例,以提升模型的评估精度。最终评估模型输出预测得分,评分范围为六级,从低到高依次为 0 至 5 分。经过实验验证,我们发现 GPT-4o 作为评估器,具有最高的人类一致性。
实验
❍结果分析
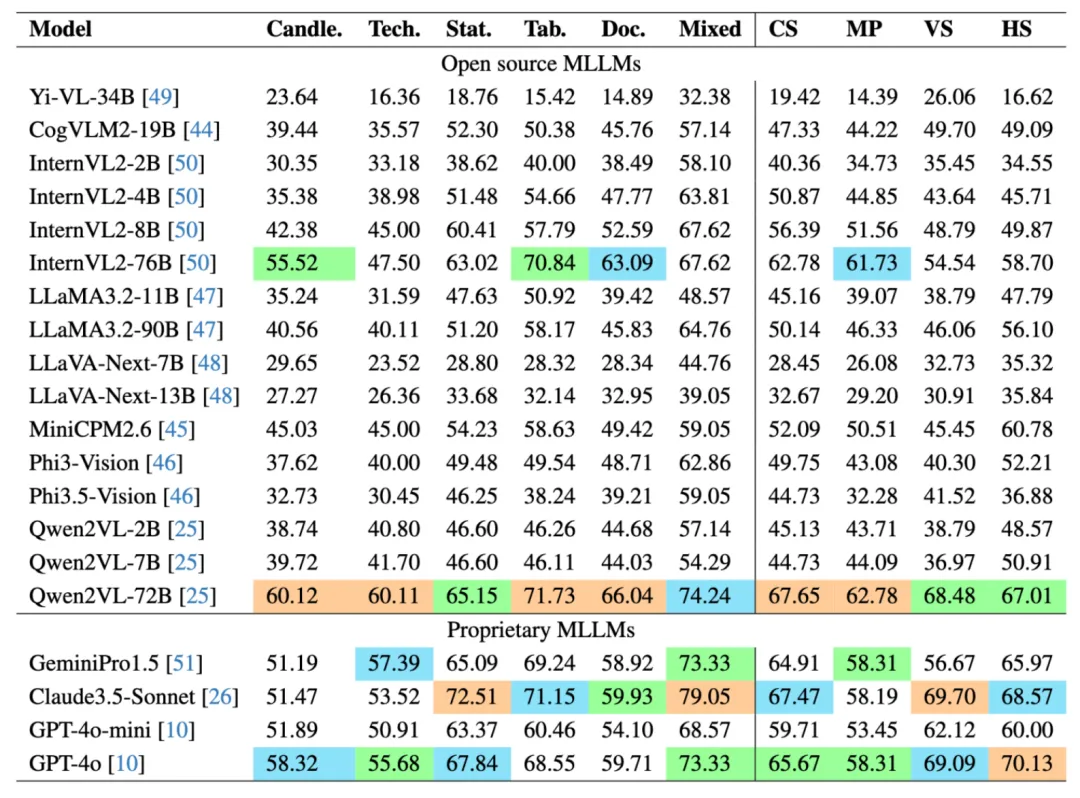
我们在 MME-Finance 上测试了 20 个多模态大模型的效果,既包含了常见的开源模型,如 Qwen 系列,LLaVA 系列等,也包含了 GPT-4o,Claude3.5-Sonnet 这种闭源模型。英文版本的实验结果如下图所示:
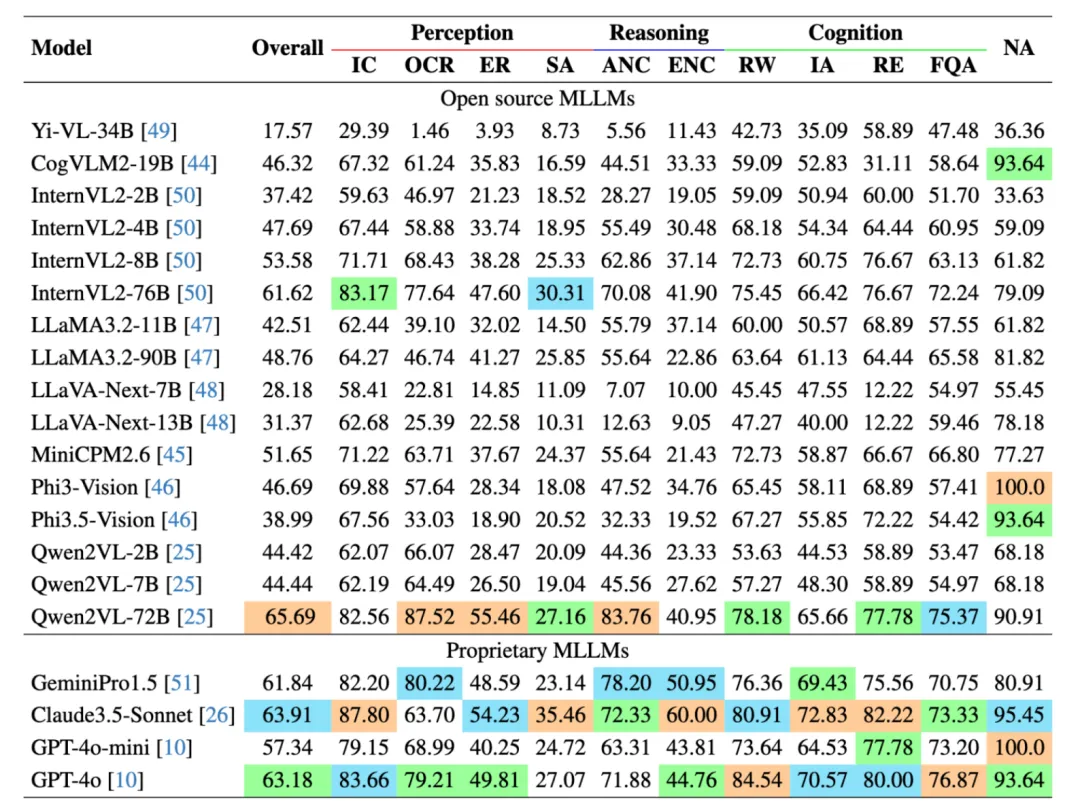
在所有模型中,Qwen2VL-72B 取得了最好的精度,其次是 Claude3.5-Sonnet 模型和 GPT-4o 模型。可以发现对于大部分模型,更大的参数量具有更好的效果。在感知能力上,许多模型在图片摘要 (Image Caption) 和OCR任务上具有较好的精度,说明当前的多模态大模型均具有一定的通用感知能力。但是大部分模型在空间感知 (SA) 任务上的效果较差。
下图展示了一个空间感知的样例,可以看到K线图中各个MA曲线粘合在一起,而问题是第一天哪条曲线数值最大,几个能力较强的模型都答错了。因此细粒度的感知对于当前多模态大模型是一个较大的挑战。
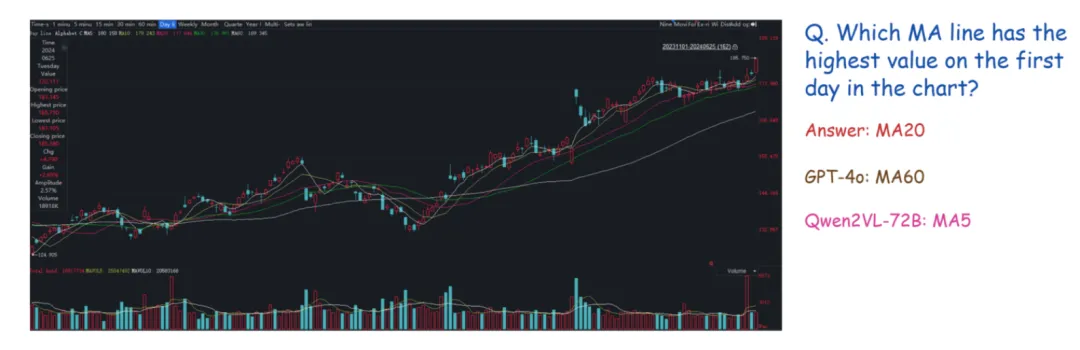
推理能力中,准确数值计算 (ANC) 任务的最高准确率为 83.76%,而估计数值计算 (ENC) 任务的最高准确率仅为 60.00%,这表明了当前模型在估计数值方面存在困难,因为进行数值估计时,需要模型具有较强的推理能力。在复杂认知能力上,Claude3.5 Sonnet 和 GPT-4o 在各个任务上效果较好。NA 任务考察了模型的幻觉问题,而在该任务上,Phi3-Vision 和 GPT-4o-mini 的精度反而最好。
各模型在不同类别和风格图片上的精度对比如下图所示。大部分模型在 K 线图和技术指标图上的表现相对较差,这主要是由于这些图像更加专业,视觉信息更加丰富,从而增加了大模型理解的难度。此外,在四种图片风格中,大部分模型在手机照片上的效果相对较差。这主要源于手机拍摄照片的清晰度较低,且拍摄角度也对评估结果产生了一定影响。
❍评估器研究

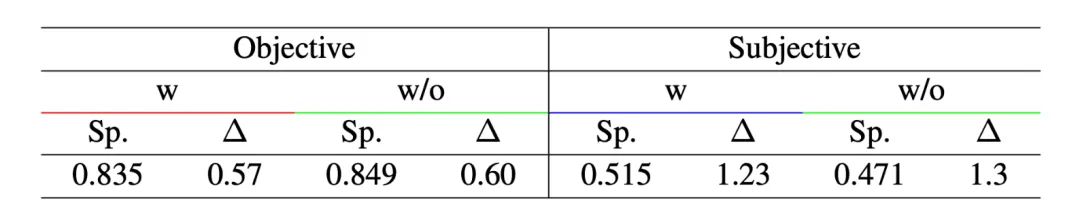
在使用大模型进行评估时,确保与人类评估结果的一致性是至关重要的。为此,我们开展了一系列实验。我们随机挑选了 100 个英文问题,并获得了 MiniCPM2.6 的预测结果。随后,三位专家对这些结果进行了评分,并综合得出最终分数。具体流程如下:当任意两位专家的评分差异超过 2 分时,该问答对将被进一步审核,以确定一个三位专家均认可的分数;而当评分差异小于 2 分时,则取众数或平均数作为最终评分。通过这种方法,我们得到了一个相对客观的整数评分。我们将此评分与模型的评估结果进行了对比,计算了斯皮尔曼相关系数及平均绝对误差。实验结果如表所示,GPT-4o 在斯皮尔曼相关系数和平均绝对误差方面均表现最佳,显示出最高的人类一致性。此外,开源模型 Qwen72B 也取得了良好的结果,因此可以作为 GPT-4o 的优秀替代选项。此外,我们发现,将图像信息融入多模态模型进行评估时,能够显著提升评估效果。为此,我们进行了进一步的实验,将 100 个问题分为客观题和主观题。结果显示,图像的加入对主观题的评估准确率提升效果更为显著。我们推测,这主要是因为主观题的答案在内容和形式上变化更大,因此多模态大模型评估器结合图像内容,能够进行更为全面和综合的评判。
总结
MME-Finance 是在金融领域建立双语多模态基准的开创性努力。它涵盖了一系列多样化的金融开放性问题,提出的挑战从基本的视觉理解到复杂的金融推理和专家级决策。此外,MME-Finance 提出了一种新颖的评估策略,以确保对多语言大模型 (MLLMs) 的准确评估。在 20 个多模态大模型的详细评估结果显示,现有的多模态大模型在处理复杂金融问题方面存在显著的局限性。MME-Finance 可以作为指导金融领域多模态大模型发展的重要基准。在未来,我们计划扩大数据规模和类型,整合多轮对话场景以及其他模态 (如视频、音频),以实现更全面的评估。
🤗 MME-Finance 链接:
https://hf.co/datasets/hithink-ai/MME-Finance
本文由 Hugging Face 中文社区内容共建项目提供,稿件由社区成员投稿,经授权发布于 Hugging Face 公众号。文章内容不代表官方立场,文中介绍的产品和服务等均不构成投资建议。了解更多请关注公众号:
https://hf.link/tougao
(文:Hugging Face)