

这是停不下了,小编还要过年啊,DeepSeek 刚刚发布了另一个开源人工智能模型 Janus-Pro-7B,它是多模态模型(可以生成图像),在 GenEval 和 DPG-Bench 基准测试中击败了 OpenAI 的 DALL-E 3 和 Stable Diffusion
重要的是,只有7B!普通电脑都能运行试试了!
主要特点与优势
Janus-Pro 的核心创新在于其 解耦的视觉编码 框架。传统的多模态模型通常将视觉编码功能同时用于理解和生成,这可能会导致性能瓶颈和任务冲突。Janus-Pro 通过将视觉编码解耦到不同的路径,克服了这一局限性,同时仍然采用 统一的 Transformer 架构 进行处理。
这种解耦设计带来了以下显著优势:
-
• 增强灵活性: 模型在理解和生成任务之间更加灵活,能够更好地适应不同的多模态应用场景
-
• 卓越性能: Janus-Pro 不仅超越了以往的统一模型,还在特定任务上达到了甚至超过了专门模型的性能水平
-
• 简洁高效: 模型架构的简洁性和高效性使其成为下一代多模态模型的理想选择
性能表现
Janus-Pro 在多项基准测试中的出色表现:
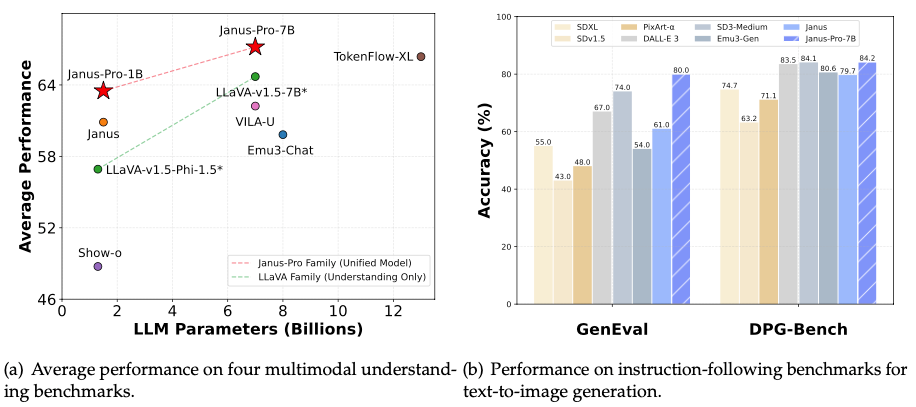
多模态理解基准 : 在多模态理解方面,Janus-Pro 家族模型表现出优异的平均性能,显著高于 LLaVA 家族等其他模型
-
文本到图像生成基准: 在 GenEval 和 DPG-Bench 基准测试中,Janus-Pro 7B 的准确率均超过 84%,与 SDXL、DALL-E 3 等知名模型处于同一水平,甚至更高
图像生成示例
Janus-Pro 及其前身 Janus 在文本到图像生成方面的对比。结果表明,Janus-Pro 在以下方面取得了显著提升:
-
• 更稳定的输出: 对于简短的提示词,Janus-Pro 能够生成更稳定的图像结果
-
• 更高的视觉质量: 生成的图像具有更高的清晰度和视觉吸引力
-
• 更丰富的细节: 图像细节更加丰富,更贴近文本描述
-
• 简单的文本生成能力: Janus-Pro 增加了生成简单文本的能力,例如示例中的 “Hello”

模型架构与技术细节
Janus-Pro 是一个统一的理解和生成多模态大型语言模型 (MLLM),它基于 DeepSeek-LLM-1.5b-base 或 DeepSeek-LLM-7b-base 构建
-
• 视觉编码器: 模型使用 SigLIP-L 作为视觉编码器,支持 384×384 像素的图像输入。
-
• 图像生成 Tokenizer: Janus-Pro 使用来自
https://github.com/FoundationVision/LlamaGen的 tokenizer,并采用 16 倍的下采样率。
快速开始与使用
提供了 GitHub 仓库的链接,用户可以访问仓库获取更详细的代码、使用指南以及模型下载地址
https://github.com/deepseek-ai/Janus?tab=readme-ov-file#janus-pro
许可与引用
Janus-Pro 的代码仓库采用 MIT 许可证,模型本身的使用受到 DeepSeek 模型许可证 的约束。
如果您在研究或应用中使用了 Janus-Pro 模型,按照以下格式进行引用:
@misc{chen2025januspro,
title={Janus-Pro: Unified Multimodal Understanding and Generatior},
author={Xiaokang Chen and Zhiyu Wu and Xingchao Liu and Zizheng F},
year=2025},
}
⭐
(文:AI寒武纪)