

极市导读
本文研究了基于GLU变体的大型语言模型在后训练量化时面临的激活量化挑战,发现GLU激活中的“激活尖峰”会导致显著的量化误差。为此,作者提出了两种方法:量化自由模块和量化自由前缀,通过在量化过程中隔离这些激活尖峰,有效提升了量化模型的性能,尤其是在粗粒度量化方案下,显著改善了模型的推理效率和性能。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
太长不看版
借助前缀削弱激活异常值,改善 LLM 后训练量化。
量化方案:
Weight: Per-channel,Activation:Per-tensor Dynamic
现代大型语言模型 (LLM) 通过架构改进建立了最先进的性能,但仍然需要大量的计算成本进行推理。
后训练量化 (Post-Training Quantization) 是大模型轻量化的一种流行方法,把 weight 和 activation 表示为低比特,比如 INT8。本文中,作者揭示了基于 GLU[1]的 LLM (常见于现代 LLM 模型的 FFN 层,如 LLaMA) 中 activation 量化的挑战。作者将这些 activation 称之为 activation spike。
作者列举了activation spike 的一些特点:
-
activation spike 发生在特定层的 FFN 中,尤其是在早期的层和后期的层中。 -
activation spike 专门存在于一些特定的 tokens 中,而不是在整个序列中都有。
为了隔离量化过程中的 activation spike,本文实证性地提出了 2 种方法:Quantization-free Module (QFeM) 和 Quantization-free Prefix (QFeP)。作者在很多具有 GLU 变体的最新 LLM 中验证了所提出的激活量化方法的有效性,包括 LLAMA-2/3、Mistral、Mixstral、SOLAR 和 Gemma。
本文目录
1 降低 LLM 中因 Activation Spikes 导致的量化误差
(来自 Hanyang University)
1 Activation Spikes 论文解读
1.1 Activation Spikes 研究背景
1.2 Activation Spikes:GLU 激活函数带来超大激活值
1.3 Activation Spikes 对量化的影响
1.4 缓解量化质量退化:免量化模块
1.5 缓解量化质量退化:免量化前缀
1.6 实验设置
1.7 主要结果
1.8 消融实验结果
1.9 计算复杂度分析
1 降低 LLM 中因 Activation Spikes 导致的量化误差
论文名称:Mitigating Quantization Errors Due to Activation Spikes in GLU-Based LLMs
论文地址:
http://arxiv.org/pdf/2405.14428
代码链接:
http://github.com/onnoo/activation-spikes
1.1 Activation Spikes 研究背景
大语言模型 (LLM) 通常会采用 GLU[1]、RoPE[2]、GQA[3]和 MoE[4]等架构改进,拓宽了自然语言任务的基本能力和各种应用的潜力。尤其是,考虑到训练效率的缘故,大多数现代 LLM 架构 (如 LLaMA 家族) 都采用了门控线性单元 (Gated Linear Unit, GLU) 变体 (如 SwiGLU、GeGLU)。但是,大模型中的数十亿个参数对用户施加了相当大的计算成本。为了减少 GPU 显存需求并加快推理速度,后训练量化 (PTQ) 通过将权重和激活量化为低精度 (例如 INT8) 来降低使用成本。然而,最近的研究表明,LLM activation 中的某些位置存在很大幅值的数值,通常称为异常值,对 activation 的量化提出了关键的挑战。有一些工作试图解释异常值在注意力机制中的作用[5]。然而,目前对不断发展的 LLM 架构对异常值影响的研究仍然不足。
本文作者发现 FFN 中的 GLU 架构会产生过大的 activation 值,这些 activation 值造成局部量化误差显著。具体来说,作者观察到这些有问题的激活值出现在特定的线性层中,并且专门用于几个 token。为了区分 GLU 中过大的 activation 与异常值 (Outlier),作者将前者称为激活值尖峰 (Activation Spike)。鉴于本文的观察,作者提出了两种方法来减轻 Activation Spike 对量化的影响:免量化模块 (Quantization-free Module, QFeM) 和免量化前缀 (Quantization-free Prefix, QFeP)。
免量化模块 QFeM: 目的是排除一部分发生较大量化误差的线性层 (或模块) 的量化,而不是量化 LLM 中的所有线性模块。QFeM 会排除掉那些 scale 差异程度大的线性模块。
免量化前缀 QFeP: 目的是识别触发激活值尖峰的前缀 (Prefix),并将其上下文存储在 key-value (KV) cache 里面,从而防止后续 token 中激活值尖峰的递归。值得注意的是,QFeM 和 QFeP 都依赖于校准结果来提前捕获激活峰值,无需对要做量化的 LLM 进行任何修改。这表明本文方法可以集成到任何现有的量化方法中。
1.2 Activation Spikes:GLU 激活函数带来超大激活值
最近的工作[5]研究了现代 LLM 的隐藏状态中存在的一种新的异常值。尽管这些异常值在 Transformer 中的 Attention 中起了至关重要的作用,但是其与输入 activation 之间的关系还没得到充分的探索。作者关注每个线性层之前的 input activation。具体而言,作者检查了 4 个线性层:Query,Out 的投影,以及 FFN 中 Up 和 Down 投影。
为了分析 input activation,作者采用了一种校准方法,用于估计 scale 和 zero point 等量化因子。校准数据使用从 C4[6]训练数据集中随机收集的 512 个样本。之后,将每个样本输入到 LLM 中,并监控每个隐藏状态和 input activation。为了估计比例因子,使用绝对值的最大值。
观察1:GLU-implemented LLM 在特定层会出现 Activation Spikes。
在图 1 中,作者展示了实现 GLU-implemented 的 LLM (例如,SwiGLU、GeGLU) 的校准比例因子。从结果中可以观察到一些共性。在前期和末期的层中,FFN 中的 Down Projection 模块会出现显著的 input activation。这些输入激活来自 GLU 中的 Hadamard 积。因此,GLU 变体在特定层会生成 Activation Spikes。有趣的是,作者注意到大规模激活尖峰的出现和中间隐藏状态之间存在高度相关性。这表明 FFN 通过残差连接中的加法操作有助于放大隐藏状态。一旦隐藏状态的幅值爆炸,就会在不同的层中持续存在,直到在后期层遇到 Activation Spikes。

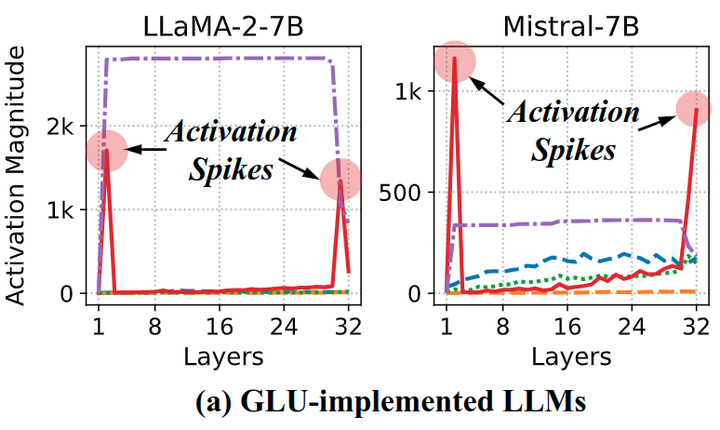
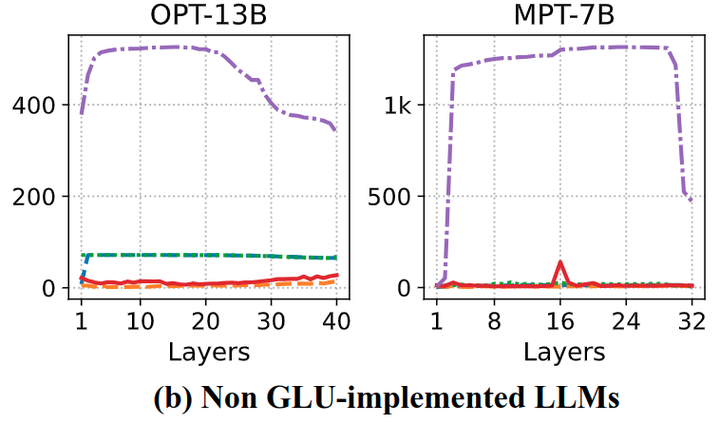
观察2:Non GLU-implemented LLM 显示适度的分布。
图 2 说明了在Transformer 中具有原始 FFN 实现的 LLM 的结果。可以观察到 LLM 的 hidden state 也会同样有较高的幅值,与[5]中的观察结果相呼应。但是,图 2 也说明 hidden state 比较大的幅值并没有转移到线性层的 input activation 上面。恰恰相反的是,GLU-implemented 的 LLM 形成了 Activation Spikes。这些结果也展示了 GLU-implemented 的 LLM 在量化方面的挑战,尤其是在前期的层和后期的层中。
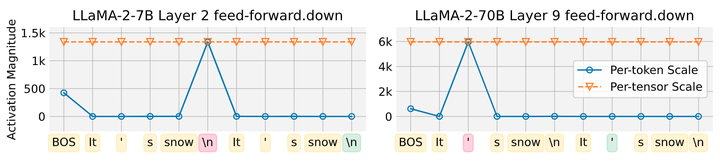
在上一节中,观察到了因为 GLU 激活函数导致 input activation 出现过大的异常值的情况。在量化 input activation 的时候,每个 token 的 input activation 的方差会影响量化性能。在图 3 中可以观察到,给定一个 token 序列,在几个 token 中观察到大量 input activation,例如 BOS token, newline (\n), 和 apostrophe (‘)。这些特定的 token 与[5]中的观察结果一致,表明此类 token 会在 hidden state 中表现出异常值。因此,Activation Spikes 与 Transformer 层为这些 token 分配特殊作用的过程相联系。但是,这些特定 token 的很大的值影响了其他 token 的量化,尤其是在 per-tensor 的量化中。
1.3 Activation Spikes 对量化的影响
作者还探讨了 Activation Spikes 对量化的影响。为了识别发生 Activation Spikes 的层,作者计算了 input activation 幅值的最大值和中位数之间的比例。线性层 中的 max-median ratio 可以表示为:
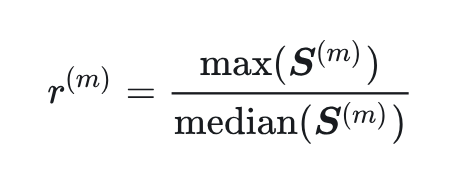
其中, 表示模块 的 token-wise 的 input activation 的幅值。这个比例反映了了最大幅值支配其他 token 幅值的程度。为了比较,作者根据这个比例按照降序选择前 4、中 4 和后 4 个模块,再使用校准数据集评估困惑度和均方误差 (MSE)。这里的 MSE 是针对原始 (FP16) 和部分量化 LLM 之间的最后一个隐藏状态计算的。结果如图 4 所示,前 4 模块上的量化会显著降低 LLM 性能,其他情况的性能下降可以忽略不计。作者认为这些对量化敏感 input activation 是量化瓶颈,在本文中,它指的是异常值引起的量化误差。
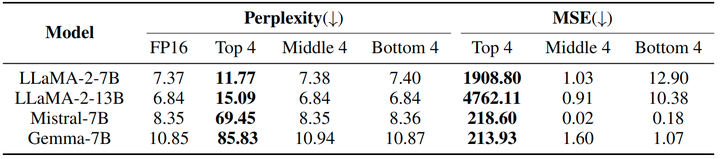
为了解决量化的瓶颈,本文的方法基于 Activation Spikes 常见的模式。首先,Activation Spikes 出现在特定的层中。这意味着对 LLM 直接量化会受到这些瓶颈的影响。其次,作者发现 Activation Spikes 源于一些特定的 token 第一次出现的时候。因此,如果我们可以让这些特定的 token 按照我们的想法 “有计划” 地出现,那么就可以阻止 Activation Spikes 在未来 token 中的出现。下面就是针对这两个现象的针对性方案:
1.4 缓解量化质量退化:免量化模块
在 LLM 的量化中,LLM 中的所有线性层都被量化。在这些线性层中,作者提出略去一些线性层的 input activation 的量化,那么这些线性层里面 Activation Spikes 引起了显著的量化误差。值得注意的是,增加不量化模块的数量会在推理时延与模型性能之间取得平衡。因此,确定应该量化哪些模块对于保留量化的功效至关重要。
因此,作者定义了一个阈值 ,如果 max-median ratio 大于这个阈值,这个模块的 input activation 就不进行量化。例如,如果 ,则所有线性层都被量化。为了控制 activation 量化的影响,作者将未被量化的线性层中的 weight 保留为 INT8,并将其在进行矩阵乘法时 dequant为 FP16。不量化 activation 的模块其实就相当于仅权重量化。
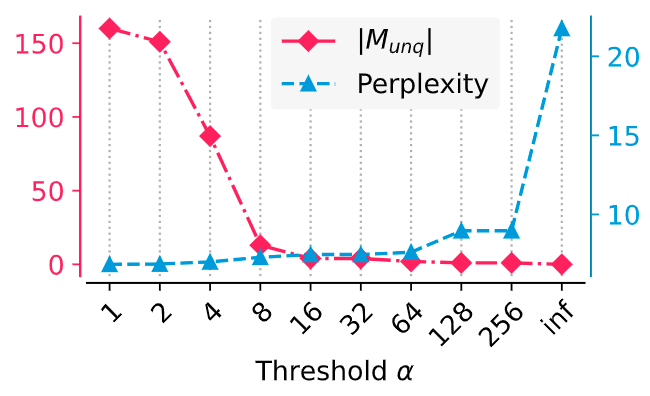
优化阈值
阈值 与其对性能 (通过校准集进行评测) 的影响之间的关系如图 5 所示,展示了量化如何降低性能。作者不做完全量化,而是通过找到两个性能曲线的交集来识别最佳阈值。在图 5 中,这个阈值约为 16。
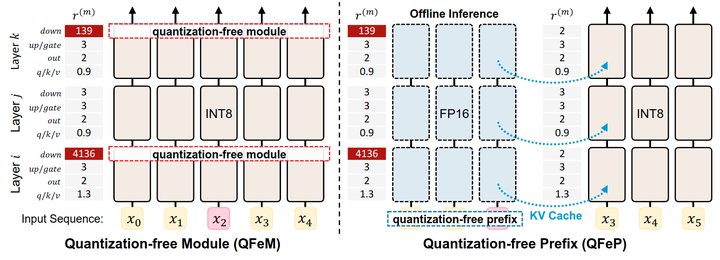
1.5 缓解量化质量退化:免量化前缀
免量化前缀通过预先计算好对应于 Activation Spikes 的 Prefix 来减轻量化误差。受这种 Activation Spikes 发生模式的启发,本文的目标是构建一个 Prefix,该 Prefix 会稳定之后标记的量化参数。换句话说,一旦 Prefix 在开始时是固定的,Activation Spikes 始终出现在 Prefix 中。之后,作者采用 KV cache 机制提前处理 Activation Spikes。在实践中,KV cache 用于通过存储先前 token 预计算的 Key, Value 来优化因果语言模型的解码速度。Prefix 的 KV cache 通过 LLM 的离线推理预计算一次,不进行量化。然后,KV cache 被用于量化阶段,如校准或动态量化。
前缀搜索
为了形成 Activation Spikes 的前缀,作者首先识别具有最大 max-median ratio 的 Activation Spikes 的候选 token。例如,候选 token 可以是 LLaMA-2-70B 模型的 apostrophe (‘) token,如图 6 中的红色所示。一旦确定了候选 token,就会搜索 BOS token 和前缀中的候选 token 之间的中间上下文 token。最后,准备搜索得到的 Prefix 的 KV cache。
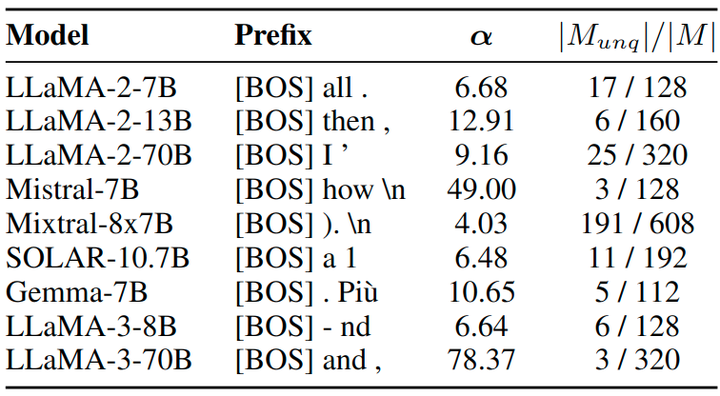
实现细节
在前缀搜索阶段,作者使用校准数据集。对于候选 token,作者考虑 input activation 幅值最大的前 3 个标记。然后在校准数据集中前 200 个最频繁的 token 中搜索中间上下文 token,它是词汇表 V 的子集。最后,通过搜索结果,以 FP16 精度为目标模型准备 KV cache。图 7 显示了搜索的前缀。
1.6 实验设置
模型
本文的方法 QFeM 和 QFeP 旨在减轻由 Activation Spikes 引起的量化瓶颈,尤其是在基于 GLU 的 LLM 变体中。为了验证所提出的方法的效率,作者根据他们的论文和源代码测试了使用 GLU 实现的 LLM。最近的 LLM,包括LLAMA2-{7B, 13B, 70B}、LLaMA-3-{7B, 70B}, Mistral-7B、Mixstral-8x7B、SOLAR-10.7B 和 Gemma-7B,都用了 GLU 架构。
量化设置
在实验中,作者量化了 INT8 矩阵乘法操作的 input activation 和线性层的权重。在这些线性层中,使用 dynamic per-tensor quantization 作为 input activation 的量化方案,使用 per-channel quantization 作为 weight 的量化方案。对于 input activation 和 weight,作者使用 absolute maximum value 估计 scale,作对称量化。为了比较,使用 FP16 和 per-token activation 量化[7]作为比较的 Baseline。
评估
作者使用两个指标评估量化的 LLM:Zero-Shot 的评估精度和困惑度。对于 Zero-Shot 评估,使用 4 个数据集:PIQA、LAMBADA、HellaSwag 和 WinoGrande。作者利用 lm-evaluation-harness 库来评估 Zero-Shot 任务。为了衡量困惑度,使用 WikiText-2 数据集。所有情况下默认使用 [BOS] token 作为每个输入序列的起始 token。
1.7 主要结果
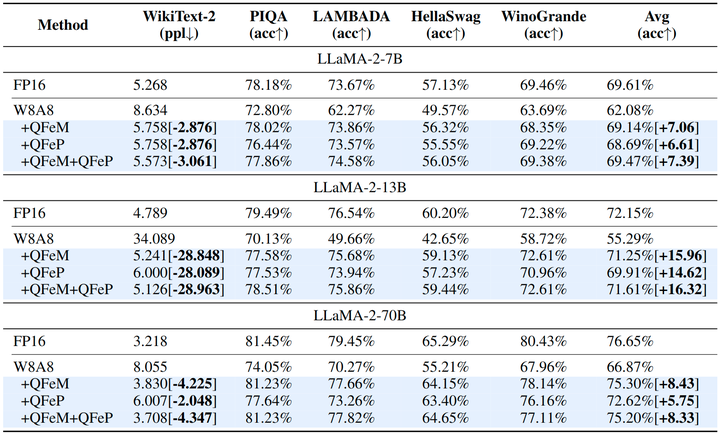
LLaMA-2 模型
作者在图 8 中报告了 LLaMA-2 模型量化的评估结果。与 FP16 精度相比,量化 weight 和 activation (W8A8) 会降低整体性能。结果表明,本文提出的方法解决了 Activation Spikes,使得 W8A8 的性能恢复到了接近 FP16。例如,LLaMA-2 7B 模型在 FP16 的性能下降不到 1%。值得注意的是,本文提出的 QFeM 和 QFeP 提升了性能。这表明 Activation Spikes 直接导致量化性能显着下降。由于所提出的方法是正交的,因此与单独应用 QFeM 和 QFeP 相比,结合 QFeM 和 QFeP 的性能略有提高。
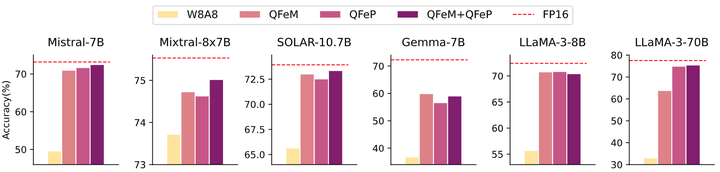
其他 GLU-implemented LLM
对于其他 GLU-implemented LLM,作者研究了本文方法在减轻量化瓶颈方面的有效性。如图 9 所示,本文方法始终可以纠正 Activation Spikes 引起的性能下降。值得注意的是,Mixral 模型展示了对性能下降的鲁棒性。这表明专家架构的混合,将 MLP 专家按令牌划分,有助于减轻激活峰值的影响。同时,与其他模型相比,解决 Activation Spikes 对于 Gemma 模型似乎并不能构成有效的补充。作者将此归因于 GLU 变体中激活函数的选择:Gemma 使用 GeGLU,而其他模型使用 SwiGLU。
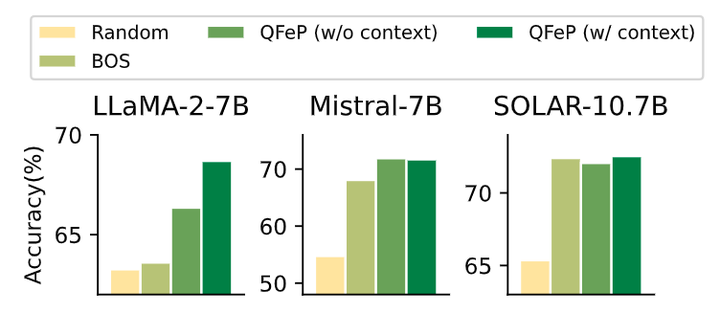
1.8 消融实验结果
对于 QFeP,作者为 KV cache 设计了一个长度为 3 的 Prefix,包括 BOS token、上下文 token 和 Activation Spikes 的额外 token。作者对 KV cache 的不同 Prefix 进行了消融实验。作者对比了不同的 Prefix 的 KV cache,包括:随机,BOS,没有 context token 的 QFeP,有 context token 的 QFeP,并在图 10 中说明了消融实验结果。在所有情况下,随机 Prefix 的性能都是最低的。而且,使用 BOS token 的 KV cache 性能不一致,本文的 QFeP 始终显示出显著的改进。
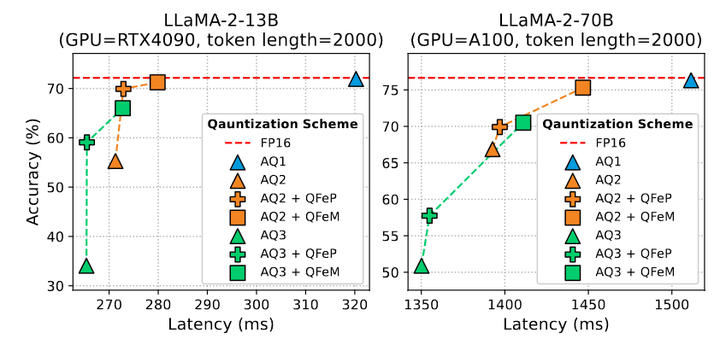
1.9 计算复杂度分析
本文提出的方法需要额外的资源来驱逐激活峰值。因此,作者分析了方法的计算成本,并将它们在各种方案中进行比较。作者评估了不同的激活量化方案:dynamic per-token, dynamic per-tensor, 和 static per-tensor 的量化,分别用 AQ1、AQ2 和 AQ3 表示。为了校准静态量化 scale,作者使用校准数据集估计绝对最大值。
推理时延
对于每个设置,作者展示了固定标记序列的 Zero-Shot 任务的精度和推理时延,如图 11 所示。虽然细粒度方案 AQ1 的精度下降可以忽略不计,但 AQ2, AQ3 的精度会下降会降低。
通过应用本文方法,粗粒度方案实现了具有竞争力的性能增益。例如,AQ2 和 QFeM 的组合展示了接近 AQ1 的性能,且时延更快。结果表明,解决量化的瓶颈对于粗粒度量化的推理加速,降低时延很重要。具体而言,最快的方案,即直接静态量化 (AQ3) 表现出显著性能下降。作者希望未来的工作可以解决静态量化的挑战。
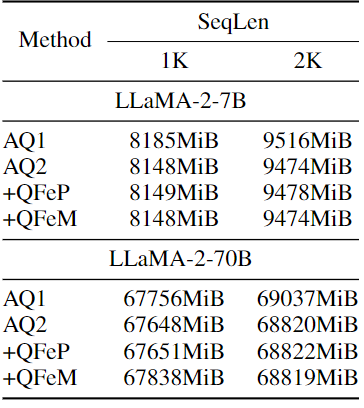
Memory Footprint
在图 12 中,作者记录了本文方法的最大显存占用。对于 QFeP,保留的 KV cache 会需要额外的显存。然而,这种显存开销远小于细粒度量化 AQ1 中使用的显存开销,因为 QFeM 仅将 3 个令牌用于缓存。与 QFeP 不同,QFeM 的内存利用率表现得不一致。例如,具有 QFeM 的 7B 模型的内存使用量类似于 AQ2,具有 QFeM 的 70B 模型在 1K 的序列长度上会产生额外的消耗。这是因为在 QFeM 中会对免量化的模块使用 W8A16 精度。为了定制化显存使用或者推理速度,QFeM 可以采用另一种策略,比如对于免量化模块使用细粒度的 activation 量化,而不是使用 W8A16。
参考
-
^abGlu variants improve transformer -
^RoFormer: Enhanced Transformer with Rotary Position Embedding -
^GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints -
^Mixtral of experts -
^abcdMassive Activations in Large Language Models -
^Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer -
^ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers
(文:极市干货)