


在信息爆炸的时代,高效准确地获取所需信息成为了人们面临的一大挑战。传统的搜索引擎虽然在一定程度上满足了人们的搜索需求,但随着数据量的不断增长和用户需求的日益多样化,其局限性也逐渐显现。中国人民大学和清华大学联合推出的 Search – o1 作为一款创新的智能搜索工具,以其独特的技术和强大的功能,为用户带来了全新的搜索体验。
一、项目概述
Search – o1 是中国人民大学和清华大学联合精心研发的一款智能搜索工具,旨在解决传统搜索在准确性、效率和个性化方面的不足。它整合了先进的自然语言处理、机器学习和信息检索技术,能够理解用户的复杂查询意图,并从海量的信息源中快速准确地筛选出最相关的结果。与传统搜索引擎相比,Search – o1 在处理模糊查询、语义理解和个性化推荐等方面具有显著优势,能够为用户提供更加精准、高效的搜索服务。

1、自然语言处理
-
查询理解:Search – o1 利用先进的自然语言处理技术,对用户输入的查询语句进行深入分析。它能够识别关键词、短语和句子结构,理解查询的语义和意图。例如,当用户输入 “最近有哪些好看的科幻电影” 时,Search – o1 不仅能够提取出 “科幻电影” 这一关键词,还能理解用户对 “最近” 上映的电影感兴趣,从而更准确地筛选搜索结果。
-
语义匹配:通过语义匹配技术,Search – o1 能够将用户的查询与文档中的内容进行语义层面的对比,而不仅仅是简单的关键词匹配。它利用词向量模型和语义相似度算法,找到与查询语义最相近的文档,提高搜索结果的相关性。比如,对于 “人工智能在医疗领域的应用” 这一查询,Search – o1 能够找到那些虽然没有直接使用相同关键词,但在语义上表达了相关内容的文档。
2、机器学习
-
相关性排序:Search – o1 运用机器学习算法对搜索结果进行相关性排序。它通过分析大量的用户搜索行为数据和文档特征,训练模型来预测文档与查询的相关性程度。模型会考虑多种因素,如关键词的出现频率、位置、文档的权威性等,从而为每个搜索结果分配一个相关性得分,将最相关的结果排在前面。
-
个性化学习:为了提供个性化的搜索体验,Search – o1 会学习用户的搜索历史、点击行为和偏好信息。通过这些数据,模型能够了解用户的兴趣和需求,在搜索结果排序中优先展示符合用户个性化需求的内容。例如,如果用户经常搜索与旅游相关的信息,那么在搜索结果中,旅游相关的内容会得到更高的权重。
3、信息检索
-
分布式索引:Search – o1 采用分布式索引技术,将海量的文档数据分散存储在多个服务器上。这样可以提高索引的构建速度和查询效率,同时增强系统的可扩展性。当用户发起查询时,系统能够快速地从各个服务器上检索相关的索引信息,减少查询响应时间。
-
多源数据融合:为了提供更全面的搜索结果,Search – o1 整合了多种信息源,包括网页、新闻、学术论文、社交媒体等。它能够从不同类型的数据中提取有价值的信息,并将其融合到搜索结果中。例如,在搜索某个产品时,用户不仅可以看到相关的产品介绍网页,还能获取到该产品的新闻报道、用户评价等信息。
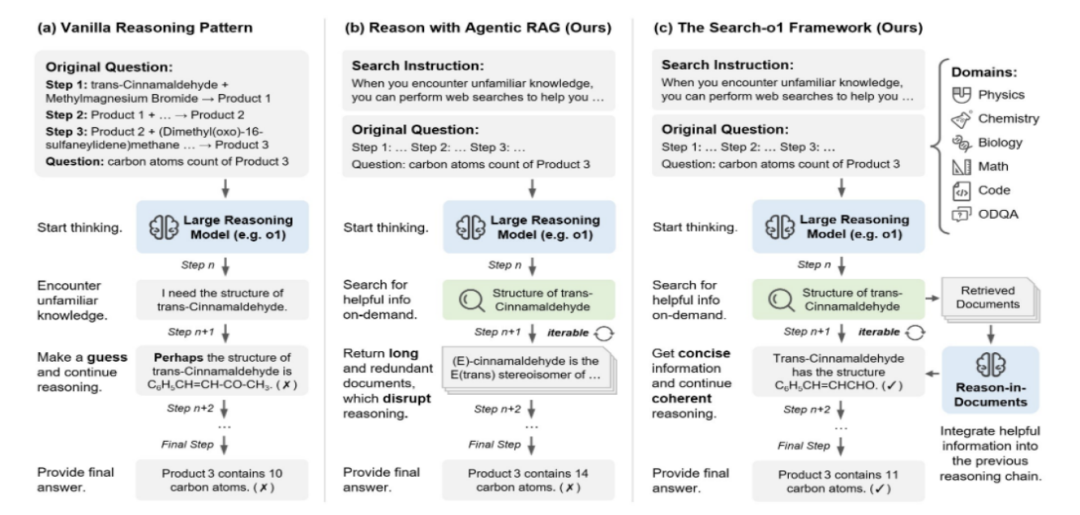
三、主要功能
1、智能语义搜索:Search – o1 支持智能语义搜索,能够理解用户查询的真实意图,即使查询语句存在模糊性或不完整性。例如,用户输入 “苹果”,它不仅能返回苹果公司相关的信息,还能根据上下文和用户历史,判断用户是否在查询苹果这种水果,从而提供更准确的结果。
2、个性化推荐:基于用户的搜索历史和偏好,Search – o1 提供个性化的搜索结果推荐。每次搜索时,系统会根据用户的个性化模型,调整搜索结果的排序,优先展示用户可能感兴趣的内容。这使得用户能够更快地找到符合自己需求的信息,提高搜索效率。
3、多模态搜索:除了文本搜索,Search – o1 还支持多模态搜索,包括图像搜索和语音搜索。用户可以上传一张图片,Search – o1 会识别图片中的内容,并返回相关的文本信息和其他相似图片。语音搜索功能则让用户通过语音输入查询内容,方便用户在不方便打字的情况下进行搜索。
4、实时搜索:Search – o1 具备实时搜索功能,能够及时获取最新的信息。无论是新闻资讯、社交媒体动态还是实时更新的数据库,用户都能在第一时间搜索到相关内容。这对于关注时事新闻、追踪热点事件的用户来说非常实用。
5、搜索结果摘要:为了帮助用户快速了解搜索结果的内容,Search – o1 会生成搜索结果摘要。系统会自动提取文档中的关键信息,以简洁明了的方式展示给用户,让用户在不打开文档的情况下就能大致了解其内容。
四、应用场景
1、学术研究
在学术研究领域,Search – o1 可以帮助研究人员快速找到相关的学术文献、研究报告和数据资料。其智能语义搜索和多源数据融合功能,能够涵盖多个学术数据库和文献平台,为研究人员提供全面的信息支持。例如,在研究某个特定领域的课题时,研究人员可以通过 Search – o1 搜索相关的关键词,获取到最新的研究成果和前沿动态。
2、商业决策
对于企业和商业人士来说,Search – o1 是一个强大的市场调研和竞争分析工具。它可以搜索到市场趋势、竞争对手信息、行业报告等内容,帮助企业制定战略决策。比如,企业在推出新产品前,可以通过 Search – o1 了解市场需求、竞争对手的产品特点和用户反馈,为产品的定位和营销策略提供参考。
3、日常生活
在日常生活中,Search – o1 可以满足用户各种信息需求。无论是查找旅游攻略、美食推荐、购物信息还是娱乐新闻,它都能提供准确的结果。例如,用户计划去某个城市旅游,通过 Search – o1 可以搜索到该城市的景点介绍、酒店推荐、交通信息等,方便用户制定旅行计划。
4、教育学习
在教育领域,Search – o1 可以辅助学生和教师进行学习和教学。学生可以通过它查找学习资料、解答疑惑,教师可以用它获取教学资源、了解教育动态。比如,学生在学习数学时遇到难题,可以通过 Search – o1 搜索相关的解题方法和例题,帮助自己理解和掌握知识点。
五、快速使用
1、安装与设置
# Create conda environmentconda create -n search_o1 python=3.9conda activate search_o1# Install requirementscd Search-o1pip install -r requirements.txt
2、数据准备
使用 data/data_pre_process.ipynb 中提供的代码将每个数据集预处理为我们的标准化 JSON 格式。我们使用的数据集分为两种类型:
1)Challenging Reasoning Tasks:
– PhD-level Science QA: GPQA
– Math Benchmarks: MATH500, AMC2023, AIME2024
– Code Benchmark: LiveCodeBench
2)Open-domain QA Tasks:
– Single-hop QA: NQ, TriviaQA
– Multi-hop QA: HotpotQA, 2WikiMultihopQA, MuSiQue, Bamboogle
要预处理数据集,请执行以下步骤:
-
打开 Jupyter 笔记本 data/data_pre_process.ipynb。
-
对于每个数据集,运行相应的预处理单元格,将原始数据转换为统一的 JSON 格式。
-
处理后的数据集将保存在 data/ 目录中。
3、模型推理
我们可以使用提供的脚本运行不同的推理模式。以下是如何执行每种模式的示例:
1)Direct Reasoning (Direct Generation)
python scripts/run_direct_gen.py \--dataset_name gpqa \--split diamond \--model_path "YOUR_MODEL_PATH"
2)Naive Retrieval-Augmented Generation (RAG)
python scripts/run_naive_rag.py \--dataset_name gpqa \--split diamond \--use_jina True \--model_path "YOUR_MODEL_PATH" \--jina_api_key "YOUR_JINA_API_KEY" \--bing_subscription_key "YOUR_BING_SUBSCRIPTION_KEY"
3)RAG with Agentic Search
python scripts/run_rag_agent.py \--dataset_name gpqa \--split diamond \--max_search_limit 5 \--max_url_fetch 5 \--max_turn 10 \--top_k 10 \--use_jina True \--model_path "YOUR_MODEL_PATH" \--jina_api_key "YOUR_JINA_API_KEY" \--bing_subscription_key "YOUR_BING_SUBSCRIPTION_KEY"
4)Search-o1
python scripts/run_search_o1.py \--dataset_name aime \--split test \--max_search_limit 5 \--max_turn 10 \--top_k 10 \--max_doc_len 3000 \--use_jina True \--model_path "YOUR_MODEL_PATH" \--jina_api_key "YOUR_JINA_API_KEY" \--bing_subscription_key "YOUR_BING_SUBSCRIPTION_KEY"
参数说明:
–dataset_name:要使用的数据集的名称(例如,gpqa、aime)。
–split:数据拆分以运行(例如,train、test、diamond)。
–model_path:预训练 LRM 模型的路径。
–bing_subscription_key:您的必应搜索 API 订阅密钥。
–max_search_limit:每个推理会话的最大搜索查询数。
–max_url_fetch:每次搜索要提取的最大 URL 数。
–max_turn:最大推理回合数。
–top_k:要检索的排名靠前的文档数。
–max_doc_len:每个检索到的文档的最大长度。
–use_jina:是否使用 Jina 进行文档处理。
–jina_api_key:用于 URL 内容获取的 Jina API 订阅密钥。
六、项目地址
官网地址:https://search-o1.github.io
开源地址:https://github.com/sunnynexus/Search-o1
论文地址:https://arxiv.org/abs/2501.05366
(文:小兵的AI视界)