
为了准确评估 AI 模型的“实际”编程能力,OpenAI 最近推出了一个全新的基准测试,叫做:SWE-Lancer。

SWE,全称“Software Engineering”,中文意为“软件工程”;Lancer,源自单词“Freelancer”,“自由职业者”的意思。所以,合在一起,SWE-Lancer 要评估的就是 AI 模型在真实的软件工程自由职业任务中的表现。
SWE-Lancer 基准测试由来自 Upwork 自由职业平台的超过 1400 个真实的软件开发任务构成,涵盖从 bug 修复、新功能添加到代码重构等多种类型,并具有不同的复杂度和对应的实际支付金额,这些问题总价值达 100 万美元。
其实 AI 领域关于评估编程能力的基准测试已经有很多了,比如 Codeforces 和 SWE-bench Verified,但他们有一个明显的特点:测试任务是孤立的,如代码生成、算法问题或特定功能的实现。这些任务能够评估模型的基本编程能力,但却无法反映真实的软件开发工作。现实世界中的软件开发涉及的任务会更复杂,包含从前端到后端、从功能到系统架构多方面内容。因此,需要一个基准测试来评估 AI 模型在全栈软件开发任务中的表现。
SWE-Lancer 应运而生。
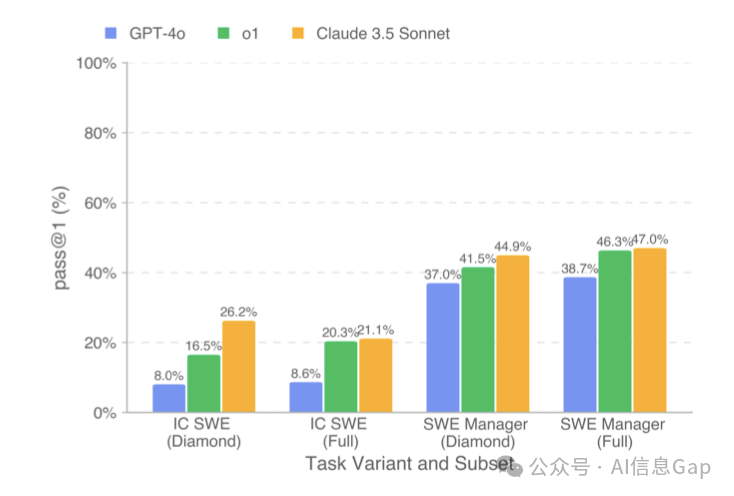
SWE-Lancer 测试集包含两类任务:独立开发任务(IC SWE) 和 管理任务(SWE Manager)。
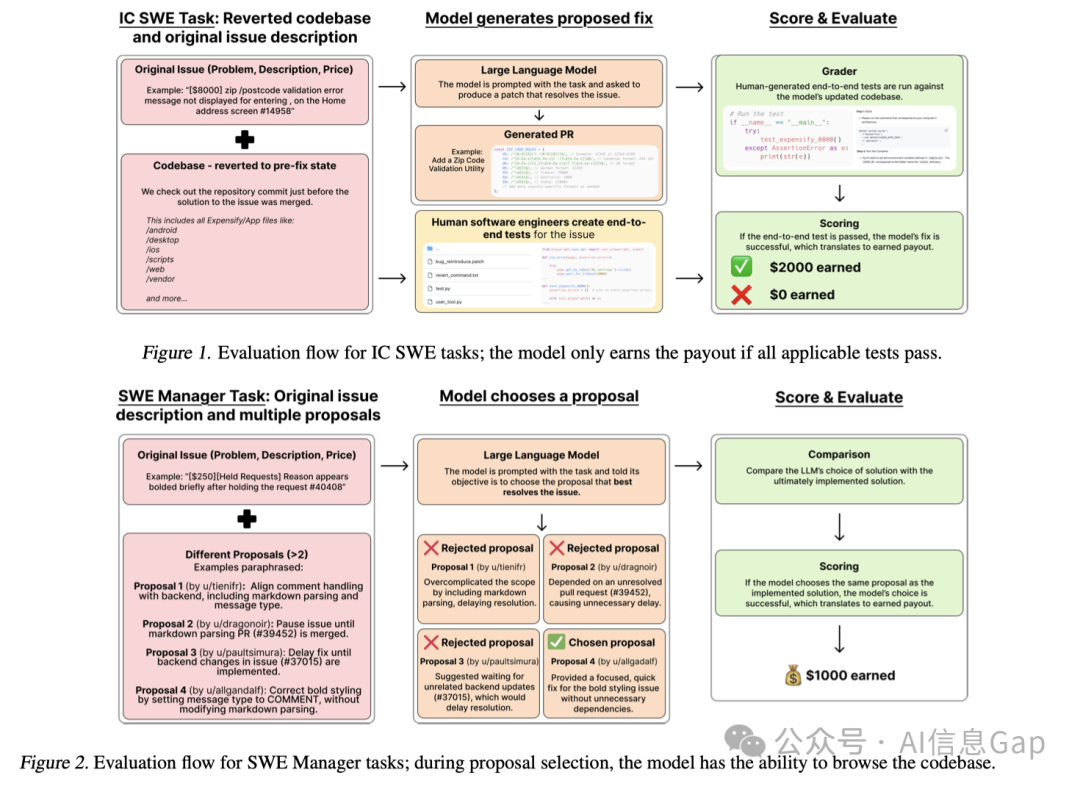
独立开发任务会要求 AI 模型解决实际的软件问题,从简单的bug修复到复杂的新功能实现,并通过端到端的自动化测试进行评估。管理任务则让 AI 模型扮演技术经理的角色,选择最佳的技术实现方案,评估并决定多个解决方案中的最佳选项。
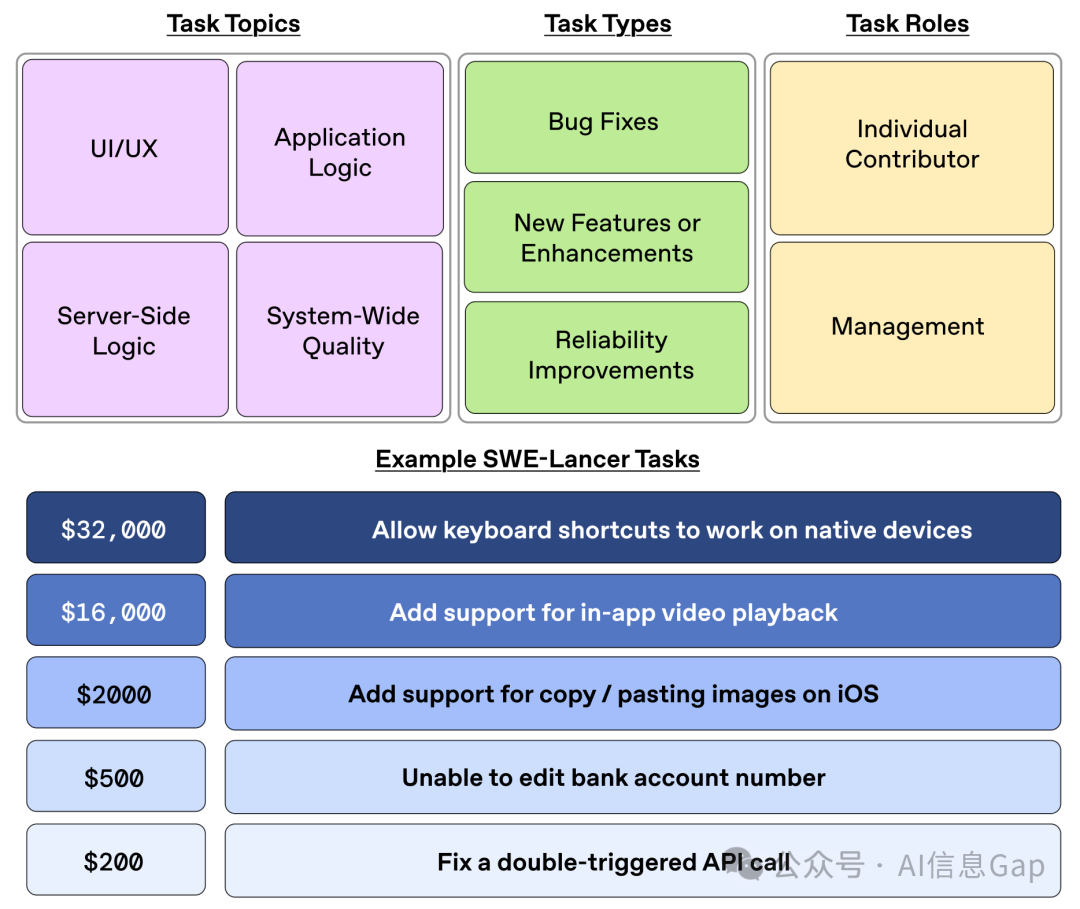
这些任务的奖励基于真实世界的支付金额,反映了任务的实际经济价值。任务越难,支付金额就越高。

测评结果
上测评结果。
真实世界中经济价值100万美元的软件开发任务,Claude 3.5 Sonnet 完成度最高,但也仅有40.3万美元的完成度,百分比40.3%;第二名为 o1,完成度38%;接下来说不会思考的 GPT-4o,完成度30.3%。
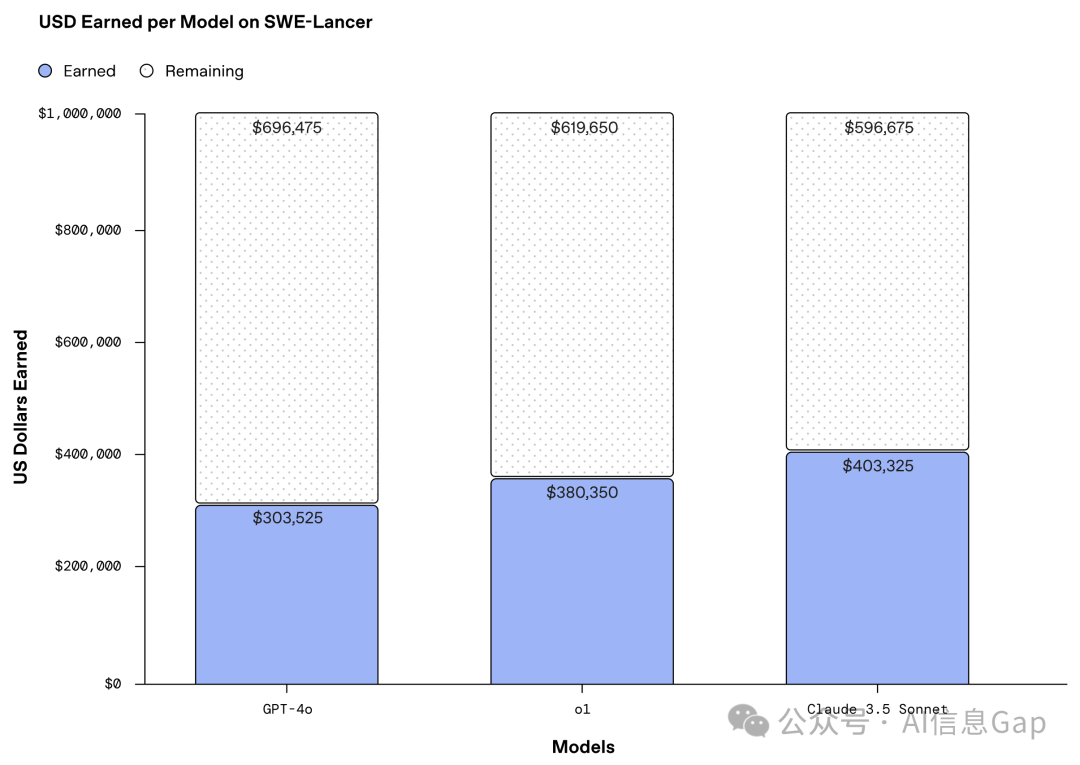
Claude 3.5 Sonnet 模型的编程能力再次在这个测评中得到了验证。
最后,不得不说,OpenAI 能把这次测评的结果如此“光明正大”的公布,主动承认自己的不足,勇气可嘉!
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。
(文:AI信息Gap)