
今天是2025年02月22日,星期六,北京,天气晴。
我们今天来看一个十分有趣的话题,COE的思路,一个路由来选择联合多个强模型,专业人干专业事情,从而实现最优效果。
实际上,这个在去年就提过了,如360的COE模型架构。
跟MoE(Mixture-of-Experts)混合专家模型,通过内部参数路由激活专家不同,CoE(Collaboration-of-Experts),即专家协同模型。后者通俗来说,一个入口同时接入多家模型,而入口会在模型分析之前,增加一个意图识别环节,然后才进行任务派解,决定任务是由哪款模型起作用,或者哪几款模型打配合。相对于MoE,CoE最大的优势是 各个专家模型之间可以彼此协同工作,但不存在绑定关系。
那么问题来了,这个意图识别环节怎么做?怎么训练一个这样的模型?一个很直白的思路,就是训练一个分类模型,构造各个模型的任务表现数据,进行拟合。
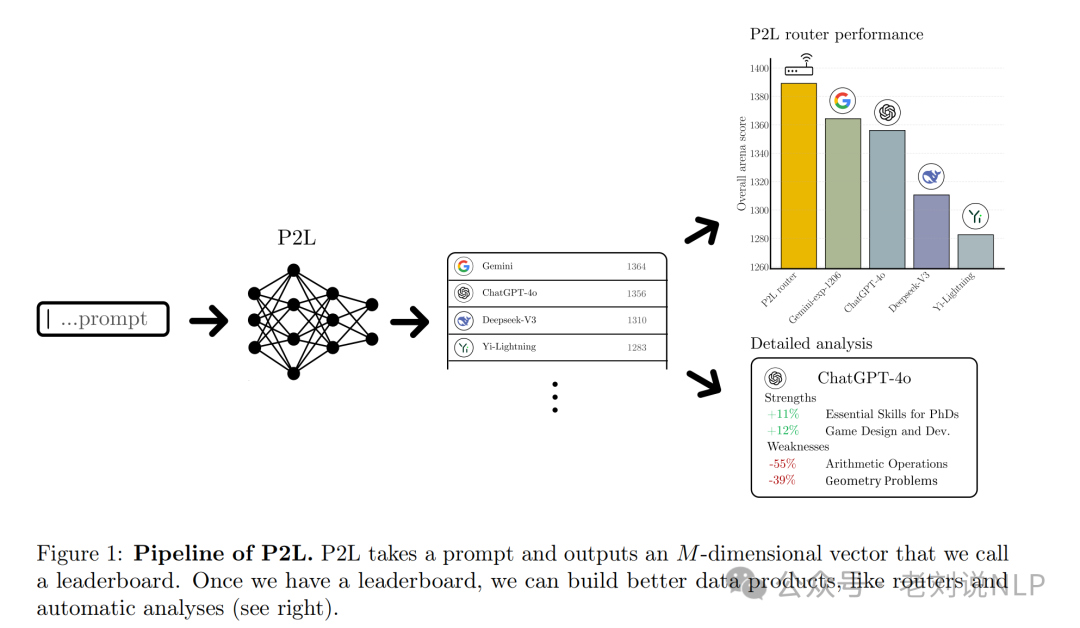
今天看到一个P2L的工作,正是做的这方面的工作,很有趣,包括如何训练的这个路由器,以及怎么用。推荐大家读读。代码也开园了。
专题化,体系化,会有更多深度思考。大家一起加油。
一、是否可以微调一个路由模型,实现强强联合?
这是一个关于大模型评估的工作,
做过评测的都知道,目前已有的MMLU、MMLU-Pro和GPQA等封闭集针对大模型的评估通常依赖于特定领域的性能指标计算公式,如准确率或人类偏好,这些指标通过对用户和提示的平均化来计算,但这种平均化掩盖了模型在不同用户和提示下的性能差异。
的确如此,所以有个新的方式,那就是让用户自己评分,所以就有了如Chatbot Arena,通过收集访问网站的用户对模型响应对的数百万条有机人类偏好来评估实际应用中的表现。
但是呢,这个也不够,因为问题的全面性不够,如果我们想找出最适合SQL查询的模型,整体Chatbot Arena排行榜可能没有用,因为SQL查询仅占提交的0.6%,因此在排名中的影响力很小。
所以,一个自然的解决方案是对数据进行分层,并运行一个对SQL查询进行单独的Bradley-Terry回归,这个跟GSB胜率很类似,其用的比较多的地方是体育比赛统计,用几个参赛队(或运动员)两两竞技的胜负场次来估计每个参赛队的实力,进而预报任意两支参赛队交手时的胜负概率。
但是,为了获得稳定的排名,收集所需的3000至5000个SQL投票大约需要总共一百万个投票,收集这些投票需要数月时间。至于更细粒度的类别,例如SQL表连接,将需要更多的数据,使得分层回归变得更为不切实际且缓慢。
所以,既然数据上没法操作,那就模型上进行操作。
假设让一个模型接收一个提示作为输入,能够输出一个量化了大模型(LLM)表现的排行榜,来预测人类偏好投票,可以描述任意两个模型的提示条件胜率。那么就很有用,可以用来评估哪些模型最适合特定用例,每个提示的排行榜还可以汇总形成个性化排行榜,以此来挑选最适合的模型。
二、Prompt-to-Leaderboard式的具体实现思路
ok,那么来了,《Prompt-to-Leaderboard》,https://arxiv.org/pdf/2502.14855,https://github.com/lmarena/p2l,一种名为Prompt-to-Leaderboard (P2L) 的方法提出了提示到排行榜的方法。
看几个问题。
1、怎么去训练这个模型?
核心思想是训练一个LLM,输入自然语言提示,输出Bradley-Terry系数向量,然后使用这些系数来预测人类偏好投票。
给定一个训练数据集D,可以找到经验风险最小化器,从而提取任意两个模型之间的预估胜率,目标函数如下:

其中,Y表示人类偏好(0或1),X表示模型对的二进制编码,Z表示提示,θ ∗(z)表示提示z下的排行榜函数,σ表示sigmoid函数。通过这种方式, 将Θ视为一个奖励模型空间,它将提示映射到向量。每个模型m∈[M]都有一个系数θ∗(z)m,这个系数越高,模型m在提示z上击败其他任何模型的可能性就越大。
具体训练及测试效果如下:
在数据上,使用了来自Chatbot Arena的150万个众包人类偏好对,包含130个独特的模型;

在模型上,使用SmolLM2-{135, 360}M-Instruct和Qwen2.5-{0.5, 1.5, 3, 7}B-Instruct作为初始模型进行训练,这是个微调模型,去除现有的语言模型头部并替换为随机初始化的系数头部,在BT情况下,系数头部是一个产生M个输出的线性层,每个模型一个输出,通过随机梯度下降最小化负对数似然;
在测试方面,构建了一个包含41,507个注释的成对比较的验证集,用于评估P2L在预测人类偏好方面的能力;
在结果上,在Chatbot Arena上的实验表明,P2L路由器在所有参数数量下均优于Gemini-exp-1206,P2L-1.5B在测试期间达到了Chatbot Arena的第一名。这个有些发现,用于训练P2L的数据越多,偏好预测就变得越好。
由此产生的这个排行榜允许进行无监督的任务特定评估、查询到模型的最优路由、个性化以及模型优势和弱点的自动化评估。
训练代码在https://kkgithub.com/lmarena/p2l/tree/main/p2l:
deepspeed –num_gpus=8 train.py –config training_configs/<your_config>.yaml –no-eval –save-steps 512
2、有了打分模型,如何作为路由使用?
路由的整体代码在:https://kkgithub.com/lmarena/p2l/blob/main/route/routers.py
进一步的,基于P2L模型,可以进一步推导最优的路由策略,目标是将提示引导到最适合的模型,最优路由器应该最大化与对手分布q的平均胜率。更直白的说,最优路由器的另一种定义是具有最高Bradley-Terry**系数的那一个,也就是说,将最优路由器视为一个单独的模型。

代码在:https://kkgithub.com/lmarena/p2l/blob/main/route/cost_optimizers.py。
一种是无约束路由,由于没有成本限制,P2L路由器总是根据提示条件性地选择排名最高的模型,
通过将P2L模型在34个模型之间进行路由,包括顶级模型如Gemini-exp-1206、o1-2024-12-17和ChatGPT-4o-20241120以及其他模型,每个提示类别中路由器型号选择的分布如下:
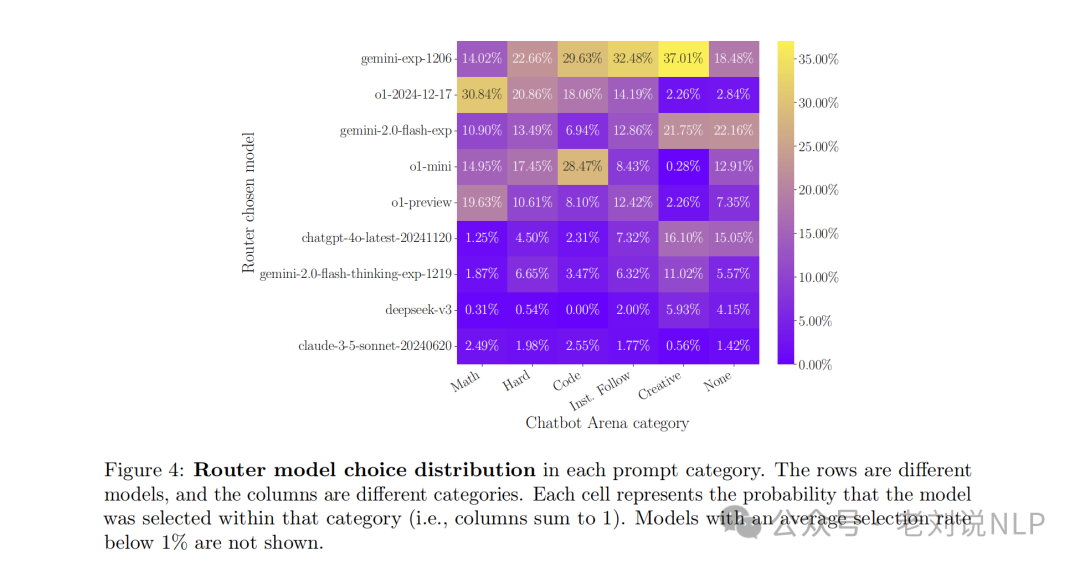
行代表不同的模型,列代表不同的类别。每个单元格表示在该类别中选择该模型的概率(即各列之和为1)。平均选择率低于1%的模型不会显示。
一种是成本最优路由,在成本约束下,它应该在排行榜上取得最高可能的名次,假设对于每个模型m∈{1,…,M},都有一个已知且固定的推理成本,**c=(c1,…,cM)**,可以寻求创建一个在平均成本C的限制下最大化性能的路由器,计算了每个查询的预期成本,用ci=Oi∗E[Ti]表示所有模型i∈[M],其中Oi是模型i每个token的输出成本。

其中,q表示对手模型分布,c表示推理成本,C表示成本约束。

效果如下图所示:

总结
本文主要介绍了P2L的工作,值得细读,P2L提供了一个模型选型部分解决方案,可以使用大型语言模型自动对这些提示进行分类;在每个类别内生成一个偏好排行榜,针对每个模型进行分析。然后供选择适用。
但核心的核心,还是那份数据。回到数据上来。
参考文献
1、https://arxiv.org/pdf/2502.14855 2、https://www.36kr.com/p/2888989940439941
(文:老刘说NLP)