
检索增强生成(RAG)因为能够有效控制大模型幻觉问题已成为当前LLM应用最热门的技术模式,利用一些编排框架可以快速构建一个知识问答类的原型应用。然而,令人沮丧的是,即使使用了RAG,构建了可信的知识库,但大模型仍然会因为上下文不准确,错乱,不完整等原因给出错误的答案。这些“幻觉”和不可靠性问题,正是阻碍当下AI应用难以真正上生产的拦路虎问题。
近日,谷歌研究人员的一项新研究《SUFFICIENT CONTEXT: A NEW LENS ON RETRIEVAL AUGMENTED GENERATION SYSTEMS》,为我们理解和解决这些问题提供了一个全新的视角——“充分上下文”(Sufficient Context)。这项研究不仅深刻剖析了RAG系统失败的根本原因,还提出了一套行之有效的解决方案,有望显著提升企业AI的准确性和可靠性。
RAG的困境
RAG系统的理想状态是:当提供给大语言模型(LLM)的上下文信息足以回答用户问题时,模型应输出正确答案;反之,当信息不足时,模型应选择“拒绝回答”或请求更多信息。
然而,现实远非如此。此前的研究常常笼统地将问题归咎于“检索质量不佳”或“上下文不相关”,但谷歌的论文指出,这种描述过于模糊。我们真正需要回答的核心问题是:LLM犯错,究竟是因为它没能理解上下文,还是因为上下文本身就不包含足够的信息?
为了精准地回答这个问题,研究团队提出了“充分上下文”的概念。
“充分上下文”是什么?

研究人员将输入给模型的“查询-上下文”对分为两类:
-
充分上下文(Sufficient Context):指提供的上下文中包含了回答用户查询所需的全部信息,模型能够据此给出一个明确的答案。 -
不充分上下文(Insufficient Context):指上下文缺少必要信息。这可能是因为信息不完整、存在矛盾,或者查询需要上下文中未包含的专业知识。
这一分类的关键优势在于,它在判断时不需要“标准答案”。这意味着,在无法提前获知正确答案的真实世界应用中,我们也能评估上下文的质量。
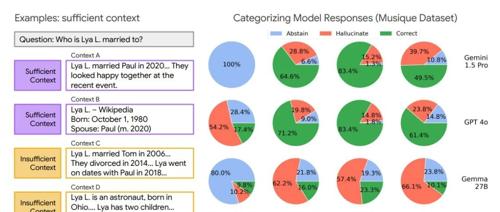
为了自动化这一分类过程,研究团队开发了一个基于LLM的“自动评估器”(Autorater)。实验证明,谷歌的 Gemini 1.5 Pro 模型仅通过一个示例(1-shot)的提示,就能以高达93%的准确率判断上下文是否充分,为大规模分析和应用奠定了基础。
三大关键发现:颠覆对RAG的传统认知
通过“充分上下文”这一新视角,研究人员对多种主流LLM(包括Gemini、GPT、Claude等)在不同数据集上的表现进行了深入分析,得出了几个重要的结论:
1. 即使上下文充分,模型依然会产生幻觉这是最令人警醒的发现之一。人们通常认为,只要检索到的信息是正确的、全面的,模型就应该能答对。但数据显示,即使在“充分上下文”的情况下,模型产生幻觉(给出错误答案)的频率仍然高于其选择“拒绝回答”。这表明,仅仅优化检索系统是远远不够的,LLM自身的推理和利用上下文的能力同样至关重要。
2. RAG有时反而会降低“谦逊度”,承认自己不知道。与直觉相反,引入RAG虽然提升了整体准确率,但也让模型在信息不足时更倾向于“强行回答”而非“承认不知”。研究人员推测:“这种现象可能是因为任何上下文信息的存在都会增加模型的自信心,从而导致其更倾向于产生幻觉,而不是拒绝回答。”
3. 即使上下文不充分,模型有时也能正确回答这是一个有趣的现象。研究发现,即使上下文信息不足,模型有时也能给出正确答案。除了模型自身的“参数化知识”(即预训练时学到的知识)外,研究人员还发现了其他原因:不充分的上下文有时也能起到“消除歧义”或“弥补知识鸿沟”的作用,帮助模型更好地理解问题并进行推理。
正如研究的共同作者、谷歌高级研究科学家 Cyrus Rashtchian 所说:“一个优秀的RAG系统,其基础LLM本身也必须足够强大。检索应被视为对其知识的‘增强’,而非唯一真相来源。”
如何减少幻觉?“选择性生成”框架应运而生
既然模型在信息不足时倾向于产生幻觉,我们如何引导它变得更“诚实”?研究团队提出了一种名为“选择性生成”(Selective Generation)的新框架。
该方法引入一个独立的、更小的“干预模型”,结合模型自身的置信度和上下文是否充分这两个信号,来决定主模型应该生成答案还是拒绝回答。
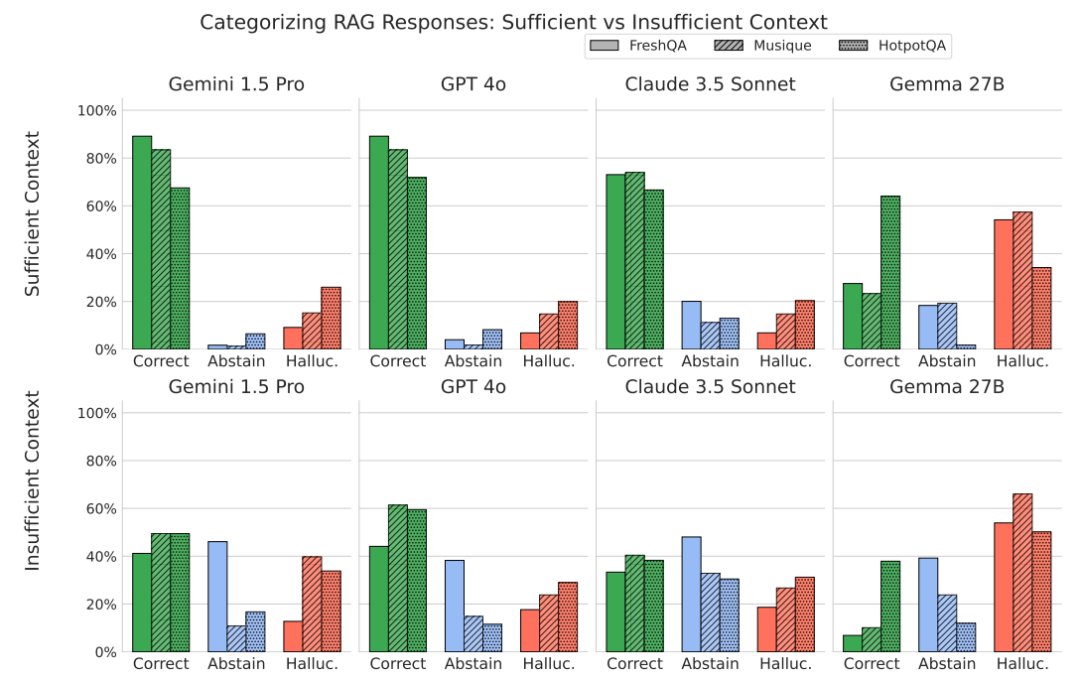
实验结果非常显著:该框架在不大幅牺牲回答覆盖率的前提下,将 Gemini、GPT 和 Gemma 等模型在回答问题时的正确率提升了2%至10%。
为了让这个提升更具实感,Rashtchian举了一个客户支持的例子:“想象一个客户询问是否有折扣。如果检索到的上下文是关于当前正在进行的促销活动,模型可以自信回答。但如果上下文描述的是几个月前的旧活动,或者附带复杂的条款,那么模型最好回答‘我不确定,请联系人工客服以获取更具体的信息’。”“选择性生成”框架正是为了实现这种智能的判断。
此外,研究团队也尝试了通过微调(fine-tuning)来教模型“拒绝回答”,即在训练数据中将不充分上下文样本的答案替换为“我不知道”。但结果好坏参半,虽然模型的正确率有所提高,但幻觉问题依然严重。
给企业团队的实践指南
对于希望将这些洞见应用到自有RAG系统中的企业团队,Rashtchian 提出了一个切实可行的四步法:
-
收集数据:收集一批能代表生产环境中真实情况的“查询-上下文”数据对。 -
自动标注:使用LLM自动评估器(Autorater)将这些样本标记为“充分”或“不充分”。 -
诊断检索系统:分析标注结果。Rashtchian建议:“如果‘充分上下文’的比例低于80%-90%,那么你的检索系统或知识库就有很大的改进空间。这是一个非常好的可观察指标。” -
分层评估模型:分别评估模型在“充分上下文”和“不充分上下文”两类数据上的表现,而不是看一个总的平均分。Rashtchian指出:“这能帮你发现那些在整体数据中被掩盖掉的重要但处理不佳的查询。”
虽然运行自动评估器会带来一些计算成本,但Rashtchian表示,对于几百到一千个样本的离线诊断来说,成本相对较低。其核心价值在于,它为团队提供了一个超越传统“相似度分数”的、更深刻的洞察信号。
小结
谷歌的“充分上下文”研究,指出了RAG系统失败的复杂性——问题不仅在于检索,更在于模型如何处理和判断所获得的信息。他们的关键发现及“选择性生成”等创新方法,给致力于让RAG应用投入生产的开发者来讲,有非常大的启发意义。
参考:https://arxiv.org/pdf/2411.06037
公众号回复“进群”入群讨论。
(文:AI工程化)