

在当今人工智能领域,长视频理解一直是一个具有挑战性的难题。尽管大型视频语言模型(LVLMs)在短视频理解方面取得了一定的成果,但在处理长视频时,由于上下文窗口的限制,其性能往往会显著下降。近期,厦门大学和罗切斯特大学联合推出的Video-RAG技术在长视频理解领域取得了重大突破,为解决这一难题提供了一种高效且实用的解决方案。
一、项目概述
Video-RAG是由厦门大学和罗切斯特大学联合推出的一种用于长视频理解的检索增强生成(Retrieval-Augmented Generation)技术。它通过提取视频中的视觉对齐辅助文本,帮助大型视频语言模型(LVLMs)更好地理解和处理长视频内容。具体来说,Video-RAG使用开源工具从视频数据中提取音频、文字和对象检测等信息,将这些信息作为辅助文本与视频帧和用户查询一起输入到现有的LVLM中,从而增强模型对长视频的理解能力。
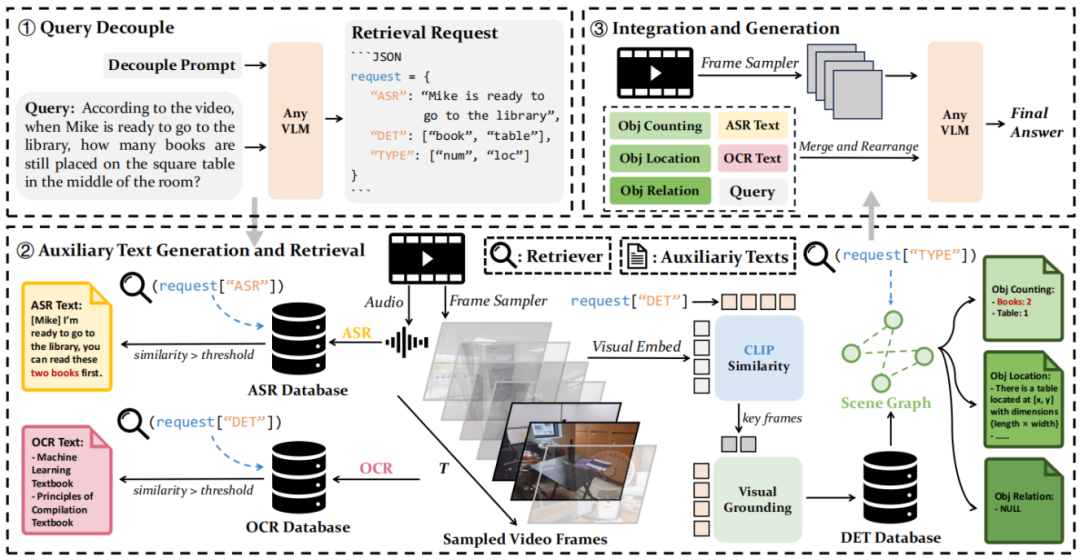
二、技术架构
1、查询解耦:用户的查询被分解为检索请求,用于从目标视频中提取三类不同的辅助文本,在这个阶段,LVLM仅处理文本信息,不访问视频帧,输出请求格式为json。
2、辅助文本生成与检索:包括光学字符识别(OCR)数据库,使用EasyOCR模型从每个采样视频帧中提取文本,并使用Contriever模型将其编码为文本嵌入,存储在Faiss索引中,用于通过RAG技术进行检索;自动语音识别(ASR)数据库,使用Whisper模型从视频中提取音频转录文本,并将其编码为向量数据库;对象检测(DET)数据库,使用APE模型从关键帧中提取对象类别和位置信息,并使用场景图预处理对象信息,构建更连贯的文本表示。
3、整合与生成:将检索到的辅助文本与用户查询和视频帧一起输入LVLM,生成最终响应。Video-RAG利用开源工具从纯视频数据中提取视觉对齐的辅助文本,增强了LVLMs的能力,而辅助文本的输入可以促进跨模态对齐,同时减少模态之间的差异。
三、优势特点
1、即插即用:可以无缝集成到任何开源LVLM中,无需对模型进行大规模的修改和调整,方便用户根据自己的需求选择合适的LVLM进行集成,降低了使用门槛和开发成本。
2、资源友好:在video-mme基准上,平均每个问题仅需增加约2000个token,相比其他方法,大大减少了对计算资源和存储资源的需求,使得在处理长视频时更加高效和经济。
3、性能优异:在多个基准测试中实现性能提升,并且可达到商业级模型(例如gemini-1.5-pro)的性能,能够准确地理解长视频内容并生成高质量的回答,为长视频理解提供了可靠的技术支持。
4、多模态信息提取:支持光学字符识别、自动语音识别和对象检测等多模态信息提取,能够从视频中获取更丰富的上下文信息,进一步提高了长视频理解的准确性和全面性。
四、性能评估
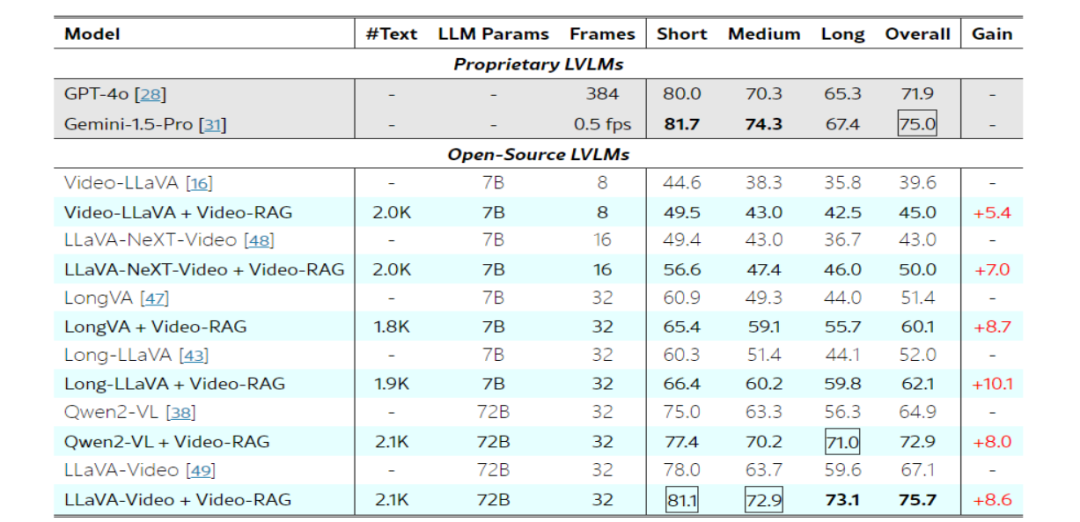
研究人员在 Video-MME、MLVU 和 LongVideoBench 等多个长视频理解基准数据集上对 Video-RAG 进行了评估。实验结果表明,在 7B 和 72B 的多个 LVLM 上应用 Video-RAG 时,均能取得显著的性能提升。例如,在 Video-MME 基准测试中,使用 72B LLaVA-Video 的 Video-RAG 性能优于 Gemini-1.5-Pro,六个 LVLM 的平均性能提升了 8.0%,尤其在长视频上有显著提升;在 MLVU 的多项选择任务中,7B 模型取得了优于 32B Qryx-1.5 模型的性能,72B LLaVA-Video 也有性能提升;在 LongVideoBench 评估中,72B LLaVA-Video 与 Video-RAG 在验证集上的总体性能超过 Gemini-1.5-Pro,7B LLaVA-Video 也有性能增强。
五、应用场景
1、视频问答系统:能够帮助用户快速准确地获取长视频中的信息,例如在教育视频中,学生可以通过提问获取视频中特定知识点的详细解释;在视频平台上,用户可以对视频内容进行提问,获取更深入的理解。
2、视频内容分析:可用于视频的自动标注、分类、摘要生成等任务,提高视频内容管理的效率和准确性。例如,媒体公司可以利用Video-RAG对大量的视频素材进行快速分析和标注,方便后续的内容创作和推荐。
3、教育培训:为在线教育提供了更智能的视频理解和交互功能,教师可以通过Video-RAG制作更具互动性的教学视频,学生可以在观看视频的过程中随时提问并获得及时的解答,提高学习效果。
4、娱乐媒体创作:在视频剪辑、特效制作等方面,Video-RAG可以帮助创作者更好地理解视频内容,提取关键信息,从而更精准地进行创作和编辑,提高创作效率和质量。
5、企业内部知识管理:企业可以利用Video-RAG对内部的培训视频、会议视频等进行管理和分析,方便员工快速获取所需的知识和信息,提高企业内部的知识共享和利用效率。
六、本地部署
本项目基于 LLaVA-NeXT 进行构建,以下是在本地部署 Video-RAG 的详细步骤:
1. 克隆并构建 LLaVA-NeXT conda 环境:
执行以下命令克隆 LLaVA-NeXT 仓库并进入该目录:
git clone https://github.com/LLaVA-VL/LLaVA-NeXTcd LLaVA-NeXT
创建名为 llava 的 conda 环境并激活:
conda create -n llava python=3.10 -yconda activate llava
升级 pip 并安装相关依赖:
pip install --upgrade pip # 启用 PEP 660 支持pip install -e ".[train]"
在 llava 环境中继续安装其他必要的包:
pip install spacy faiss-cpu easyocr ffmpeg-pythonpip install torch==2.1.2 torchaudio numpypython -m spacy download en_core_web_sm# 可选:pip install https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.0.0/en_core_web_sm-3.0.0.tar.gz
2. 克隆并构建 APE 的 conda 环境:
执行以下命令克隆 APE 仓库并进入该目录:
git clone https://github.com/shenyunhang/APEcd APE
安装 APE 的依赖:
pip3 install -r requirements.txtpython3 -m pip install -e.
3. 复制文件:
将 `vidrag_pipeline` 目录下的所有文件复制到 LLaVA-NeXT 的根目录下。
将 `ape_tools` 目录下的所有文件复制到 APE 的 `demo` 目录下。
4. 启动 APE 服务:
在 APE 项目的 `demo` 目录下运行以下命令启动服务:
python demo/ape_service.py5. 运行 Video-RAG 管道
在完成上述步骤后,可以通过运行以下命令使用基于 LLaVA-Video-7B 的管道:
python vidrag_pipeline.py如果要在其他 LVLMs 中使用该管道,需要对 `vidrag_pipeline.py` 进行一些修改:
七、结论与展望
Video-RAG作为一种创新的长视频理解技术,通过检索增强生成和多模态信息提取等技术手段,为长视频理解提供了一种高效、轻量级且性能优异的解决方案。它在多个应用场景中展现出了巨大的潜力,能够为用户提供更智能、更便捷的长视频理解和交互体验。然而,目前Video-RAG仍然存在一些局限性,例如在处理超长时间视频时可能会面临性能下降的问题,对于一些复杂的视频内容理解还不够深入等。未来,随着技术的不断进步,可以进一步优化Video-RAG的技术架构,提高其性能和效率;同时,可以结合更多的模态信息和先进的算法,进一步提升长视频理解的能力和水平,为长视频理解领域带来更多的创新和突破。
八、项目地址
论文:https://arxiv.org/abs/2411.13093
代码:https://github.com/leon1207/video-rag-master
项目网站:https://video-rag.github.io/
(文:小兵的AI视界)