

极市导读
从理论角度证明了扩散采样中的每一次反思都可以提供额外的语义信息。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
xLeaF Lab作品。
本文由论文一作同学 Lichen Bai @爱吃糖果 主笔,Lab PI编辑、修改。

亮点总结
我们发现扩散模型中去噪过程和反演过程之间引导(CFG)强度的差距能够捕捉潜在空间中的语义信息,这对图像生成质量以及与生成条件的对齐具有重要影响。
我们把一个扩散模型在一步采样后重新反演到上一步的操作叫做扩散反思。我们的工作从理论角度证明了扩散采样中的每一次反思都可以提供额外的语义信息。
基于此,我们提出了Zigzag Diffusion Sampling(Z-Sampling),一种让扩散模型在一步步的自我反思中提高生成质量。 看下面的示意图就很容易理解,为什么叫Z采样,因为它的采样轨迹变成了“之”字型。
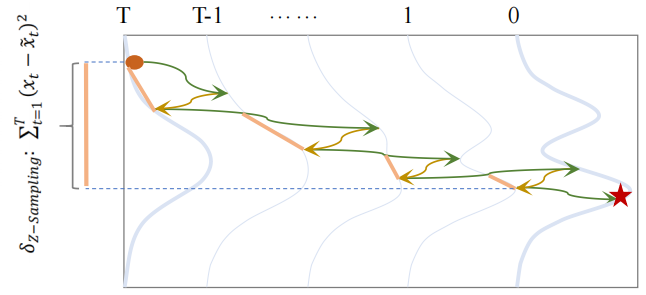

Z-Sampling实际上是xLeaF Lab上一篇文章介绍的工作“Golden Noise”的姐妹篇 xLeaF Lab | 扩散模型的“黄金噪声”:随机噪声并不生而平等(https://zhuanlan.zhihu.com/p/15259944648)。
Golden Noise只考虑第一步反思操作对于初始噪音的影响,并用一个小网络来学习第一步反思。而Z-Sampling考虑了扩散反思在整个采样路径的累计收益。所以Z-Sampling大部分时候在生成质量上甚至会更高于Golden Noise,大大提高了扩散反思能提供的受益上限。当然,代价是会出多几步扩散反思的成本。
Z-Sampling方法利用反思过程中CFG强度的差距,通过每一步自反思操作积累语义信息,从而生成更理想的结果。Z-Sampling能够灵活控制语义信息的注入,适用于多种扩散架构,特别是作为一种无训练方法,Z-Sampling在限制推理时间的情况下,依然能够显著超越基准性能 。
我们的实验里,Z-Sampling在DrawBench上可以让DreamShaper上相对于标准采样的HPS胜率winning rate提高到94%!
Z-Sampling已被ICLR2025接收,代码已经开源,欢迎大家使用!
Code: https://github.com/xie-lab-ml/Zigzag-Diffusion-Sampling
Paper: Zigzag Diffusion Sampling: Diffusion Models Can Self-Improve via Self-Reflection(https://openreview.net/pdf?id=MKvQH1ekeY)
知识储备
这项研究聚焦于扩散模型的推理采样上,扩散模型通过逐渐给数据添加噪声直到变成随机,然后再通过反向去噪来恢复或生成新数据。我们分析的关键工具是扩散模型的去噪和反演过程,具体来说:
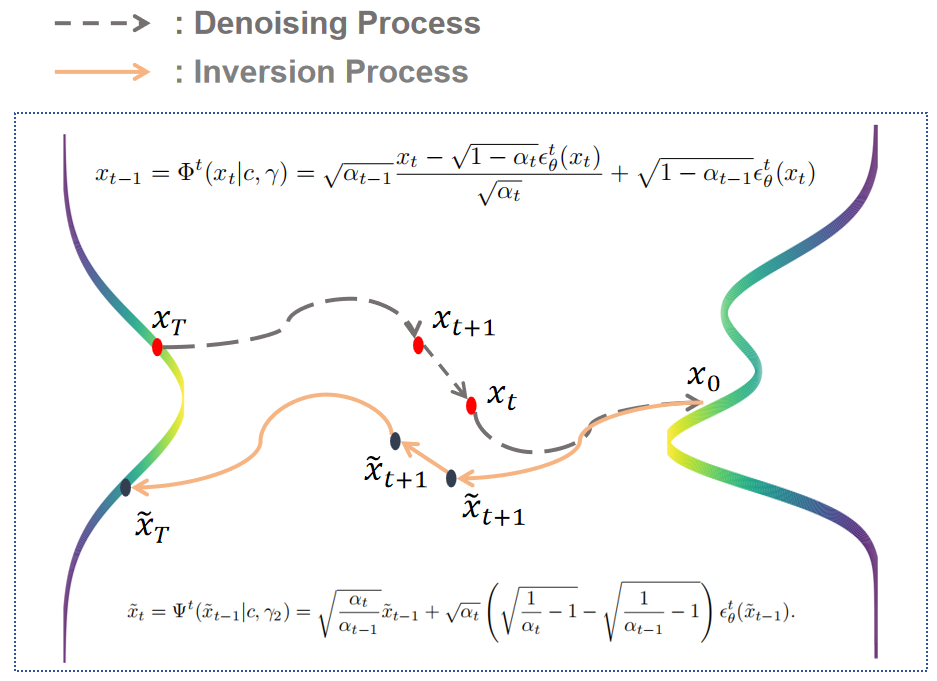
Denoising Process (去噪过程)

上面这张图可以说是对扩散模型最经典的解释之一:从随机采样的高斯隐变量出发, 经过去噪网络,迭代地生成干净的结果——这也是扩散模型的去噪过程。在这个过程中,纯噪声x_t经过T步去噪,得到了生成数据x_0。
Inversion Process (反演过程)
相反地,如果有一个干净数据x_0,我们如何得到对应生成它的高斯噪声呢?这时便需要利用扩散模型的反演过程,反演操作在图像和视频编辑领域中得到了广泛应用。值得注意的是,在忽略反演带来的误差前提下,并且假设两个过程的去噪网络参数以及生成条件(例如条件引导强度)一致的情况下,去噪过程与反演过程可视为一对互逆的映射。
研究动机&观察
在扩散模型的采样过程中,什么才算是一个“好的隐变量”?或者说,一个好的隐变量需要具备哪些与众不同的属性?
我们的方法受到了两个关键insight启发。
1. Latent空间有隐含语义信息
作为Z-Sampling的姊妹篇,第一个观察实验其实已经在扩散模型的“黄金噪声”:随机噪声并不生而平等(https://zhuanlan.zhihu.com/p/15259944648)中阐述过了,这里我们再简要说明一下:
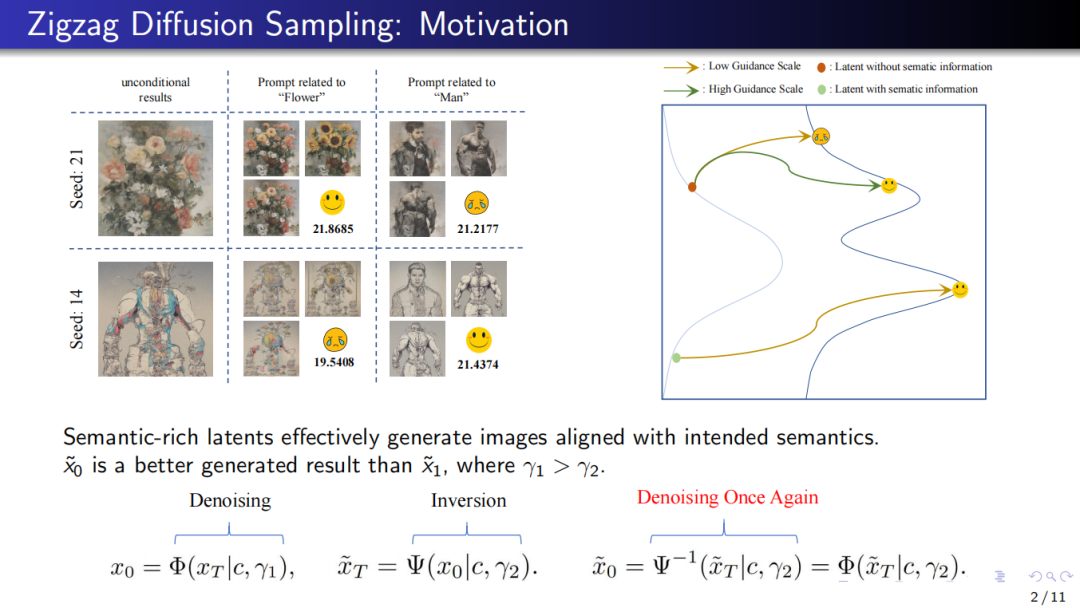
这个实验的结论可以用一句话概括:“对于特定的条件提示,如果一个随机采样的初始噪声能够在没有任何额外条件的情况下,就能生成与提示相关的结果,那么可以认为这个初始噪声天然地携带了与提示相关的语义信息。在这种情况下,这个噪声就是一个好的初始隐变量。
举个例子,下图(左)中,考虑在 seed 为 21 时采样的初始噪声。从第一列可以看出,即使在无条件下 ,seed 21也能生成和“Flower”相关的图像。因此,可以认为seed 21天然地携带了与“Flower”相关的语义信息。接着,在给定提示 prompt= “Flower”时,相比于其他初始噪声(例如 seed = 41),是一个更好的初始隐变量(对Flow而言),从这个初始噪音出发,可以得到更符合提示的生成结果。
而下图(右)形象地展示了这一实验得出的结论:绿色的隐变量(带有语义信息)要比红色的隐变量(不带有语义信息)更好。这意味着带有语义信息的隐变量能更好地对齐给定的提示,从而生成更加符合预期的结果。
2.扩散反思(Inversion)注入语义信息
我已经知道了从无条件生成可以看出来,有的latent和prompt是天生一对,能提高生成质量。
而第二个实验的insight是,“Inversion促使隐变量变得更好”。
考虑两张自然照片(左边的猫咪,和右边的蜘蛛),按照DDIM Inversion的操作,我们将它们反转得到与猫咪和蜘蛛对应的初始噪声。
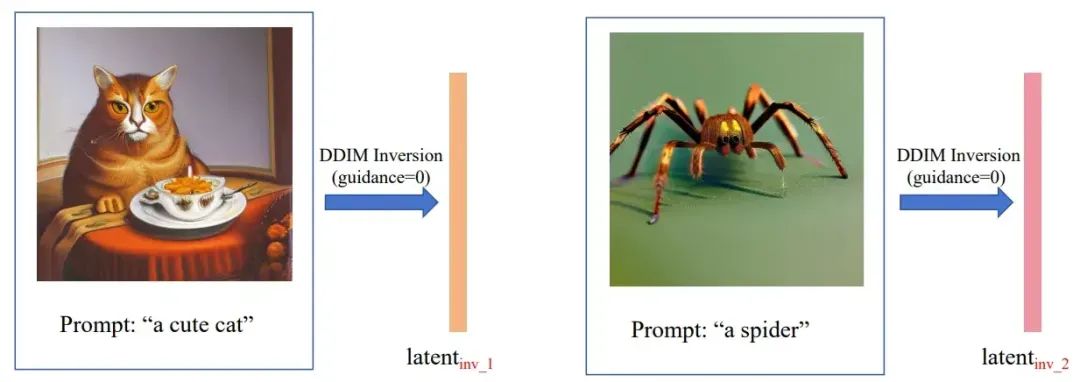
接着神奇的事情发生了。猫咪反转得到的latent就是更擅长生成猫咪,蜘蛛反转得到的latent就是更擅长生成蜘蛛。
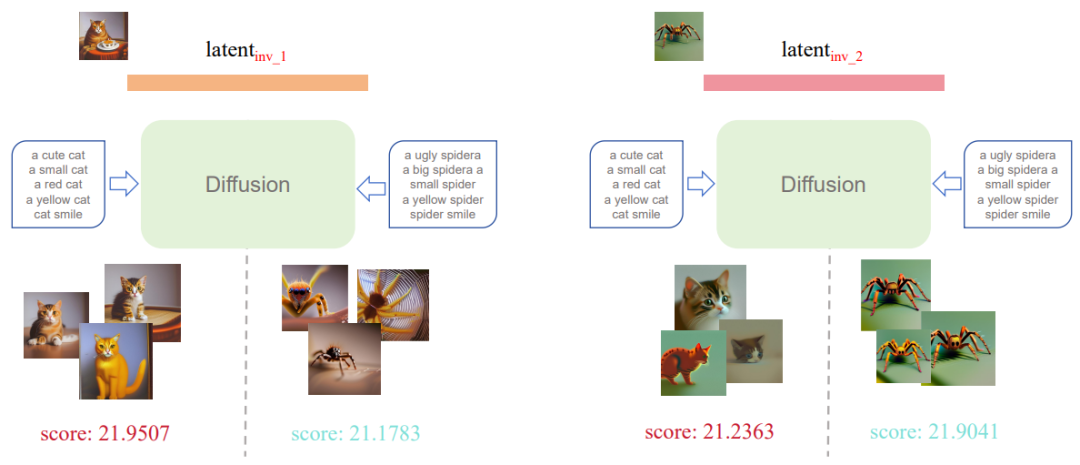
扩散反思机制的秘诀
到底是什么导致Inversion操作有如此魔力呢。答案就是此前提到的伏笔,在 Inversion 操作中,条件的引导非常弱(CFG scale很小), 而在对应的 Denoising 过程中,我们通常设置较高的引导尺度(e.g. 5.5),也就是说,Inversion 和 Denoising 之间存在一个 guidance gap, 这个 gap 的存在使得隐变量能够注入与提示有关的语义信息,使之成为一个good latent(即第一个观察实验中的latent with semantic information)。
其实,这个实验的核心概念很容易理解。我们可以将其想象成两个阶段:第一个阶段是去噪过程(绿色箭头),第二个阶段是反演过程(棕色箭头)。

上式可以推导出(由于去噪过程和反演过程的可逆性):
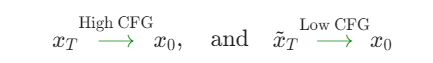
我们如果仅考虑当前时刻和前一时刻的关系,先在强条件下去噪,然后在弱条件下反演,从而是隐变量包含更多的语义信息。
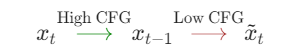
同样有
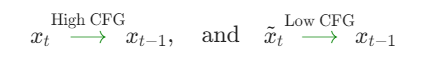
这也说明了,去噪与反演操作之间的引导差距(即引导强度的差异)能够有效地捕捉和注入提示相关的语义信息,从而优化生成结果的质量。
至此,得到了本文的核心结论:
Denoising与Inversion操作之间的guidance gap能够捕捉latent空间中和prompt 相关联的语义信息,并将这些语义信息注入到隐变量中,优化扩散模型的采样质量。
Z-Sampling算法
接下来的部分就顺理成章了。既然每次反思都有新的信息注入,那么我们就每步都进行反思,具体算法如下所示:
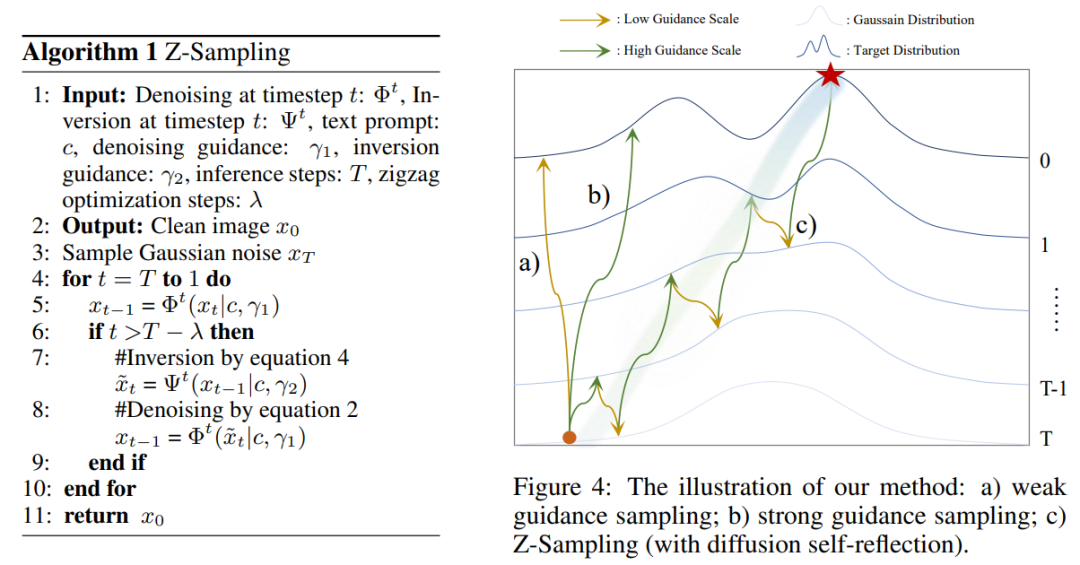
我们只需要关注这个gap,就能随意控制采样轨迹中语义信息注入的大小和方向了,我们称之为Z-Sampling。同样的,Z-Sampling 的采样轨迹呈现出一个之字形(PS:我们的后续工作在实验中还原了这种 zigzag 的采样轨迹)。
理论分析
同时,我们进行了一些推导,表示Z-Sampling的效果可以由两项决定:
-
语义增益项:由guidance gap带来的语义信息增益 -
反演误差项:由inversion process带来的不可避免的近似误差
我们在论文里做了更详细的说明,表明应该尽可能增大语义增益项,而缩小反演误差项,从而带来更好的生成效果增益。

特别的,如果反演误差为0的话,那么Z-Sampling带来的效果则完全由guidance scale在去噪和反演过程里的差值决定。
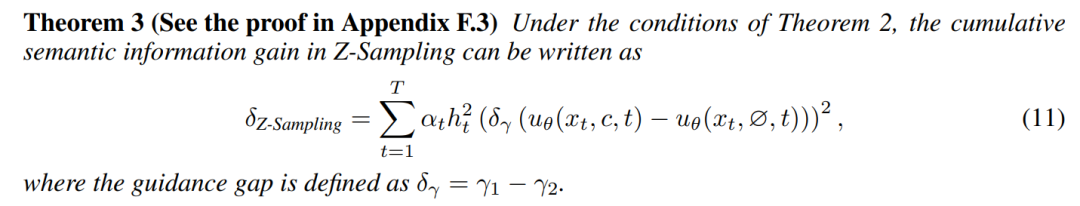
可以看到guidance gap控制着语义增益项的强度和方向,精细地调节模型如何以及多大程度上将提示中的语义信息融入到生成过程中,这也为之前的两个观察实验提供了理论上的解释。
实验结果
由于篇幅限制,此处仅展示部分实验结果;更多详细的实验结果请参见论文 。
-
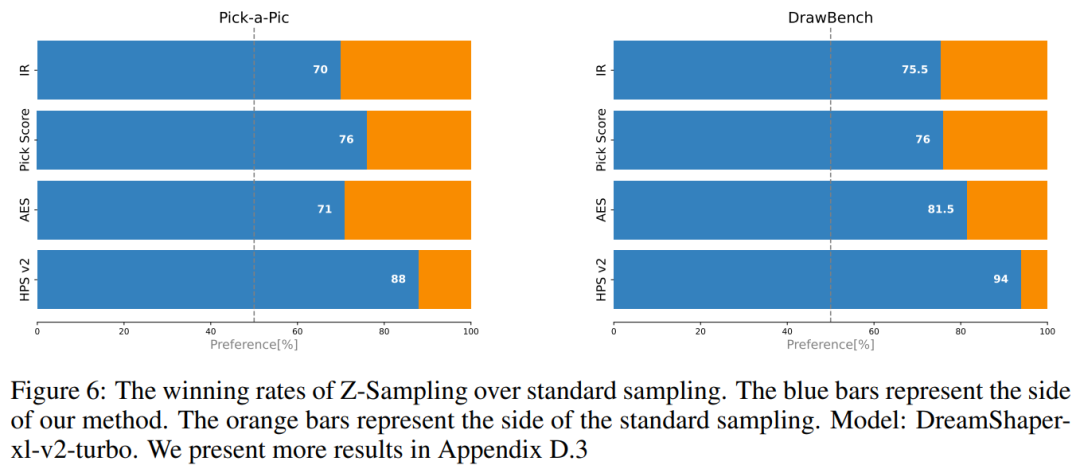
实验一比较直观,主要比较了 winning rate的结果, Z-Sampling 在四个指标上均取得了领先,特别是在 HPS v2 指标上(这是一个用于评估人类偏好的指标),其 winning rate 可以超过了 90%。
-
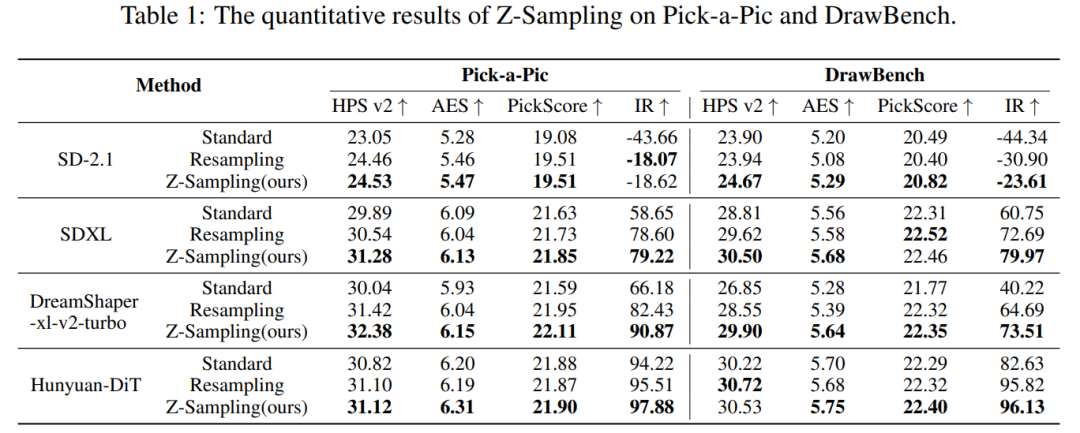
实验二是主实验, 为了证明 Z-Sampling 在不同类型的扩散模型中均具有普适性,我们选用了以下几类模型:基于U-Net架构(SD-2.1,SDXL)、蒸馏模型(DreamShaper-xl-v2-turbo),基于DiT架构(Hunyuan-DiT),并在两个Benchmark中表现均比较出色。
-
实验三的目的是证明 Z-Sampling 与其他多种扩散模型提升方法之间是正交的,其提升效果可以相互叠加。无论是基于训练的方法(例如 Diffusion DPO),还是免训练的方法(例如 AYS),都能与 Z-Sampling 协同工作,进一步提升生成效果。我们认为这一特性蛮nice的,使得 Z-Sampling 具备即插即用的优势,展现出比较大的应用潜力。
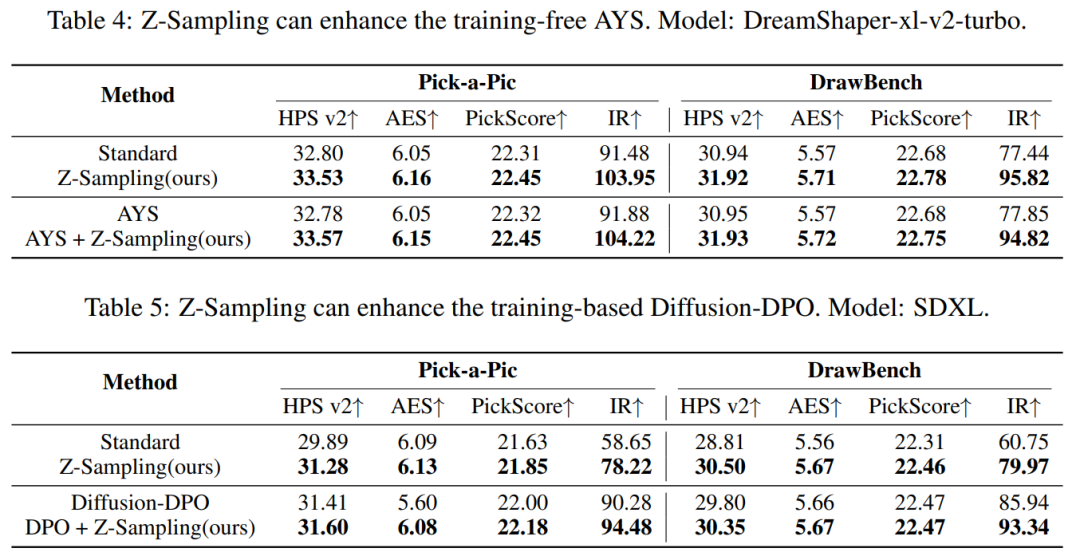
定性实验
-
总体来说,Z-Sampling 带来了一些令人满意的改进——无论是在图像对比度的提升上,还是在更好契合 prompt 方面,都有一定进步。在风格、位置、颜色、数量等多个维度上,也展现出了相应的提升效果。
-
同时,我们也对Attention Map做了一些可视化分析,Z-Sampling可以让去噪网络对entity token的注意力响应更加清晰明了一些。

消融实验
限于篇幅,更多实验分析请参见论文
-
Guidance Gap:第一个消融实验想证明,guidance gap 是怎么影响Z-Sampling的效果的。下图可以看到,当gGuidance Gap为正时,会呈现正增益;而Guidance Gap为0时,则近似为标准采样;当Guidance Gap为负的话,Z-Sampling反而会带来负增益。实验完全如理论预言。


-
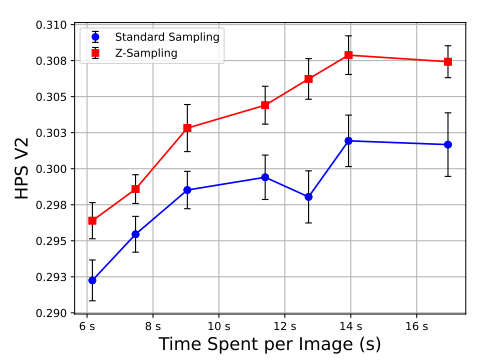
Time Efficiency:另一个重要的消融分析关注的是时间效率问题。尽管 Z-Sampling 会引入额外的去噪和反转操作,但实验证明,这种“之字形”(zigzag)操作带来的性能提升远远超过了其额外的时间开销。我们通过调整超参数,使得 Z-Sampling 与标准采样在生成同一张图片时所用的时间保持一致(具体表现为score network推理次数一致), 在相同的时间消耗下,Z-Sampling 始终优于标准采样,且大大提升了性能上限。这一实验结果为 Z-Sampling 的实际应用提供了有力支撑。
展望
最后再来总结展望一下,我们提出了一种新的扩散采样算法Z-Sampling——通过让扩散模型在采样时反思走出一种Zigzag的采样轨迹。参考LLM推理的术语,我们把扩散模型采样中每一步进行反演这个操作称之为“扩散反思”。
我们的理论分析(Theorem 3)很清楚地指出了,扩散反思操作的价值就是为latent空间提供语义增益,而步步反思可以累计这种增益;而motivation实验里end2end的反演会让不同step的语义增益互相抵消。
我们的实验结果也证明了,Z-Sampling既可以提高扩散模型生成质量的上限,也可以在相同的生成时间下超过标准方法。
甚至这种扩散反思操作还能推广到视频生成领域,用图像生成模型帮助视频生成模型“反思”,突破视频生成模型采样质量的上限——这也就得到了我们另一篇ICLR2025工作的方法:图像-视频混合采样器(IV mixed Sampler)。
这里先做个预告,后续撰文介绍。
Code: https://github.com/xie-lab-ml/IV-mixed-Sampler
Paper: IV-mixed Sampler: Leveraging Image Diffusion Models for Enhanced Video Synthesis(https://openreview.net/pdf?id=ImpeMDJfVL)
Website page: https://klayand.github.io/IVmixedSampler/

(文:极市干货)