跳至内容
本文来自《马丁的面包屑》,Founder Park 略作调整。
2月18日,DeepSeek在Twitter上公布了最新论文:Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention。截止本篇解读完成,已经获得100万阅读量。
我对他的看法,可以引用Twitter上一名网友的评论:“Holy shit this shits on Grok 3”。
我更喜欢我读到这一句话时,脑子里第一时间的译法:“我的天,这简直是在Grok3头上拉屎”

DeepSeek在解决什么问题?
前置科普
模型训练以及推理,和“注意力”这个东西脱离不了关系。为了方便后文的阅读,对注意力进行一个简单的科普:
你可以想象,你在读一本书,你的目光会在书上扫来扫去,理论上说是逐行阅读对吧?
但实际上,只要是稍微喜欢阅读的人,阅读中的目光一定是图像式的,也就是说“一目十行”,会快速对某个区域的文本做一个浏览,几乎不可能是一个字,一个字读过去的。
注意力就是这里面对文字的专注捕捉,所以你是怎么一目十行的呢?很显然,你进行了跳过,并只看了某些重点信息,你并不需要真的一个字一个字读过去
p.s,当我们读英文的时候,却没有中文的这种速度,某种程度上就是注意力机制在跨语言的失效——我们的大脑只训练了中文注意力,而英文注意力很薄弱。
Get到了吧,这个时候就引入今天的主题:稀疏注意力(Sparse Attention),即一目十行;而与之相对的是全注意力(Full Attention)。
稀疏注意力的问题
事实上,稀疏注意力不是一个独创的概念,但他存在若干问题:
① 大部分稀疏注意力是用在推理阶段的,而不能用在训练,这就导致模型能力下降。诸葛亮读书只求大略,然后嘎嘎输出。结果我没用诸葛亮的读书方法,也想学诸葛亮嘎嘎输出,这就有问题了。
② 多数稀疏注意力方法,要么是只集中于预填充阶段(Pre-fill),要么就是集中于解码阶段(Decoding),很少有两者都能搞定的。
以输入“你是谁”,模型回答“我是马丁”举例说明预填充和解码的区别
预填充:拿到输入“你是谁”,计算出“我”,这个过程中“你是谁”是一次性拿到的信息,所以他计算成本高,要一次性算三个字,出一个字,但内存成本低
解码:从“我”开始,预测出“我是”,“我是马”,“我是马丁”。这里面每次解码都要重新拿到前面算好的所有信息来预测下一个字。所以他的计算成本很低,每次就出一个字,前面的也不用算。但是内存成本高
在预训练阶段以及长文摘要,阅读理解这种推理任务上,预填充的压力大,在如R1或代码这种长输出的场景上,解码的压力大
③ 一些稀疏注意力方法,没办法和现在常见的高效架构GQA、MQA兼容(在前文《万字长文:DeepSeek 647天铸就的登神长阶》有提到,DeepSeek-67B用的GQA,后来改为了自研的MLA)。
GQA就是把输入的Token们生成的向量分成N组,然后组内共享一个计算结果,这样成本就下降N倍。
但是有些稀疏注意力方法,他一目十行挑重点内容的时候,就是按Token挑的,例如从50个人里找1个帅的,结果50个人被GQA变成了5队。一个帅的VS1队,这单位就匹配不上了。
所以,DeepSeek要什么?
① 我要一个能同时用在训练上和推理上的稀疏注意力方法,这样模型的智力才不会下降!
② 我要能够同时作用在预填充阶段和解码阶段的方法,长文摘要的命是命,代码长输出的命也是命!为我发声!
③ 我要能够兼容GQA、MQA这种方案的方法。一个成本折扣还不够,我要来个折上折!
DeepSeek的解决方案
神说要有光,然后挨了三板砖,吃了一颗糖
物美价廉的大方针确定了,DeepSeek开始尝试业内的各个学术方案
如ClusterKV,Quest,InfLLM等等,但不是成本高,就是不好用
最后他们把他们一个用常规全注意力方法训练的27B模型可视化了一下
看到里面橙色的东西没有,那就是Token的注意力分数。
他们发现在一些地方,似乎注意力的分数是连续、聚类的!
于是真正的方案来了:NSA
① Token Compression-压缩块(下图最上)。把所有注意力,按时间顺序压缩成块,然后只计算一个粗略的注意力分数。这部分不求细节,只求大略,不精准,但全面。
② Token Selection-选择块(下图中间)。我要从全部注意力中,挑选出我要着重,特别注意的部分,算出他们的精确注意力分数。在这里,会借用前面压缩块时已经算过一遍的分数来参考计算我这里选择块的分数,可以避免全部重算一遍(不然贼亏)。算完后,拿TOP-N作为被选择的块(就是图中绿色部分)。
③ Sliding Window-滑动窗口块(下图最下)。最后,预测的时候最近的内容也很重要,所以我们做一个固定窗口的块,专门计算最近Token内容的分数。
总而言之,我有全局(压缩块),我有精细调研(选择块),我还有实时近况(滑动窗口块),谁能当我!
如果这事儿这么简单就好了。事实上,模型在训练的时候会投机取巧,他们总能发现——我只要用近况去预测,就已经差不多准了哎,要什么全局视野和精细调研(是不是和很多错误决策很像?)。
于是DeepSeek专门把这三种策略在训练的时候隔离开了,避免全局思维和精细思维没被训练到,只训练到了猪突思维…
然后,他们又搞了CUDA内核…
但是我看不懂…Infra真的是我的痛点,谁能教教我…请后台私信留言,加个好友来聊聊
我最近对VLLM,KTransformer这些都很感兴趣,但不知道从何学起
最后,可怕的不是价廉,而是物美
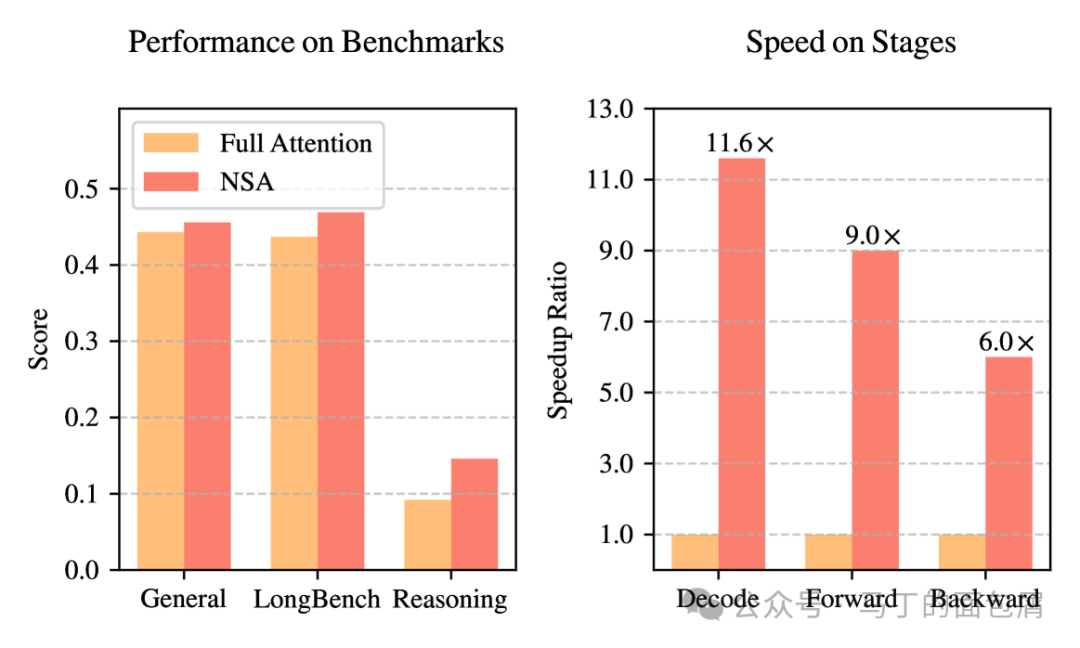
NSA这个方案,他们在27B(3B激活参数)的MoE架构模型上做了多项测试
后向传播,提升6倍;前向传播提升9倍;解码速度提升11.6倍!
模型预训练中用到前向传播+后向传播;模型推理的时候用到前向传播+解码。
这个结果在64K上下文中测试得出——并且随着上下文长度增加,这个提升倍数还会进一步上升。
例如下图,解码中每次注意力操作的内存访问量,8K上下文只提了4倍,64K就11.6倍了,终有一天,200K也能廉价地走进千家万户——AI编程有福了!希望编程厂商到时候别再偷偷阉割我的上下文了T-T。
你能想象,你一天到晚一目十行,学诸葛亮只求大略,然后你真成诸葛亮了……?
大家可以看下面这张图,左侧就是NSA方法对比全注意力方法的模型能力评测
从左到右依次是:常见任务,超长上下文任务,推理任务
在训练过程中,NSA逼迫模型专注于最重要的信息,可能是通过过滤掉不相关的注意力噪声来提高能力。
什么PUA圣经!?也就是说,要求AI读残页,AI读不好就骂他,结果AI变得特别擅长读残页,知道自己去捕捉重点信息,甚至因此还变得更加聪明。
受启发了!下次训练视觉大模型的时候可以给AI戴个独眼龙眼罩o.O
好了,快乐的论文解读时光结束了,聊点别的。是的,从我行文里面,你应该看得出来,真的是很快乐哈哈。
主要因为这篇论文他Infra的内容只有一个章节,比V3好读太多了。
一些观后感
AI编程应该会迎来新的爆发
① 这篇论文一方面是冲着超长上下文的成本去优化的,但另一方面——也使得模型在预训练阶段喂入“超长文本”成为可能,这就会导致能力和成本的双重上升!
② 梁文峰出现在作者名单里了,之前也在MoE那篇论文里,除此以外他只出现在了DeepSeek-Coder系列里!老梁,快啊,加油干,我能不能从产品经理变成真正的AI程序员就看你了。现在的AI编程对于小白来说真的只能用来做小工具啊
③ DeepSeek-CoderV2,已经是24年6月,8个月前的模型了。现在有了更好的V3基座,能力上就会有加成,而且从过去的论文上看,预训练采集的数据质量也会受益于基座能力的提升,双倍加强!最重要的是,很多新技术DeepSeek-CoderV2还没用上,我感觉是不是已经在搞了,真的很期待。
开源开到我心痛
① 今天中午对岸的马圣公布了Grok 3,用了地表最强来形容——但,怎么说呢。90分相比89分,当然是最强,但是谁在乎呢?DeepSeek可能只有85分,但人家是真教啊。这也是海外大面积对DeepSeek好感的核心原因。
② 但是,这样开源真的好心痛,因为卡最多的来自对岸,马斯克那个20万卡,要是用上这个技术,能省多少钱,我想一想就心痛得无法呼吸…
③ 而且,虽然我非常喜欢这样的英雄史诗,但是智力、创造力和资源的天平真的难说孰轻孰重。一个优秀的方法,在不同资源体量下,能撬动的利益总量是不一样的。希望勇敢和智慧能战胜财富,希望梦想主义能战胜电线杆上的枯鸦。
视觉系列
① DeepSeek-VL2是12月13日发布的模型,很快有VL3可能不太现实
② 不过我想今天这篇论文让超长上下文在成本和性能上有了突破,这里面的思路不知道能不能借鉴到VL2模型上?现在的VL模型基本上还是以理解静态图片为主的,毕竟图片学习的Token很大(我记得VL2里单图是576Token一张图)。
当然,这个有点玄幻了,不过想到哪里写到哪里嘛,满口胡言。
为什么我要亲自读论文
有些朋友知道,我其实是一个文科背景的产品经理,读论文对我是一件很吃力的事情。我坚持读DeepSeek的论文有以下几个原因:
① 我做判断,需要一个底层的坚固基座。所以关键信息,我不喜欢接收二手内容,差之毫厘谬以千里。
② 关键也找不到太多和我知识水平匹配的高质量的二手信息。懂的人只写给懂的人,上来就徒手推公式。不懂的人则把几个名词翻来覆去说一遍,截几张论文里的图,赚一波流量就跑了。所以我真的是被迫去做这件痛苦的事情(主要是Infra痛苦)。
③ 我觉得DeepSeek的论文是一个很高质量的信源。因为他从DeepSeek-67B做到今天的DeepSeek-R1,整个过程中都写了论文,通过读他的论文我可以遍历整个语言大模型的技术线,整个知识是成体系,承上启下的。有时候我甚至可以通过其中的草蛇灰线,感受到他们智力碰撞出来的火花。
④ 我觉得DeepSeek是真诚的。很多厂商经常今天又发明了什么方法,明天又屠了什么版,存在感刷得飞起。或许100篇里有50篇是有价值、真实的。但我没有这个能力和精力去挑选,也没精力看那么多论文,所以我只看DeepSeek。
最后,我的朋友,我建议你也不要相信我,有能力和精力最好自己去读原文,自己读过,想过,写过,才是自己的。
如果只是把这篇文章往朋友圈里转一转,收藏夹里放一放,缓解焦虑是有用的,学到什么或许真的未必。
引用DeepSeek的引用——“务必要疯狂地拥抱雄心,同时要疯狂地真诚”
Founder Park 正在搭建开发者社群,邀请积极尝试、测试新模型、新技术的开发者、创业者们加入,请扫码详细填写你的产品/项目信息,通过审核后工作人员会拉你入群~
-
高浓度的主流模型(如 DeepSeek 等)开发交流;
-
资源对接,与 API、云厂商、模型厂商直接交流反馈的机会;
-
好用、有趣的产品/案例,Founder Park 会主动做宣传。
(文:Founder Park)