


新智元报道
新智元报道
【新智元导读】谷歌提出了多智能体协作的新方法「智能体链」(Chain-of-Agents),超越传统方法,多个任务高出10%的性能,特别是处理长文本相较于基线提升高达100%。甚至无需训练,可与多种LLM模型协同工作。
近日,谷歌在博客中介绍了「智能体链」(Chain-of-Agents,CoA)框架,无需训练、任务无关且高度可解释。它通过大语言模型(LLM)间的协作来解决长上下文任务,在性能上超越了RAG和长上下文 LLM。

近年来,LLM在推理、知识检索和生成等多个任务中展现了出色的能力。
然而,对于需要处理长输入的任务,LLM仍面临着挑战,因为它们通常在输入长度上有限制,因此无法利用全部上下文信息。
这一问题对处理长上下文任务造成了障碍,如长文本摘要、问答和代码补全。
针对此问题,在2024年NeurIPS会议上,谷歌提出了Chain-of-Agents(CoA)框架。
为了解决长文本任务,CoA框架通过多智能体协作,在多个LLM之间,利用自然语言,进行信息汇聚和上下文推理。
在多个长文本任务上,评估了CoA,包括问答、摘要和代码补全等。
实验结果表明,CoA在强基准模型——检索增强生成(RAG)、多智能体LLM以及输入被截断的LLM(即「全上下文」模型)——上均取得了显著提升,性能提升幅度可达10%。
具体结果如下:
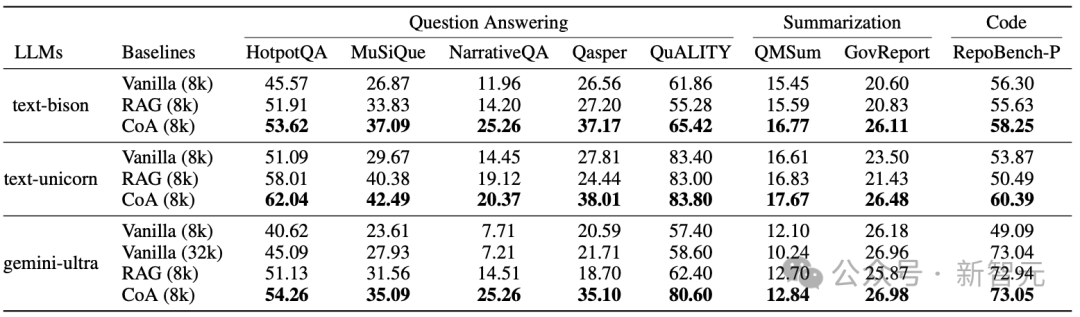
CoA在所有数据集上,使用不同的基础LLM时,显著优于Vanilla和RAG模型
文章亮点:
5 在问答和摘要等任务上,CoA比现有方法高出 10%的性能;特别是在处理较长的输入时,相较于基线可提升高达 100%。

研究背景与动机
输入缩减是通过减少输入上下文的长度——例如,直接截断输入——来优化处理。
RAG扩展了这一思路,通过将输入拆分为多个块,并基于嵌入相似度检索最相关的块内容。
然而,由于检索准确性较低,LLM可能接收到不完整的上下文,影响任务的完成效果。
窗口扩展则通过微调LLM,扩展模型的上下文窗口,使其能够处理更长的输入。
例如,Gemini模型能够直接处理2M的输入长度。
然而,当输入长度超出其扩展窗口的处理能力时,LLM难以将注意力集中到,解决任务所需的信息,从而导致上下文利用效率低下。
此外,由于大多数LLM基于Transformer架构,随着输入长度的增加,其计算成本呈二次方增长。
鉴于上述挑战,作者设计了CoA,灵感来自人类在有限的工作记忆约束下,如何交替阅读与处理长文本。
与输入缩减方法需要处理较短输入(「先读后处理」)不同,CoA将输入分成多个块,然后安排智能体按顺序处理每个块,再完成整体输入的处理(「交替读处理」)。
此外,与上下文扩展不同,CoA利用LLM之间的通信能力来进行多智能体协作,而不是直接将大量tokens输入LLM。
CoA在计算成本上也具有优势,相比于全上下文方法,其时间复杂度从n²降到了nk,其中n是输入tokens的数量,k是LLM的上下文限制。
核心方法
假设大语言模型(LLM)的上下文窗口限制为k个标记(通常 k≪n),目标是在有限输入上下文窗口下生成输出y。
为此,将原始文本x分割为若干分块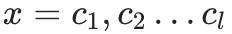 ,确保每个分块都能完整输入到LLM智能体的骨干模型中进行处理。
,确保每个分块都能完整输入到LLM智能体的骨干模型中进行处理。
整体流程如下:

CoA包含两个阶段。
在第一阶段,多个工作智能体(worker agents)协作,处理不同的长文本块,并聚合可用于回答问题的数据。
为此,工作智能体按照顺序读取和处理每个块,每个智能体都接收来自前一个智能体的信息,并将有用的更新信息传递给下一个智能体。
在第二阶段,管理智能体(manager agent)接收来自最后一个工作智能体的完整证据,并生成最终的回答。
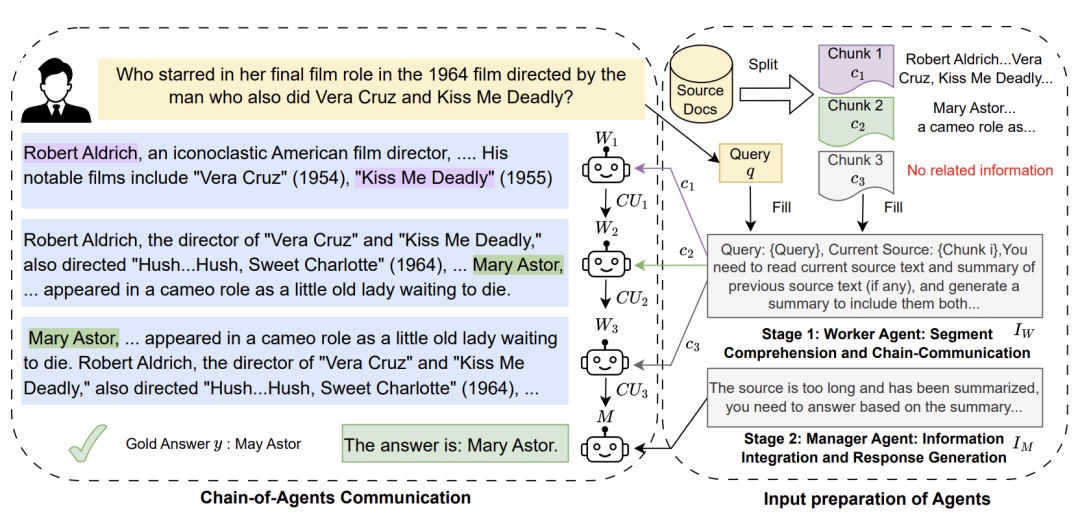
举个例子:
问题:「A的孙子是谁?」输入文本分块:[1],[2],[3],[4]每个块的支持数据:
[1]–A的配偶是D
[2]–A的孩子是B
[3]–无额外证据
[4]–B的孩子是C
智能体链过程:
问题:「A的孙子是谁?」
工作智能体对其块进行评估并执行相关任务:[1]—主题探索:A的配偶是D
[2]—解答第一步(hop):A的孩子是B
[3]—传递之前的证据:A的孩子是B
[4]—完成推理:A的孩子是B,B的孩子是C。因此,A的孙子是C
管理智能体:「是C。」
阶段1:工作智能体——文本理解与链式沟通
在阶段1中,CoA包含一系列工作智能体(worker agents),每个智能体接收来自源文本的部分内容ci、查询q、特定任务的指令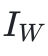 ,以及来自前一个智能体的消息。
,以及来自前一个智能体的消息。
传向下一个智能体的消息,在文中叫做「通信单元」(communication unit)
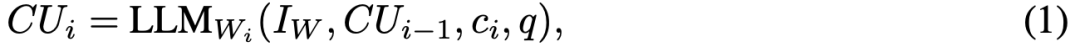
这个信息传递链是单向的,按顺序从一个智能体传递到下一个智能体。每个工作智能体处理各自的块,并将输出传递给下一个智能体。
阶段2:管理智能体——信息整合与答案生成
在阶段2中,经过工作器智能体多轮信息抽取与理解后,管理智能体将整合全局信息生成最终解决方案。
工作器智能体负责从长上下文源中提取相关信息,而管理智能体则通过聚合「工作器智能体链」末端积累的所有相关信息生成最终答案。
具体而言,管理智能体根据给定的指令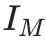 和查询q,评估最后一个工作智能体所积累的知识,最终生成回答:
和查询q,评估最后一个工作智能体所积累的知识,最终生成回答:
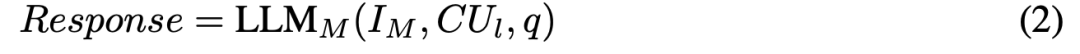
其中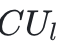 表示最后一个工作智能体所积累的知识。
表示最后一个工作智能体所积累的知识。
这样工作智能体和管理智能体通过分工合作,使每个智能体都能在专属职责范围内发挥最大效能。
「工作器智能体」执行分块处理, 分析长上下文;而「管理智能体」负责生成最终答案。
复杂度分析
从理论角度, 作者对比了仅解码器设置下全上下文输入与Chain-of-Agents(CoA)的时间开销。
假设大语言模型(LLMs)生成的响应平均包含r个标记,输入文本包含n个标记,LLM 的上下文限制为k,而RAG中每个分块的长度为k′。
时间复杂度的分析结果如表2所示。
可以看出,CoA的编码时间少于全上下文(Full context)输入,因为在长上下文任务中k≪n,而两者的解码时间相同。这证明了 CoA 相较于全上下文基线的高效性。

表2:不同方法的时间复杂度
具体实验结果
作者将CoA与两种来自输入缩减和窗口扩展方法的强基准进行比较:
-
RAG,使用先进的检索器获取最相关的信息输入LLM;
-
全上下文方法,将所有输入内容直接输入LLM直到上下文窗口限制。
与RAG方法的比较
实验结果表明,在多个数据集上,CoA(8k)显著优于全上下文(8k)和RAG(8k)模型。
在八个数据集中, 使用在不同的大语言模型(LLMs)的情况下,CoA均显著优于Vanilla和RAG方法。
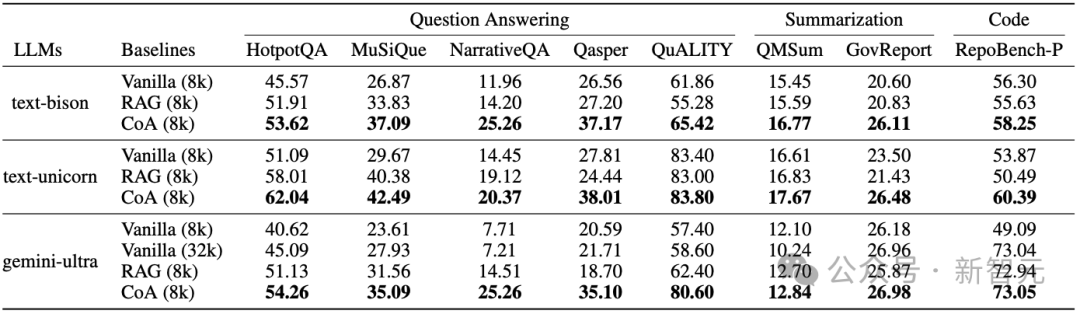
表 4:CoA与RAG等方法的比较。
与其他多智能体框架比较
如表6所示,CoA在所有八个数据集上均优于分层(hierarchical)和合并(merge)方法。
其背后的原因是分层和合并方法由于其并行设计,不允许工作器之间进行通信。
因此,每个工作器只能维护其自身分块中的信息,阻碍了对整体文本的理解,从而大大降低了性能。

表6:与其他多智能体框架比较。
结果分析
长文本任务的复杂推理
以HotpotQA数据集为例,RAG通过检索与查询语义相似的文本块来找到正确答案,但多跳推理(multi-hop reasoning)面临挑战,因为关键的第一步答案通常与查询的语义相关性较低。
相比之下,CoA的操作方式不同:在不知道答案的情况下,第一个智能体探索相关主题,帮助后续推理;第二个智能体也不知道答案,但引入了新信息,拓宽了话题范围;结合前面智能体的信息和新数据完成推理链, 第三个智能体最终找到了答案。

图5:HotpotQA 数据集上 RAG(左)与 CoA(右)的案例研究。
通过智能体间的顺序通信机制,CoA 能够在长上下文中执行复杂的多跳推理任务。
与长文本LLM的比较
在与长文本LLM(如Claude 3)在NarrativeQA和BookSum任务上的比较中,CoA(8k)显著超越了RAG(8k)和全上下文(200k)基准,即使后者的上下文窗口限制达到了200k。
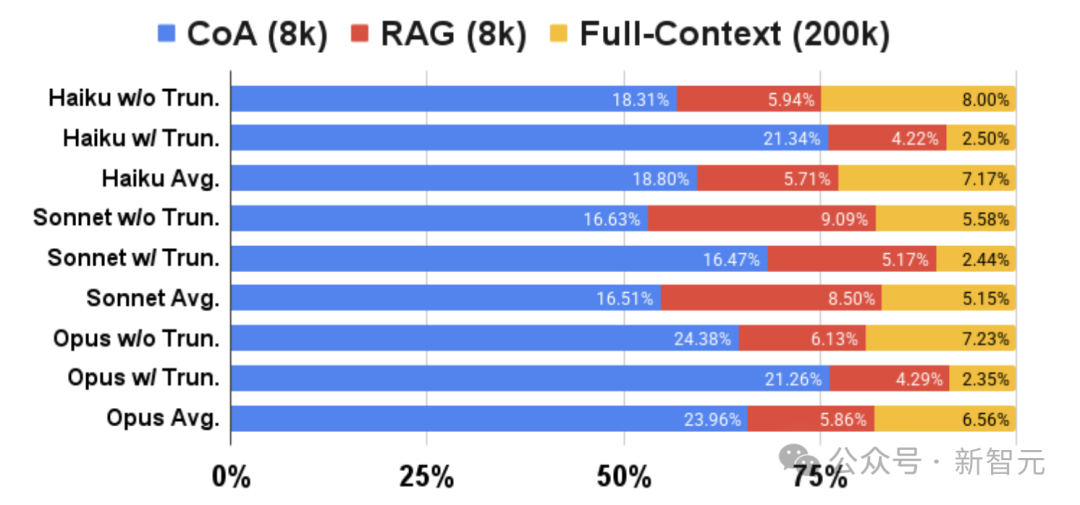
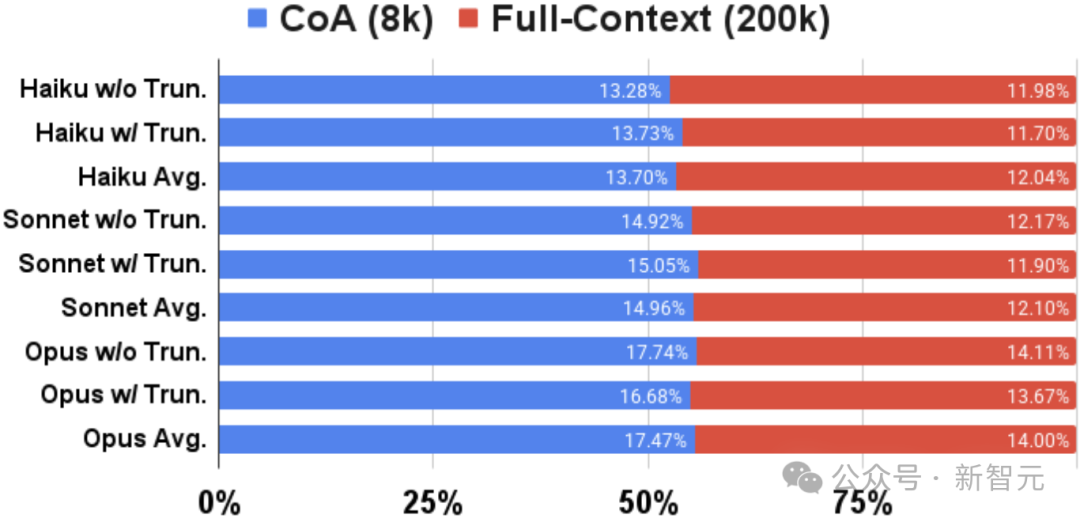
更长输入上的改进
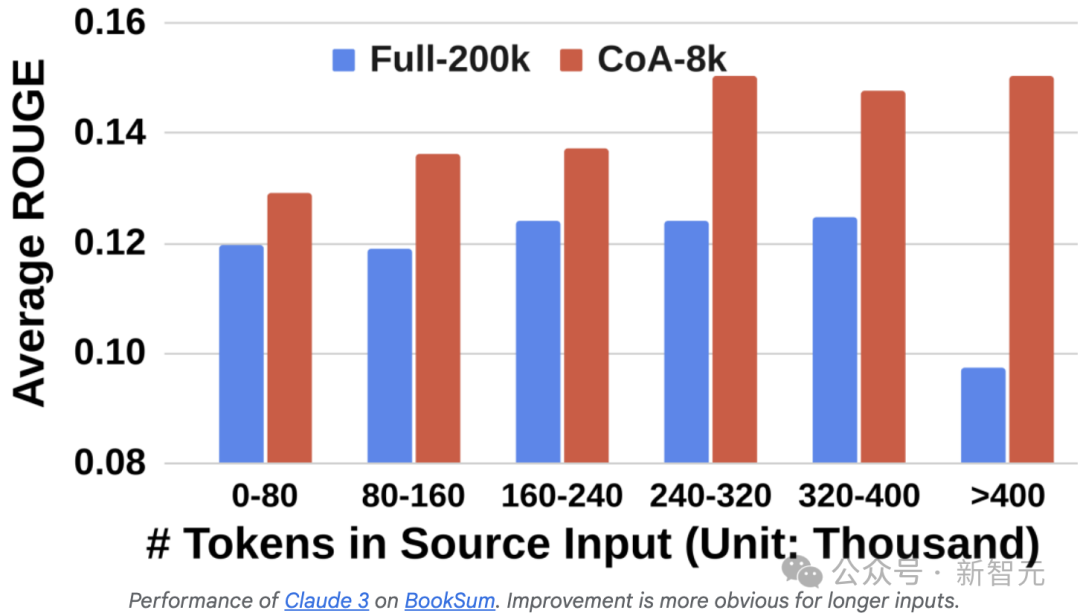
在BookSum数据集上,利用Claude 3模型,作者还比较了CoA和全上下文方法的表现。
如下图所示,CoA在不同长度的输入文本上均显著优于全上下文基线。
值得注意的是,随着样本长度的增加,CoA 的性能甚至有所提升,且相较于全上下文(200k)基线的优势更加显著。
值得一提的是,当输入长度超过400k时,CoA的性能提升幅度达到约 100%。
因此,作者得出以下结论:1)即使模型具有极长的上下文窗口限制,CoA 仍能提升 LLM 的性能;2)当输入文本更长时,CoA 带来的性能增益更为显著。
「中间丢失」效应
为了评估基线模型和CoA模型中的「中间丢失」效应,作者复现了下列文章。

文章链接:https://aclanthology.org/2024.tacl-1.9.pdf
结果如图4所示,CoA比全上下文方法表现出更强的鲁棒性,性能差距缩小至 4.89 (±1.91)。
这表明 CoA 通过为每个智能体提供较短的上下文以集中注意力,有效缓解了这一问题。
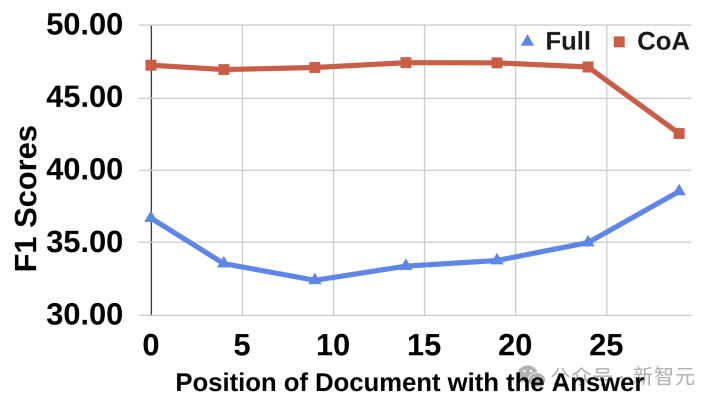
图4:CoA与全上下文方法在Natural Questions数据集上的性能表现。
文中也讨论了消融实验、信息损失等问题。
作者介绍

(文:新智元)