
先谈一个测验Reasoning模型的题目
最近某个群里面有一道考验大模型能力数学题, 感觉这个题比9.9和9.11谁大更考验Reasoning模型, 似乎很多大模型的答案都做的不好. DeepSeek-R1能做对,但是整个思考过程非常长, 大家可以自己试试.
给如下等式添加括号,可以加多个括号,使得等式成立:8 + 28 / 4 -2 * 3 = 6
正确的答案是(8+28)/((4-2)x3), 因为后一项的两层括号嵌套增加了模型的搜索难度. 如果更严格一点的考验是:
给如下等式添加括号,可以加多个括号,使得等式成立:8 + 28 / 4 -2 * 3 = 7
可能对于搜索算法而言存在一个停时问题, 可以产生一个对大模型产生一个超级长context输出的攻击, 例如我就专门构造这样的数据, 多层括号嵌套才能得出答案, 或者根本没有答案的不同的数值去攻击, 会导致模型大量的资源用于Decode, 我不确定是否会导致Expert负载的极端偏斜,从而引发后台调度系统的弹性扩容?
其实我们在通往AGI的路上还有很多的路走, 还有很多踏踏实实的工作要去做.
谈谈关于DeepSeek R1和NSA算法的反思
最近一段时间复现了一下R1的算法, 训练了一个渣-7B-R1, 似乎能做对一点题目了.

然后针对中文和英文的数据集做了一些测试, 数据集导致的reward方差还是挺有趣的一个话题.
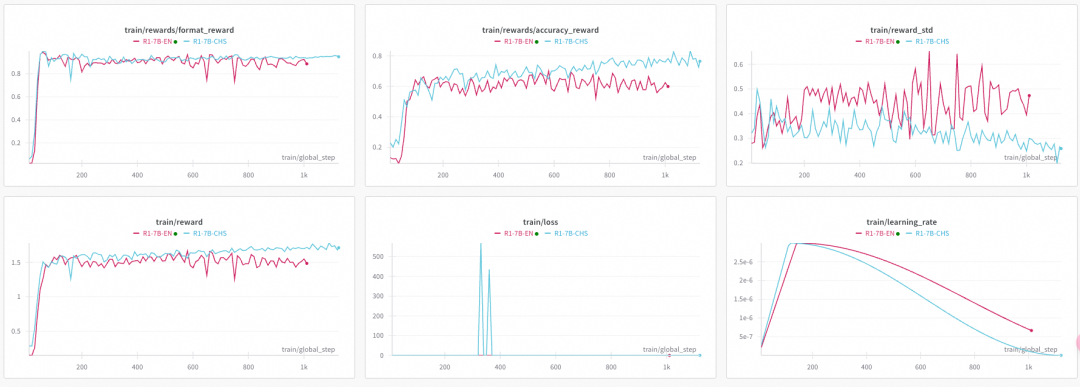
在这个过程中, 伴随着昨天发布的Native Sparse Attention(NSA)有了太多的感触. 从算法的角度, 我一开始就不太相信一个的算法上会有ScalingLaw, 在2023年的时候, 就写过一篇文章《大模型时代的数学基础(1)》 探讨Transformer模型结构的优化,特别是算力约束下, 引用当时的一段文字:
现阶段国内大量的模型都还在仿制的基础上进行一些微小的创新,例如Tokenizer算法的选择上用BPE,或者位置编码上采用RoPE或者ALiBi,激活函数上SwiGlU等,归一化层上的位置,RMSNorm实现等,这些在模型的根本结构上没有太多的变化。
那么一个命题作文:在短期算力受约束,只能使用L20/H20后,如何降低每参数的训练FLOPS开销?如何能够通过模型网络结构的修改能获得在算力受限时的线性扩展能力?
当然FP8/Log8 Quantization是一条路,而另一条路是在模型结构上,MoE该如何做的问题,此时还有一个更诛心的问题出来了,国内也有把模型规模扩展到万亿级别的,但是为什么还没有达到GPT-4的能力?这个问题会从范畴论的视角来阐述的,当然还有更多的问题:
训练数据集质量对大模型的直接影响是什么?MoE的网络结构要求是什么,Sparse Transformer和一些window attention为什么没有太大的作用,Prompt和ICL为什么作用有限,RLHF为何有一个代价叫对齐税,CoT一类的东西背后的数学原理是什么,如何对大模型推理能力增强,如何通过模型的结构来约束降低幻觉,如何从理论上证明FP8并控制模型在低精度下依旧能够保证训练收敛?
最终由这些问题解决的答案推出一个模型网络结构,再有针对性的设计AI infra,这才是我们最迫切需要的东西,可惜国内各个团队除了做一点微小的模型改动,没见到有任何一个团队有系统性的思考。
里面谈到了FP8, MoE 这些DeepSeek-V2/V3的优化策略, 也谈到了sparse transformer为什么不行, 也谈到了CoT一类的Reasoning的问题, 以及国内厂家都在做一些微小的创新等等一系列问题. 而最近发布的DeepSeek NSA和Kimi MoBA进一步加重了对过去两年工作的反思, (顺便调侃一下为啥每次Kimi都和DeepSeek撞车呢? R1和Kimi K1.5也是…)
对于NSA和MoBA,其实渣B也想到了, 在《谈谈大模型架构的演进之路, The Art of memory.》也谈到过这样一段话:
诚然, 我们在做很多尝试, 通过KV Head的构造来修改Attention block降低训练和推理时的内存开销. 但是很多压缩到Latent Space本身就是有损的, 所以这也是我一开始就在怀疑DeepSeek MLA的作用(当然这些担忧现在看起来是没有意义了).
这些工作实质是在一个固定的物理内存上进行处理, 放不下的时候, 去压缩数据结构. 再加上《Space-time tradeoffs of lenses and optics via higher category theory 》这篇文章通过高阶范畴中的一些关于Optics和Lens的时空折中描述, 也是一个很值得去分析的东西.
但是从计算机体系架构的视角, 我们真的需要把所有的Context都在内存里放着, 供Attention这样的Control Unit全量去访问么? 其实一个真正的Attention应该在这个基础上引入页表的机制. 就像我们读书或者读论文, 某一段某一章节引用另一章节. 整个计算引擎只需要它程序指向的那几个页表.
基于这个思路, 我们就可以构造一个虚拟内存空间, 将真正所需要的那些页来进行Attention计算. MoE或许就是一个最早期的页表内存的实现. 而前段时间提出的MoE Group本质上就是想要把它扩展成一个多级页表.
但是现在的反思就是, 为什么就差那么几步就能点破了呢? 过去的两年多, 因为工作职责的原因, 大概只能偶尔申请几台机器在本质工作做完了的基础上做点小实验, 主要工作还是在一些和Infra相关的ScaleUP/ScaleOut总线相关的研究上. 没有算力的支持下, 把更多的精力投入到了一些高阶范畴/代数几何相关的算法研究上, 少了很多实验的机会.
但事实上这条路对不对? 某种意义上是对的, 例如对于R1的训练上, 在2023年的《大模型时代的数学基础(2)》中提到了一段, 指向了通过代数构造的ORM based RL.
例如在降低Transformer的计算量时,稀疏Transformer或者MoE是否会破坏态射结构? Transformer算子的可组合性如何设计?通过这样顶层的抽象视角会得出不少有价值的答案。当然还有很多范畴论的内容,例如limit/colimit,以及相应约束下的强化学习和基于Hom函子去构造数据,最终来提高大模型的逻辑推理能力,范畴论视角下函数式编程和大模型的融合,这些都是非常值得我们去深思的问题,或许这也部分回答了OpenAI Q* 的一些解法,我们拭目以待…
但是渣B很多时候还是欠点火候, 前段时间还被家里老阿姨PUA了一下, “人家搞量化私募的,你也搞, 人家有OIer你也是, 为啥做的不好呢?”, 有一些反思是作为一个老的MLer, 还是有些特征工程的视角, 并不如新一代的DLer那么纯粹. 有些过往GNN的成功经验把自己的路走偏了, 特别是前段时间用LLM生成论文的Abstraction时就有了要用Compression Attention去做索引的想法, 但是确实是能力不够, 把问题想复杂了, 要去构造代数结构, 尝试用GNN去约束, 没有DeepSeek那么直接的一个Token Compression上的MLP训练顺便用Attention Score去做Token Selection的想法. 然后RL算法上也是想着代数结构的构造, 而少了几分DeepSeek那种端到端的纯粹.
其实你去看看DeepSeek的论文, 解决问题的方法特别优雅, 又有大量长期主义的特点, 又富有理想主义的浪漫, 他们的研究品味高出国内厂商一大截. 当看到DeepSeek-MoE的论文的时候, 就觉得这家公司路走对了, 再看到DeepSeek-V2的MLA时,就坚信这家公司能做出一番大事业来. 毕竟在国内清一色的Llama系跟随的路上, 有那么一家公司直接对Transformer结构动刀, 勇气上就胜出一大截了.
作为一个RLer, 仔细来看, DeepSeek的长期主义路线是非常明确的. MLA/MoE/NSA其实只是RL路上优化计算复杂度的手段, 包括GRPO本身也是在计算效率上的极致优化.
谈谈未来大模型的基础研究
其实有一个问题, 为什么DeepSeek的很多创新没有发生在一些大厂呢? 倒是大厂为了抢算力还有在训练模型的集群投毒的事情. 归根结底还是一个绩效机制的问题, 组和组之间的内卷导致的. 人生活在绩效的不安全感里, 势必会做一些非常规的动作,这是人性. 所以大厂可能更多的是一些微小的创新, 例如NSA这样的东西, 如果训练1~3个月失败了,后面还有没有训练资源, 再往后的绩效如何? 不安下的巨大创新是几乎不可能发生的. 另一方面是大厂的组织结构和部门墙的厚度决定了协同效率的差异. 当然还有更重要的一点, 老板的定力和眼界也决定了整个机构的研究天花板, 例如NSA的论文有梁总的直接参与, 老板是否有更加全面的知识面直接影响到研究路线. 还有一个问题来自于大厂选择的标准几乎都是看发了多少论文, 做成了多少事情,把过去的经历看的比能力本身重要太多. 而为什么梁老板更倾向于找一些年轻人? 年轻人更能够承担失败的代价, 更少的被过去的经验束缚, 再加上一个更宽松的绩效机制和更紧密的全栈融合的小团队, 以及更远大的理想和目标, 没有融资的压力,自然会比其他大厂少了很多经营上的烦恼.
抛弃这些, 很多时候打铁还需自身硬, 大模型本身还有大量的基础研究工作要去做:
-
FP4或者Log8下的大模型训练该如何做, 量化的方式如何, 如何通过这些在GPU微架构上的调整.
-
接着第一个问题, FP8在这一代生命周期偏中后期了才用起来FP8, 以及FlashAttention和TK才逐渐用起来TMA, 问题在哪? FP4的研究要尽早.
-
优化器是否也是一个可以去静下心来研究的?
-
MoE的细粒度程度估计, 算力/内存带宽/网络带宽三者之间的平衡, 特别是如何利用Infra的一些细微的改动提升访存效率, 例如2级Gating? 例如文章《谈谈DeepSeek MoE模型优化和未来演进以及字节Ultra-Sparse Memory相关的工作》所述.
-
softmax函数在训练时, 温度是否可以构成一个可训练的参数?
-
训练参数本身在非线性空间下的一些约束是否能加速训练? 例如Nvidia的Hypersphere?
-
ORM based RL中, 如何构造数据集更多的从代数结构上约束?
-
模型结构本身的深度, 例如60层 vs 128层, 是否可以用预测Next Few Token然后作为Context后影响计算来对模型深度折中?
-
如何进一步降低对ScaleUP网络的依赖, 甚至构建异构加速器的训练场景? 进一步把国产加速器用在训练上.
-
计算机体系结构的视角去理解大模型, 例如DeepSeek CodeI/O相关的工作和《谈谈大模型架构的演进之路, The Art of memory.》谈到的一些内容.
-
一些数学基础的研究还是必须的, 例如草稿箱里一直还有一篇未写完的文章

当然还有许许多多基础的工作都还没有列出来, 特别是一些涉及Infra相关的工作, 因为涉密无法多说.
这次个人的反思, 更重要的一点是,忘记人本身的经验, 当你一心一意想用人的经验去构建一个AGI/ASI时,必定不会成功. 做一个更纯粹的RLer, Let it learn, don’t teach, keep it simple.
(文:极市干货)