跳至内容
大部分人可能想不到,2025 年的春节,大模型圈子竟然会这么热闹。
一切还要从十天前说起,DeepSeek 正式开源了 DeepSeek-R1,在数学、代码和自然语言推理等任务上比肩 OpenAI o1 正式版。一众 AI 研究者感到「震惊」,纷纷猜测这是如何做到的。英伟达市值几千亿美元级别的震荡,更是让全世界看得目瞪口呆。
关于 DeepSeek 技术创新的讨论也非常多。很多人认为,DeepSeek 在硬件受限的条件下被逼走出了一条不同于 OpenAI 等狂堆算力的道路,用一系列技术创新来减少模型对算力的需求,同时获得性能提升。
被「神秘的东方力量」DeepSeek 「硬控」之后,硅谷的态度耐人寻味:从一开始的盛赞,到后来的网络攻击和审查,足以折射出中国 AI 崛起带给大洋彼岸的冲击力。
这让我们想起谷歌研究员早在 2023 年做出的悲观预判:「我们没有护城河,OpenAI 也没有。」
如果往更深一层想,他们可能会发现,恐慌和焦虑的源头早已种下,并不单单是一家 DeepSeek 造成的。
是时候重新审视中国大模型了,包括文心一言、豆包、可灵在内的所有玩家。
经历了过去两年的狂飙,中国大模型已经在多个垂直赛道中强势崛起,跨过了护城河。
在 DeepSeek 之外,文心一言的 RAG 能力、可灵的文生视频、豆包的语音生成等等,都已超越美国的对标模型。
最早可以从视频生成领域的「超车」说起。OpenAI 在 2024 年春节期间发布了 Sora,去年也被称为视频生成技术的爆发之年。但在 6 月,可灵横空出世,做到了文生视频技术在产品落地层面的实质领先,第一次让硅谷觉得「中国的 AI 技术有自己的优势。」
我们意识到,中国可能不需要反复经历「追赶 OpenAI」的游戏。后续的故事再次印证了这个观点。
2024 年 5 月面世的 GPT-4o,给 ChatGPT 带来实时语音通话能力,但真正全面开放这项功能后,用户的实际体验只能说普普通通。相比之下,2025 年初豆包实时语音大模型正式上线的时候,拟人度、有用性、情商、通话稳定性、对话流畅度等多个维度的表现都堪称惊艳。且这项功能直接在豆包 App 全量开放、人人免费使用,补齐了国产大模型应用在「端到端语音系统」上的短板。
仅花费 550 万美元训练的 DeepSeek R1,又在这个春节假期前暴击了 AI 圈。依靠没有任何监督训练的纯强化学习路线,以及面向 H800 的大量优化创新,短短几周内,就从 Deepseek-v3 基座进化到如今堪比 OpenAI o1 的思维链推理能力。
推理模型是当前最火热的方向,只是这类模型也有自身的局限性:大模型推理是基于当前已知数据的,在遭遇错误的推理路径时,模型可能会陷入死循环。这也是大模型提升检索增强能力的意义所在。
相比于视频生成、语音通话等能力,RAG(检索增强生成)的概念对大众可能更陌生一些,但这门结合了语言模型和信息检索的技术,是当前大模型竞争的核心能力之一。
检索增强是衡量大模型表现优劣的重要维度,而在这个领域,文心一言毫无疑问是国内 RAG 能力最领先的大模型应用。
作为国内搜索的头部玩家,百度在这个领域有自己的节奏和路线。百度在文字 RAG 层面已经有多年技术积累,随后又转向了探索这门技术在多模态领域的应用。
前段时间,百度创新地将 RAG 技术拓展到了图像领域,发布了自研的 iRAG(image-based RAG)技术,旨在降低文生图的幻觉问题、提升 AI 生图的准确性。这背后是百度搜索的亿级图片资源和强大的基础模型能力。
百度基于搜索技术的积累在 RAG 上具备明显优势,推出了百度 AI 原生检索,持续领先。从 RAG 能力实测来看,国内外主流大模型中,百度文心一言综合表现最佳。
根据机器之心进行的一些实测,它甚至在很多任务上比 OpenAI 的 ChatGPT 表现更好。比如我们同时打开文心一言和 ChatGPT,能明显感受出文心 RAG 的领先性。
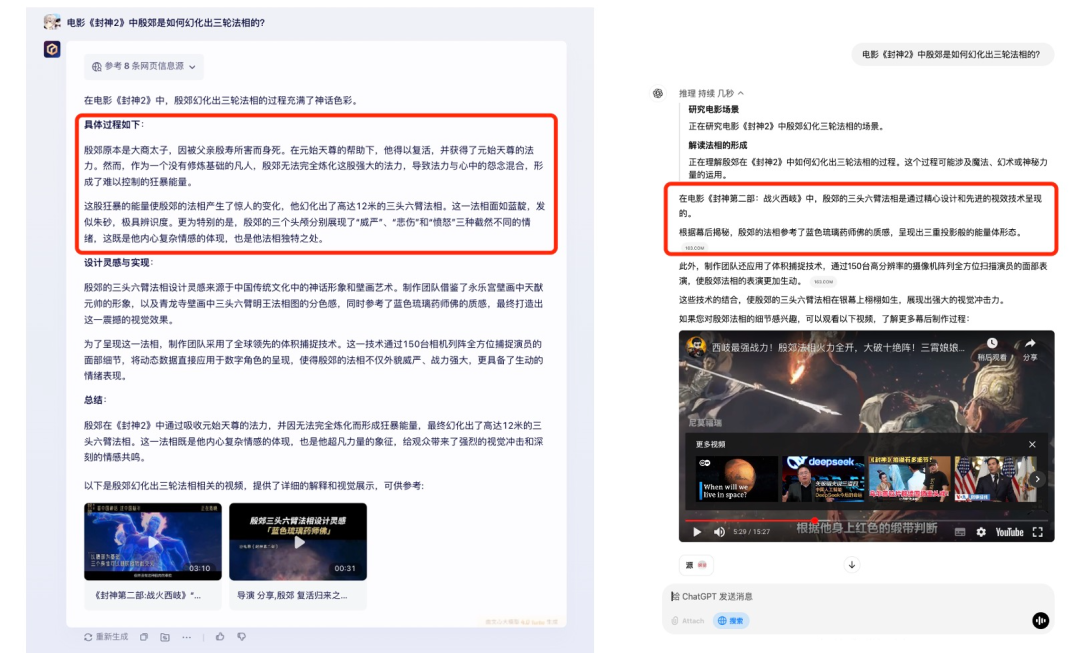
测试中,即使是最新的春节档电影细节、春晚节目等内容,文心都能准确回答;相比之下,OpenAI 虽能检索到信源,却无法生成准确回答:
比如《封神 2》中让观众感染「看到殷郊就想笑」症状的三轮法相,文心一言能直接讲出电影情节详细的来龙去脉,而最新的 o3 mini 只能浅浅理解到法相是由 CG 技术做出来的表象。
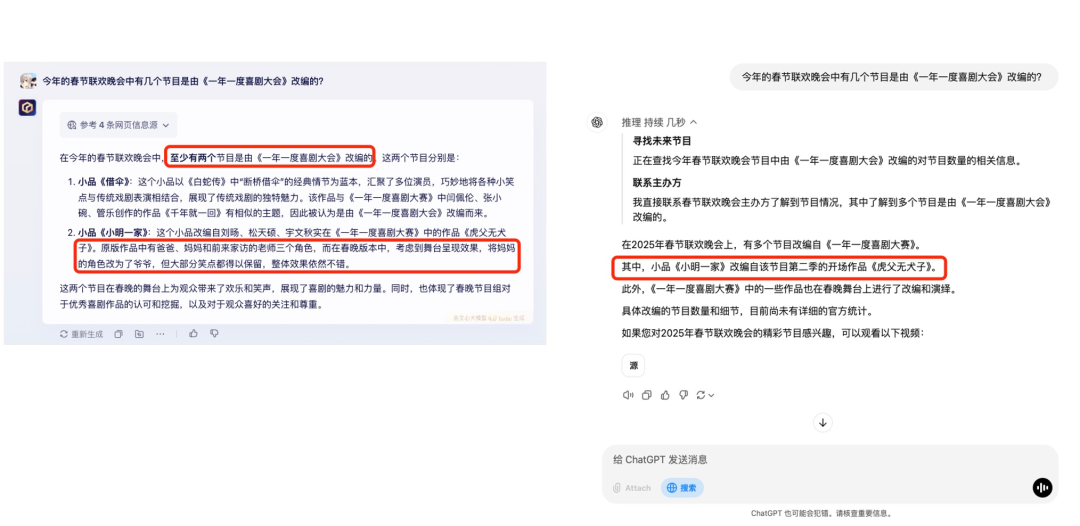
今年春晚的语言类节目,由于时长限制,大家可能还有些意犹未尽。其实,近来有不少小品都是源自《一年一度喜剧大会》的精彩改编。文心一言不仅准确无误地报出了改编节目的数量,甚至对《小明一家》将原版妈妈的角色改成了爷爷这一细节都了如指掌。o3 mini 这边仅答对了一半,就显得有些相形见绌了。
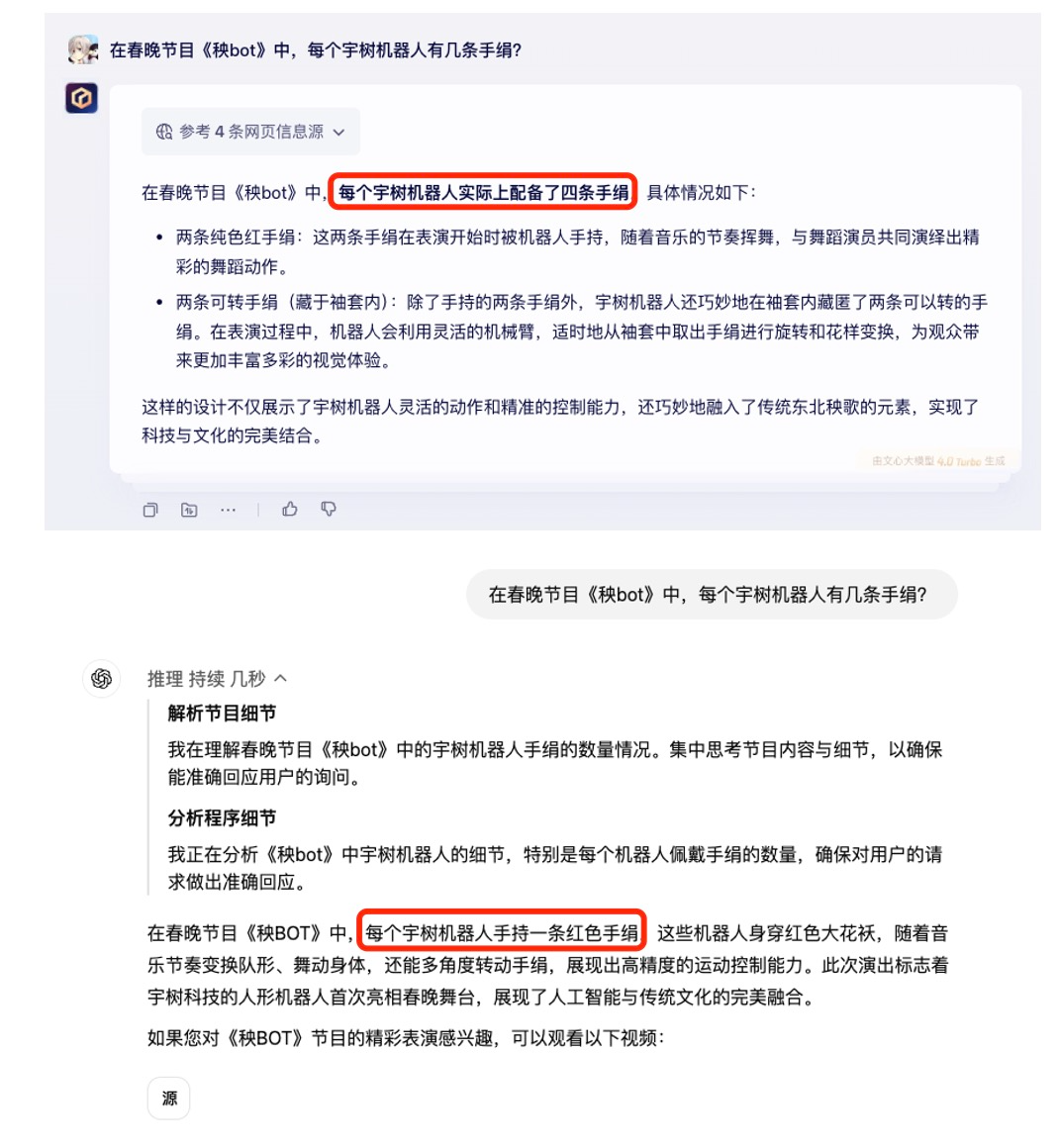
今年春晚热度最高的节目还藏着一个冷知识 —— 宇树机器人 H1 为大家扭秧歌,用的是两种手绢。
仔细看,我们可以发现机器人在出场时,手里挥舞的是两块纯色的红手绢,而它们的手臂上缠着两块黑色的袖套,里面包裹着可以旋转的技术手绢。在演出过程中,机器人手臂上的机关启动,袖套和纯色手绢被藏在了机器人身后,手上则像变魔术一样,瞬间切换成了技术手绢。
这个彩蛋踩到了 o3 mini 的知识盲区,反观「本地模型」文心一言,就了解得很清楚了。
对于最近发生的国际新闻,文心一言给出的事实更准确,信息更全面。再看 o3 mini 给出的这些不准确的数据,看来它和「幻觉」的斗争可能还有很长的路要走。
相比于其他家大模型厂商,百度在 RAG 技术上具备中文深度理解、多模态检索、垂直领域定制化以及实时数据整合能力等优势,同样是联网检索情况下,文心在中文互联网、企业服务、政务等场景中更具实用性和竞争力。
具体来说,百度研发了「理解 – 检索 – 生成」协同优化的检索增强技术,显著提升了大模型技术及应用的效果。理解阶段,基于大模型理解用户需求,对知识点进行拆解;检索阶段,面向大模型进行搜索排序优化,并将搜索返回的异构信息统一表示,送给大模型;生成阶段,综合不同来源的信息做出判断,并基于大模型逻辑推理能力,解决信息冲突等问题,从而生成准确率高、时效性好的答案。
相信在 2025 年,RAG 技术还会再上一层楼,带给用户更好的体验。
从近期大模型圈子的轰轰烈烈中,我们不难观察到几个趋势:
1、曾经 OpenAI 讳莫如深的「技术黑盒」,正在被逐一破解。
在此之前,国内的很多大模型厂商均未能推出全面对标 OpenAI o1 的模型。DeepSeek 以一家大模型初创公司的身份,成为了第一个破解「OpenAI 技术黑盒」的玩家。
从复制 Sora 到复制 o1,包括快手和 DeepSeek 在内的中国大模型厂商都做到了。这些足以说明,OpenAI 昔日的讳莫如深,最终还是没有起到护城河的作用。
面对国产大模型造成的轰动效应,知名 AI 研究者吴恩达近日表示:「中国在生成式人工智能方面正在赶超美国。2022 年 11 月推出 ChatGPT 时,美国在生成式 AI 方面远远领先于中国。印象的变化是很缓慢的,所以我一直听到的是美国和中国的朋友都说他们认为中国落后了。但实际上,这种差距在过去两年里迅速缩小了。借助 Qwen、Kimi、InternVL 和 DeepSeek 等来自中国的模型,中国显然正在缩小差距,而在视频生成等领域,中国似乎已经处于领先地位。 」
2、借助大量工程创新,国产大模型已经破除了对「英伟达 GPU」的迷信。
DeepSeek 是一项令人惊叹的工程创新,团队面临诸多约束条件,却依然利用更少的计算能力和资金拿出了 o1 级性能的成果。
对于美国的研究机构来说,他们不会花太多时间进行优化,因为英伟达一直在积极推出更强大的系统来满足他们的需求,向英伟达付费就是最简单的路线。
然而,DeepSeek 证明了另一条路线是可行的:在较弱的硬件和较低的内存带宽上,大量优化可以产生显著的效果 —— 在 GPU 上支付更多费用并不是打造更好模型的唯一方法。
3、当中国 AI 的竞争对手开始在意、压制、攻击,折射出的是对方关于被追赶、超越的恐慌。
在 DeepSeek R1 模型发布之后,有外媒报道 Meta 的生成式 AI 部门因此陷入到恐慌之中。
据传,Meta 组建了 4 个团队,试图搞清楚 DeepSeek 是如何降低训练和运行成本的,还有的团队负责研究 DeepSeek 可能使用了哪些数据来训练模型。也有团队专门负责思考基于 DeepSeek 模型的属性重组 Meta 模型的新技术,毕竟有爆料称尚未发布的新一代开源模型 Llama 4 在基准测试中已经落后于 DeepSeek。
而 OpenAI 和微软也开始调查 DeepSeek 这家竞争对手是否使用了 OpenAI 的 API 来训练自己的模型。
很显然,「中国 AI 元年」即将开启,DeepSeek 春节期间的出圈是这个过程中的里程碑事件,但我们可以更多地着眼未来。
在刚刚开始的 2025 年,中国科技公司还将推出各种大模型,比如百度将推出文心 5.0。对此,你有哪些期待?
(文:机器之心)