



-
论文标题:Video-T1: Test-Time Scaling for Video Generation
-
论文地址:https://arxiv.org/pdf/2503.18942
-
Github 仓库: https://github.com/liuff19/Video-T1
-
项目主页: https://liuff19.github.io/Video-T1/
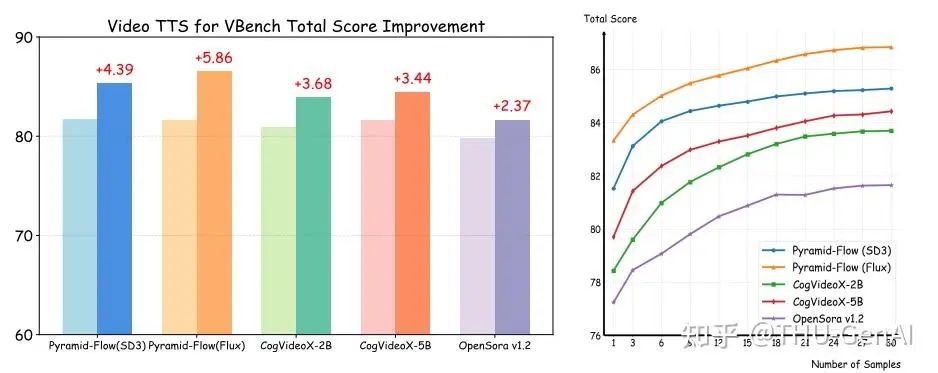 视频生成Test-Time Scaling的实验结果
视频生成Test-Time Scaling的实验结果 随机线性搜索的算法
随机线性搜索的算法 研究团队提出的 Tree-of-Frames 算法
研究团队提出的 Tree-of-Frames 算法 不同模型下 Tree-of-Frames 与随机线性搜索效果对比
不同模型下 Tree-of-Frames 与随机线性搜索效果对比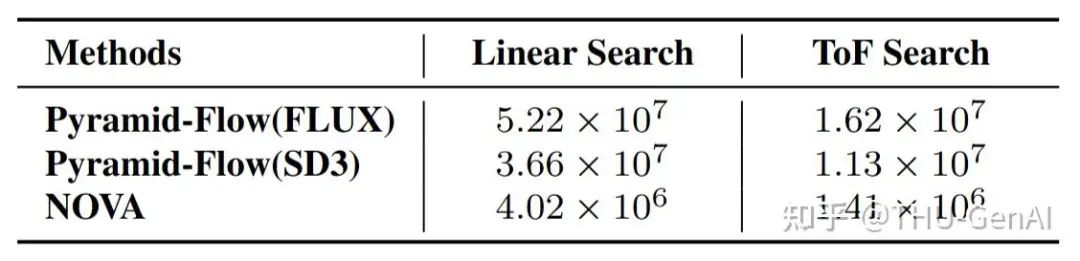 Tree-of-Frames 方法相比于随机线性搜索显著提高了推理效率
Tree-of-Frames 方法相比于随机线性搜索显著提高了推理效率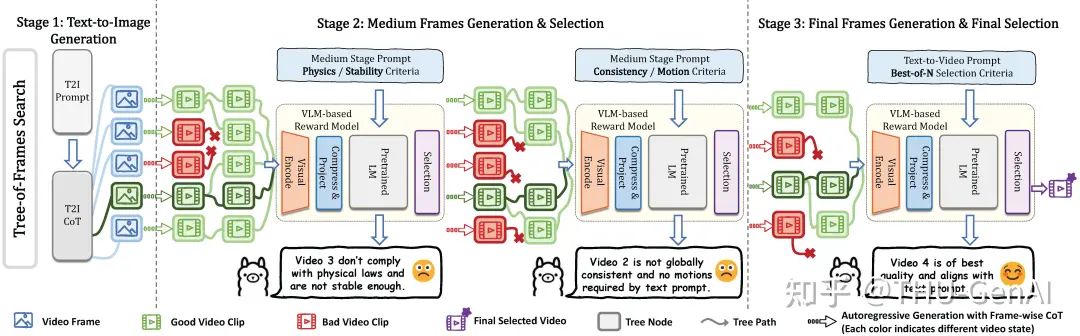 研究团队提出的 Tree-of-Frames 方法流程图
研究团队提出的 Tree-of-Frames 方法流程图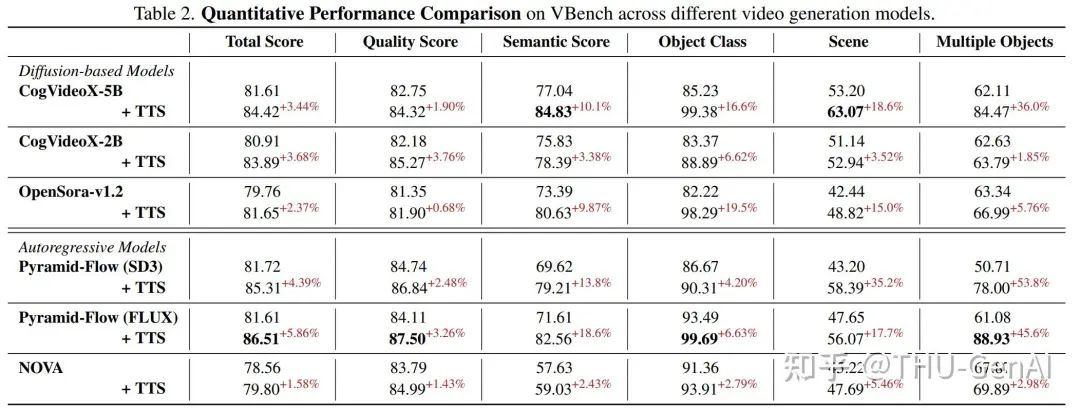 不同维度上 Test-Time Scaling 方法相比于基线的提升
不同维度上 Test-Time Scaling 方法相比于基线的提升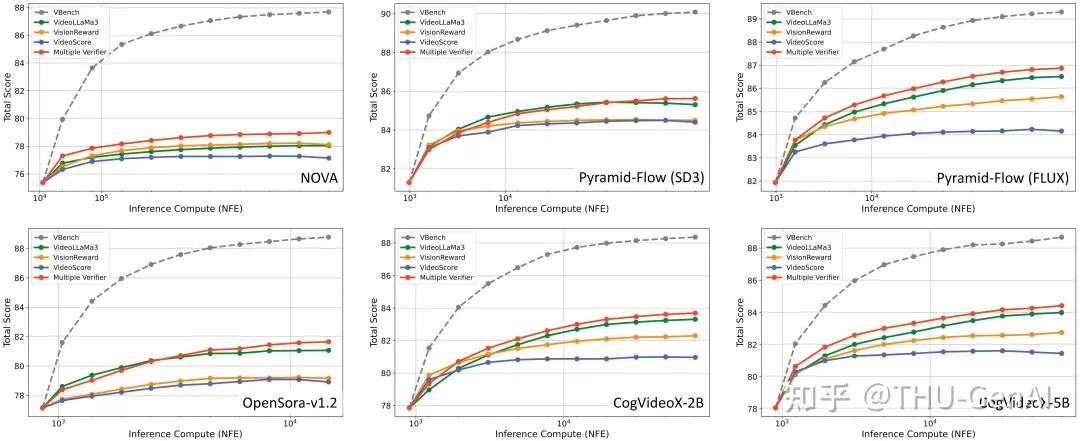 Multiple Verifier 与单个 Verifier Scaling Up 效果对比
Multiple Verifier 与单个 Verifier Scaling Up 效果对比 层次化提示词和分层验证过程的可视化结果
层次化提示词和分层验证过程的可视化结果 部分可视化结果,从上到下为未 Test-Time Scaling 和进行 Test-Time Scaling 的视频对比
部分可视化结果,从上到下为未 Test-Time Scaling 和进行 Test-Time Scaling 的视频对比(文:机器之心)