DeepSeek官推发布了最新技术成果NSA:一种面向硬件且支持原生训练的稀疏注意力机制,专为超快长上下文训练与推理设计,并且梁文锋也挂名参加了~
NSA的核心组成:
-
动态分层稀疏策略
-
粗粒度的token压缩
-
细粒度的token选择
💡 NSA针对现代硬件进行了优化设计,显著提升了推理速度,并有效降低了预训练成本——同时不损失性能。在通用基准测试、长文本任务和基于指令的推理任务中,NSA的表现均能达到甚至超越传统全注意力模型的水平。
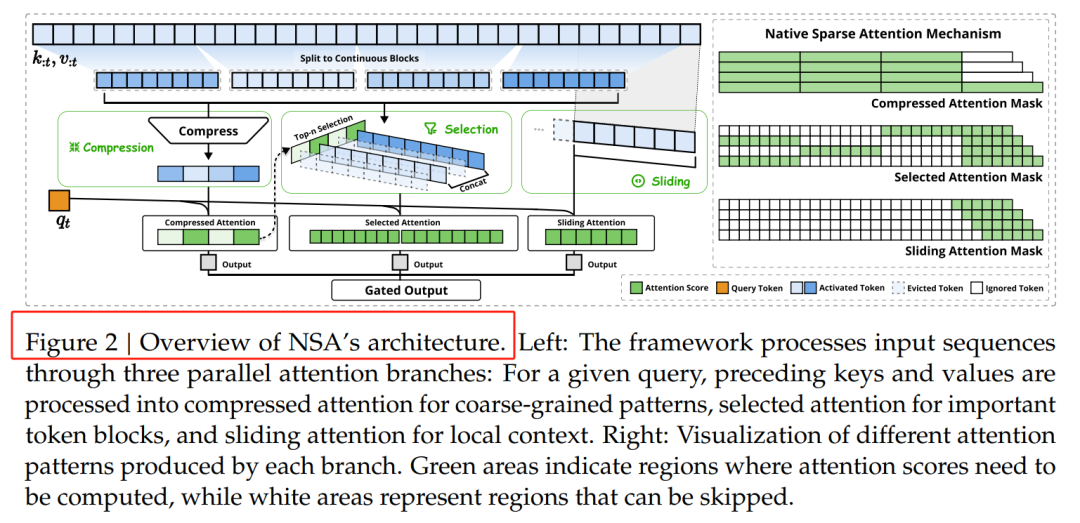
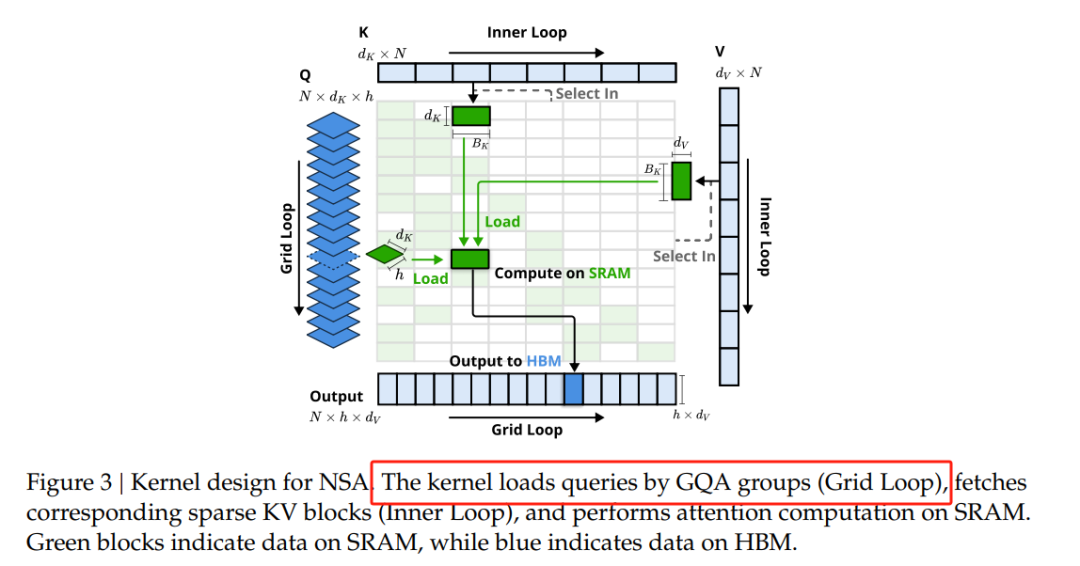
NSA的核心之一是动态分层稀疏策略,它结合了粗粒度的Token压缩和细粒度的Token选择。这种策略通过分层处理,既保证了模型对全局上下文的感知能力,又兼顾了局部信息的精确性。具体来说,NSA通过三个并行的注意力分支处理输入序列:压缩注意力、选择注意力和滑动窗口注意力。这种设计使得模型能够在不同粒度上捕捉信息,同时显著降低计算量。
粗粒度Token压缩是NSA优化计算效率的关键技术之一。它通过将多个相邻的Token合并为一个“超级Token”,减少了处理单元的数量,从而降低了计算量。NSA采用基于信息熵的方法,优先合并信息量较低的Token,最大限度地减少信息损失。例如,在处理新闻文章时,模型可以将常见的词汇组合(如“的”“是”等)合并为一个超级Token,而保留关键的名词和动词。这种压缩方式不仅提高了推理速度,还减少了存储需求。
在粗粒度压缩的基础上,NSA进一步引入了细粒度Token选择机制。这一机制允许模型在压缩后的“超级Token”中,根据任务需求动态选择关键的子单元进行进一步处理。这种动态选择机制类似于“二次筛选”,确保了模型在压缩过程中不会丢失关键信息。例如,在处理问答任务时,模型可以优先选择与问题相关的Token进行处理,而在生成文本时,则可以关注那些与上下文连贯性相关的Token。这种动态性不仅提高了模型的灵活性,还进一步优化了推理效率。
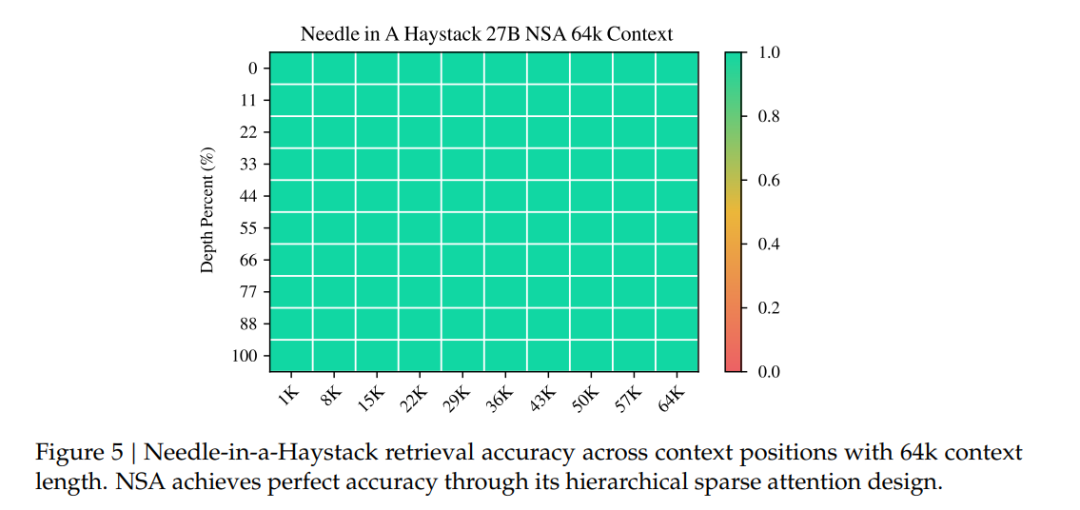
在长文本建模方面,NSA展现了其强大的能力。在64k上下文长度的“大海捞针”测试中,NSA实现了完美的检索准确率。
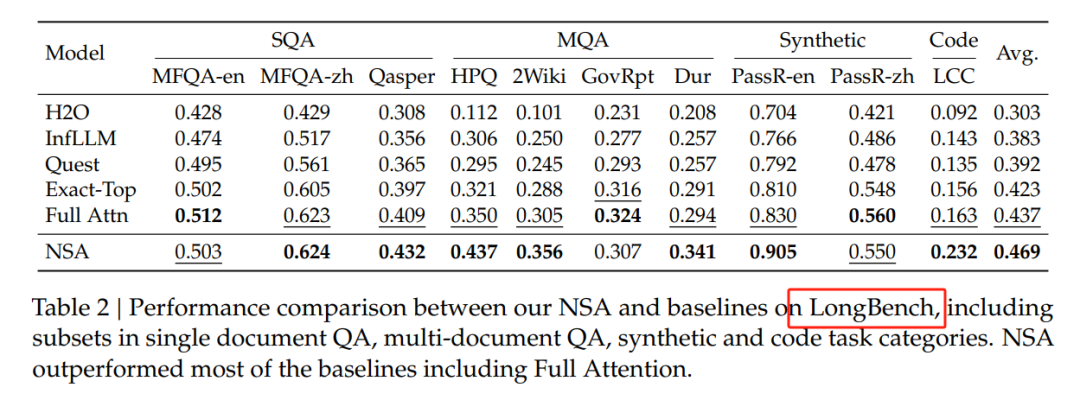
在LongBench基准测试中,NSA获得了最高平均分数0.469,优于所有基线,包括全注意力机制。
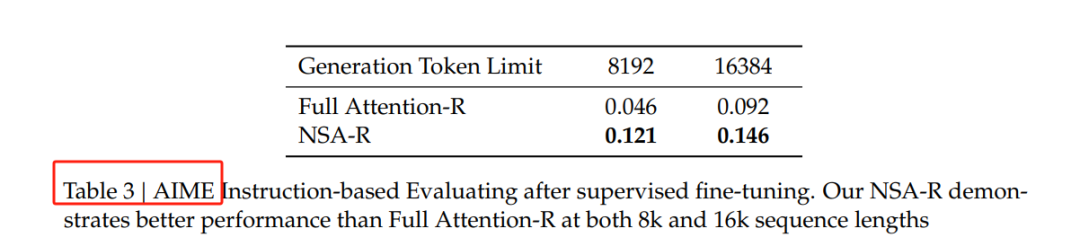
在思维链推理任务中,NSA同样表现出色。研究人员通过从DeepSeek-R1进行知识蒸馏,使用100亿个32k长度的数学推理轨迹进行监督微调,生成了两个模型:全注意力模型和NSA稀疏变体。
在AIME 24基准测试中,NSA稀疏变体在8k上下文设置下比全注意力模型高出0.075的准确率,并在16k上下文中保持了这一优势。这表明NSA能够高效捕获长距离逻辑依赖关系,并在推理深度增加时保持足够的上下文密度。
效率性能分析
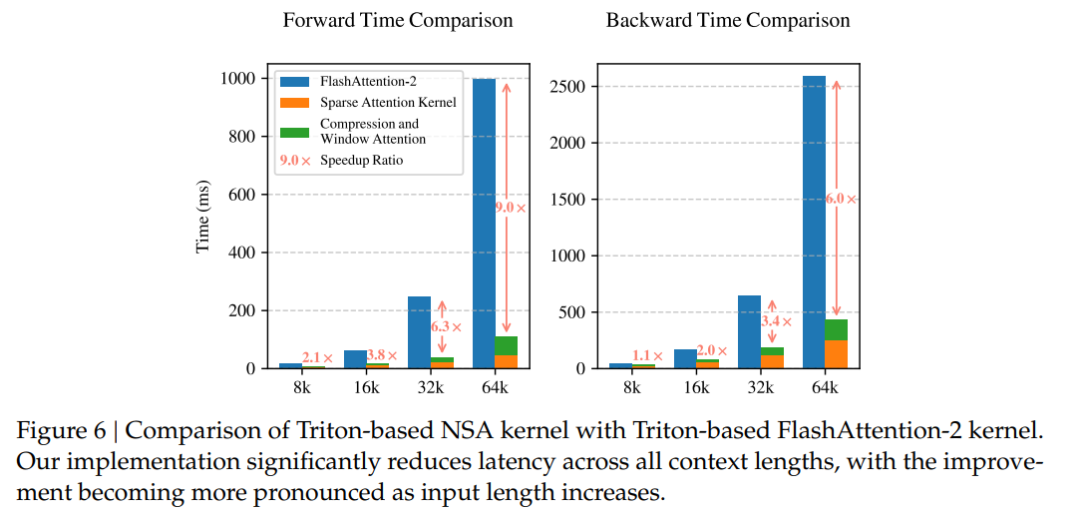
NSA在长文本建模中表现出显著的加速效果,尤其是在64k上下文长度下,NSA实现了高达9.0倍的前向加速和6.0倍的反向加速。
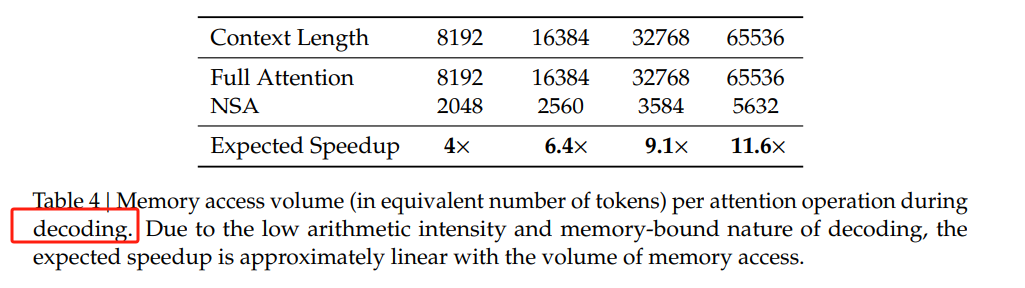
解码速度提升11.6倍:在处理超长文本时,NSA通过稀疏注意力机制显著减少了内存访问瓶颈,大幅降低了解码延迟。
https://arxiv.org/abs/2502.11089 Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
(文:PaperAgent)