
提升性能

视频生成的测试时Scaling时刻!清华开源Video-T1,无需重新训练让性能飙升

研究团队首次提出Video-T1方法,通过Test-Time Scaling显著提升视频生成性能,提出Tree-of-Frames方法优化搜索效率和生成质量。
DeepSeek 新模型上线:6850亿参数的 DeepSeek-V3 再进化!
DeepSeek发布新模型DeepSeek-V3-0324,参数量685B,支持BF16、F8_E4M3和F32三种精度格式。主要提升性能和修复bug。
人大和阿里开源支持十万级节点图谱生成的框架GraphAgentGenerator
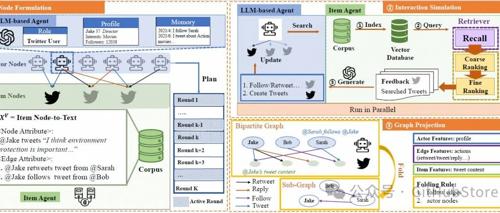
人大和阿里开源的GraphAgent是一个利用大型语言模型来模拟人类行为并生成动态社交图的框架,适用于在线社交媒体、电子商务和论文创作等场景。它通过生成带有文本属性的社会图,揭示网络中的互动,并在多个指标上优于现有方法。


GPT-5要来了?Sam Altman揭秘关键内容

专注于AIGC领域的专业社区关注微软、百度文心一言等大语言模型发展。Sam Altman透露GPT系列将于2025年与最新o系列合并。关于GPT-5传闻,Anthropic内部开发但因回报率低而被保留用于模型蒸馏。
Meta探索大模型记忆层,扩展至1280亿个参数,优于MoE

MLNLP 社区致力于促进 NLP 学术界、产业界及爱好者间的交流合作,Meta 新研究展示了记忆层在预训练语言模型扩展中的实用性和性能提升。
9大基准全面领先,性能暴涨10.8%!视觉价值模型VisVM成「图像描述」新宠

Visual Value Model (VisVM)通过推理时搜索显著提升了多模态视觉语言模型的图像描述质量,减少了幻觉现象。其研究结果表明,扩大推理时间计算量能够显著增强VLM的视觉理解能力,并能以较低成本实现提升。