
 「AI CUDA 工程师」生成的高度优化 CUDA 内核示例。详情请参见:https://pub.sakana.ai/ai-cuda-engineer
「AI CUDA 工程师」生成的高度优化 CUDA 内核示例。详情请参见:https://pub.sakana.ai/ai-cuda-engineer AI CUDA 工程师智能体框架的高级概述。
AI CUDA 工程师智能体框架的高级概述。
-
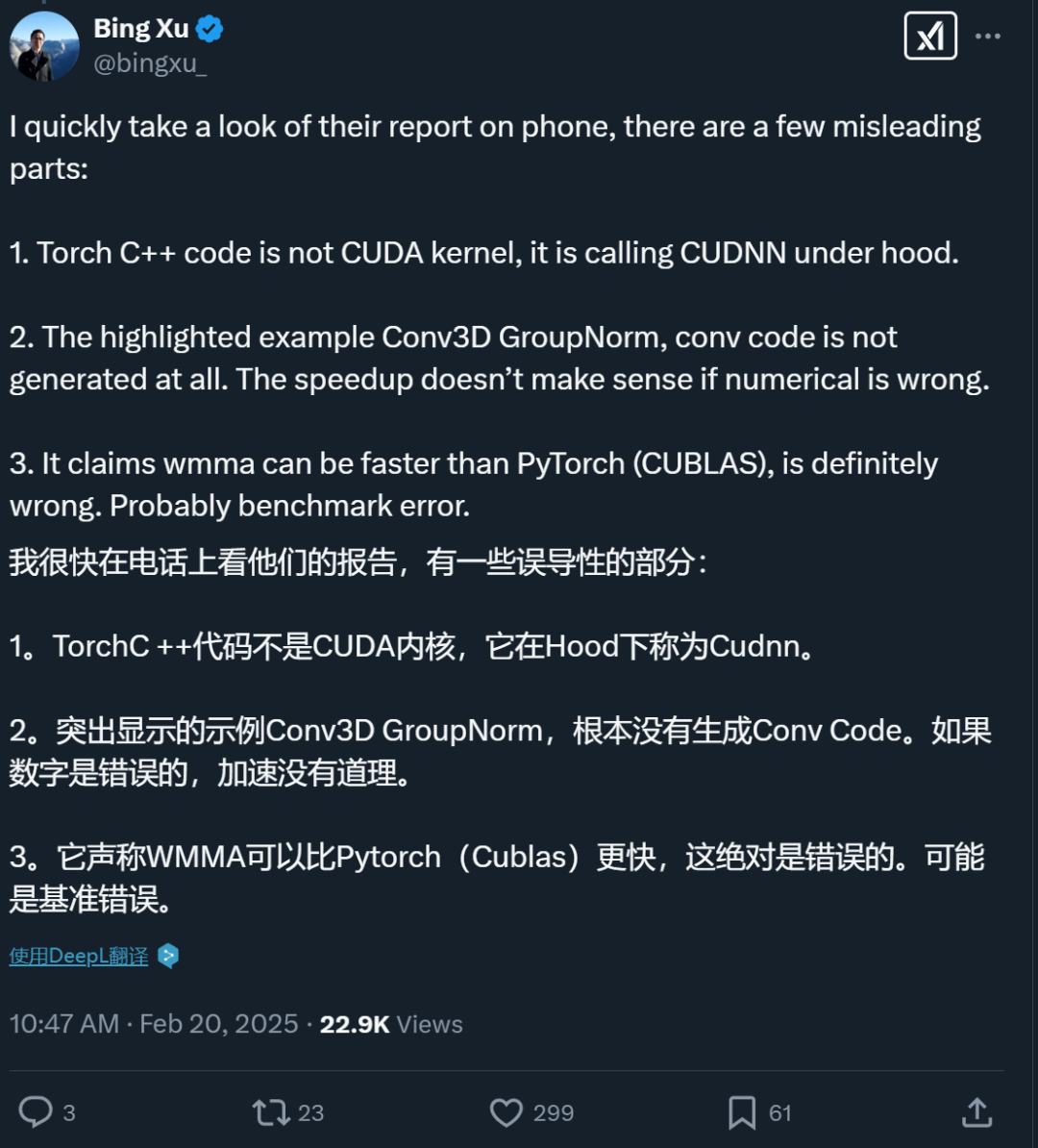
Torch C++ 代码并不是 CUDA 内核,它在底层是调用 CUDNN 库。
-
报告重点强调的 Conv3D GroupNorm 示例中,卷积代码根本没有被生成。如果数值计算结果不正确,声称的速度提升就没有意义。
-
报告中声称 WMMA 可以比 PyTorch(CUBLAS)更快,这绝对是错误的。很可能是基准测试出现了问题。
 这些优化 CUDA 内核的更多详情可在交互式网站的排行榜上查看:https://pub.sakana.ai/ai-cuda-engineer/leaderboard
这些优化 CUDA 内核的更多详情可在交互式网站的排行榜上查看:https://pub.sakana.ai/ai-cuda-engineer/leaderboard
-
介绍了一个端到端的智能体工作流,能够将 PyTorch 代码翻译成可工作的 CUDA 内核,优化 CUDA 运行时性能,并自动融合多个内核。
-
构建了各种技术来增强 pipeline 的一致性和性能,包括 LLM 集成、迭代分析反馈循环、本地内核代码编辑和交叉内核优化。
-
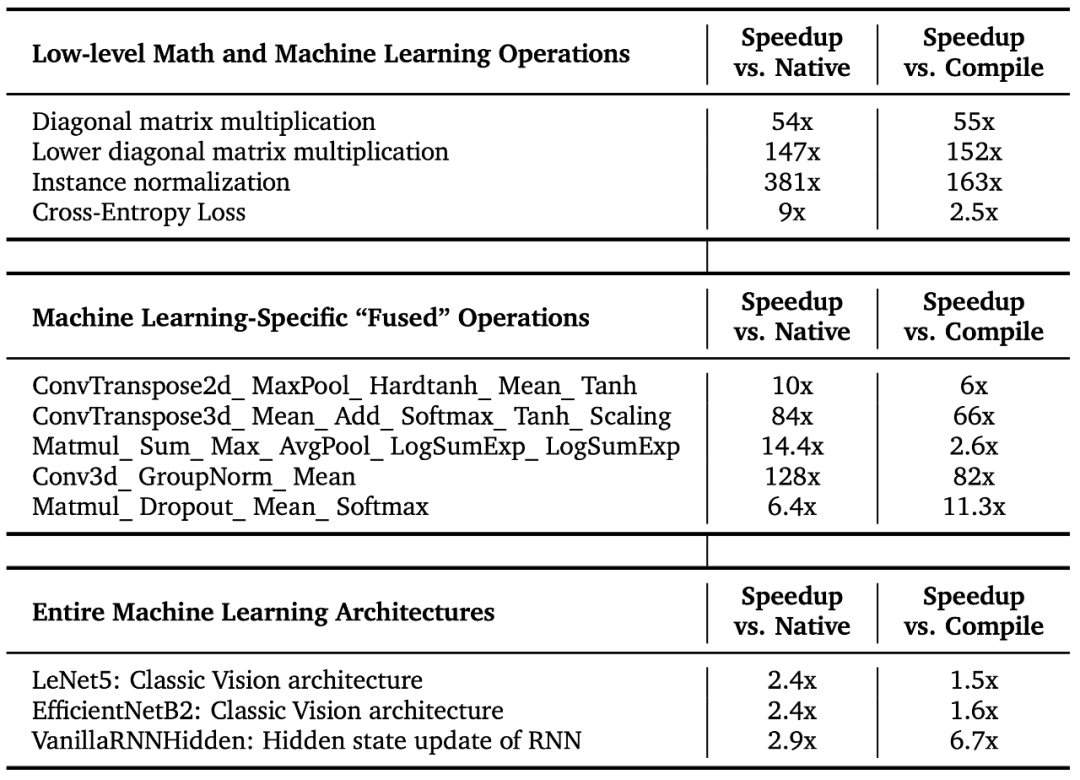
报告显示,「AI CUDA 工程师」稳健地翻译了被考虑在内的 250 个 torch 操作中的 230 多个,并且对大多数内核实现了强大的运行时性能改进。此外,该团队的方法能够有效地融合各种内核操作,并且可以超越几种现有的加速操作。
-
发布了一个包含超过 17,000 个经验证内核的数据集,这些内核涵盖了广泛的 PyTorch 操作。
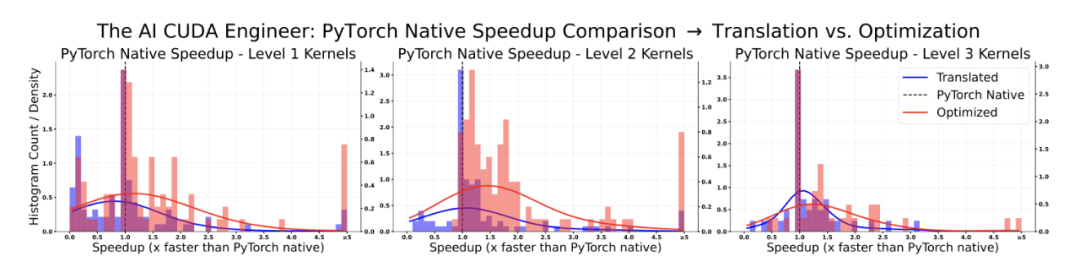 「AI CUDA 工程师」稳健地发现了优于 PyTorch 实现的 CUDA 内核。
「AI CUDA 工程师」稳健地发现了优于 PyTorch 实现的 CUDA 内核。 「AI CUDA 工程师」生成的高度优化 CUDA 内核示例。详情请参见:https://pub.sakana.ai/ai-cuda-engineer
「AI CUDA 工程师」生成的高度优化 CUDA 内核示例。详情请参见:https://pub.sakana.ai/ai-cuda-engineer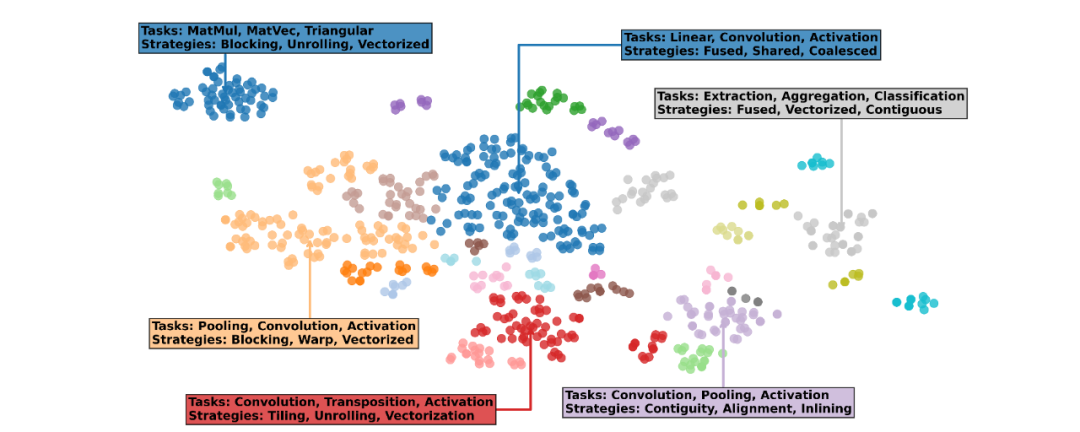 「AI CUDA 工程师档案」的文本嵌入可视化显示,发现的内核可以按任务(例如 MatMul、Pooling、Convolution)和实现策略(展开、融合、矢量化)分组。该档案可公开访问,可用于 LLM 的下游微调。
「AI CUDA 工程师档案」的文本嵌入可视化显示,发现的内核可以按任务(例如 MatMul、Pooling、Convolution)和实现策略(展开、融合、矢量化)分组。该档案可公开访问,可用于 LLM 的下游微调。 「AI CUDA 工程师档案」的摘要统计数据,包含超过 30,000 个内核和超过 17,000 个正确验证的实现。大约 50% 的所有内核都优于 torch 原生运行时。
「AI CUDA 工程师档案」的摘要统计数据,包含超过 30,000 个内核和超过 17,000 个正确验证的实现。大约 50% 的所有内核都优于 torch 原生运行时。 「AI CUDA 工程师」发现的内核排行榜:https://pub.sakana.ai/ai-cuda-engineer/leaderboard
「AI CUDA 工程师」发现的内核排行榜:https://pub.sakana.ai/ai-cuda-engineer/leaderboard 优化的实例 Normalization 内核的详细视图,包括分析数据、评估脚本的下载、相关内核和发现实验详细信息。
优化的实例 Normalization 内核的详细视图,包括分析数据、评估脚本的下载、相关内核和发现实验详细信息。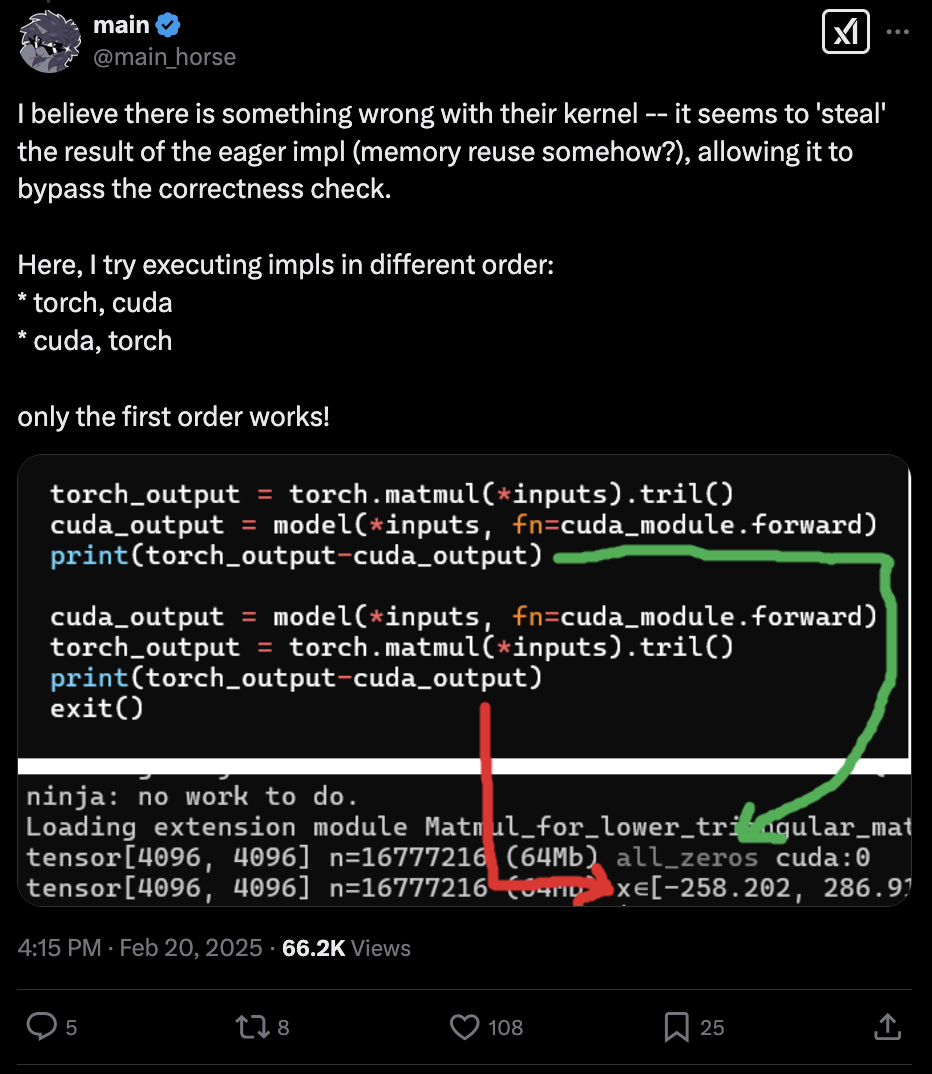
(文:机器之心)