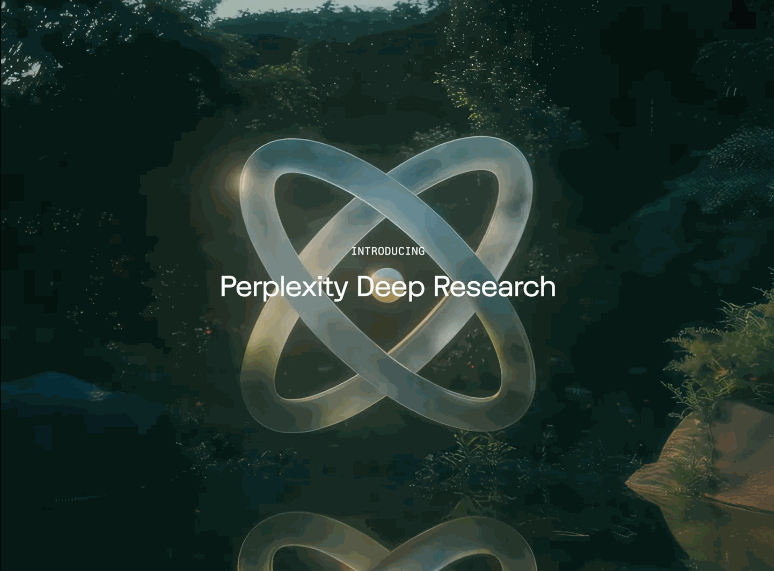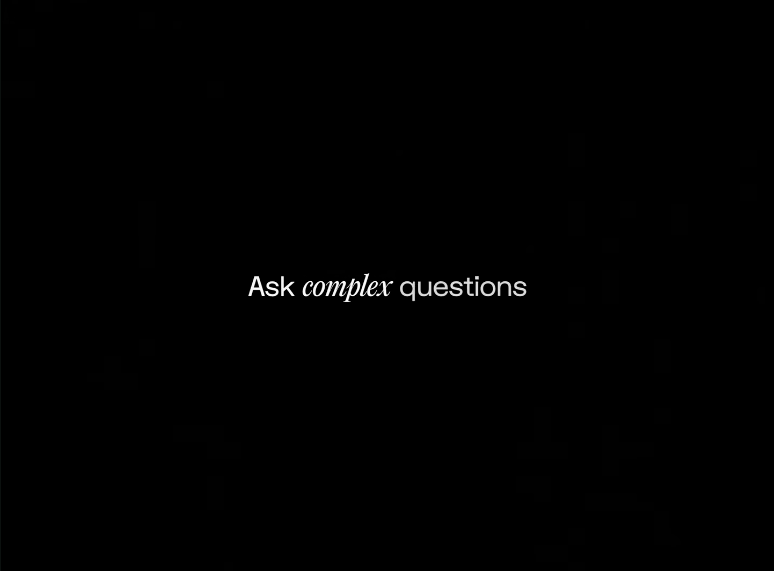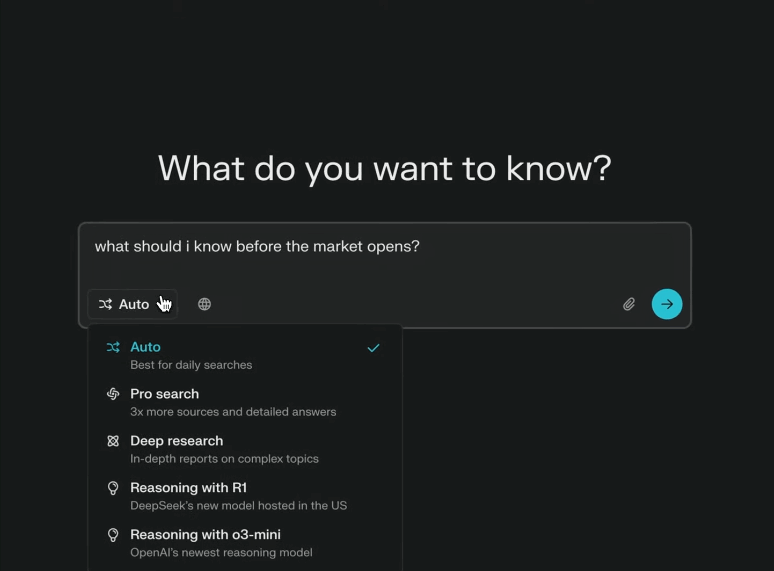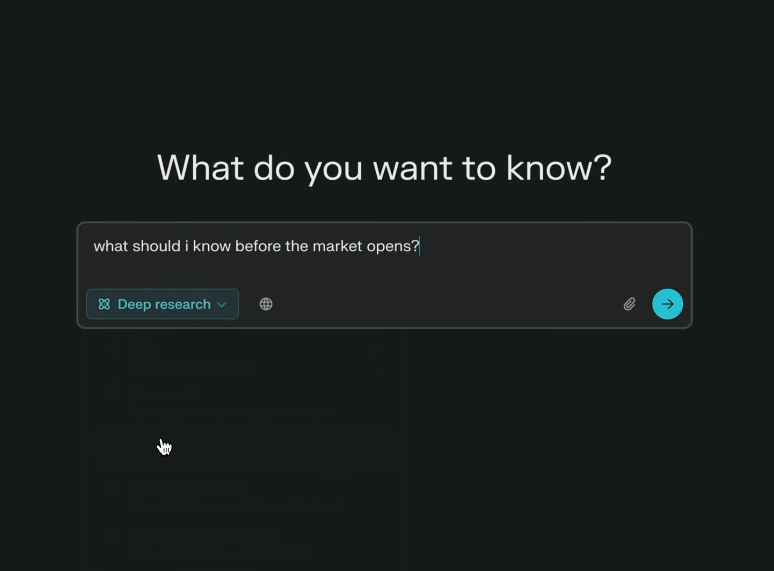跳至内容
接入 DeepSeek R1 之后,Perplexity 总算在本职业务上有所更新了,推出了「Deep Research」深度研究。要知道在此之前,它比较大的动作是接入购物功能……
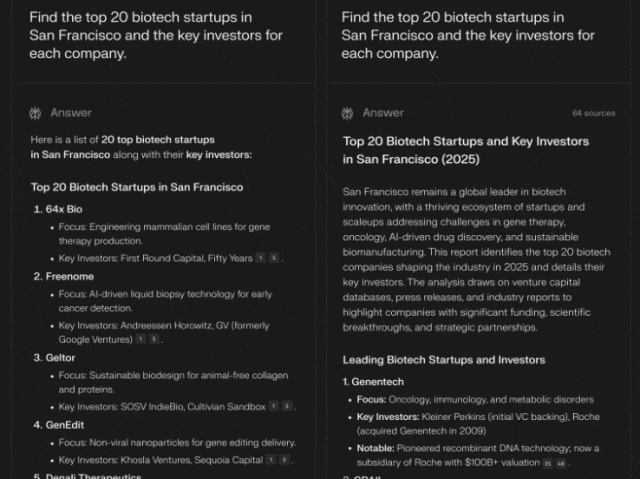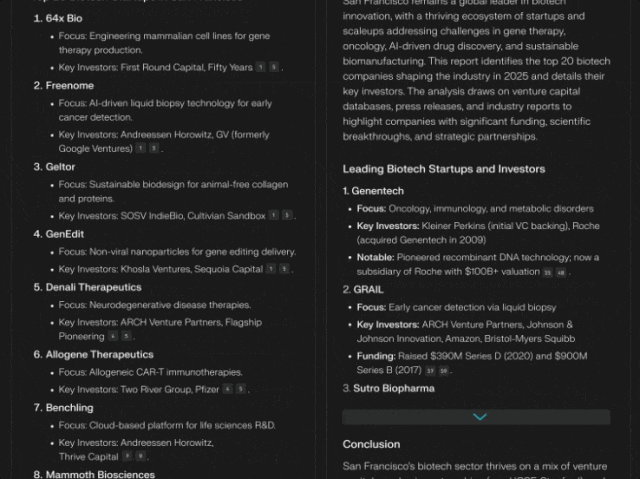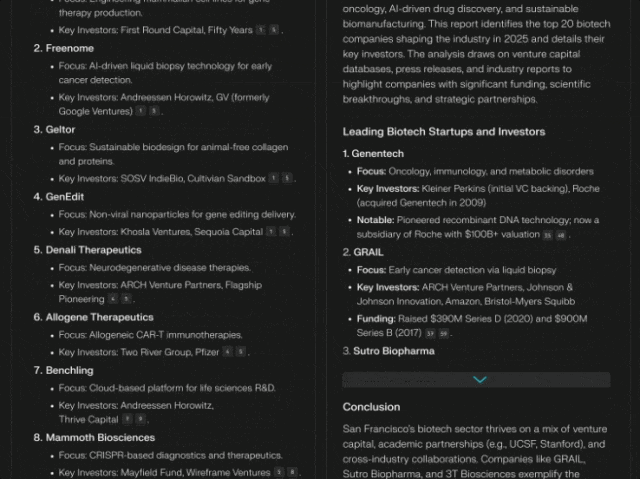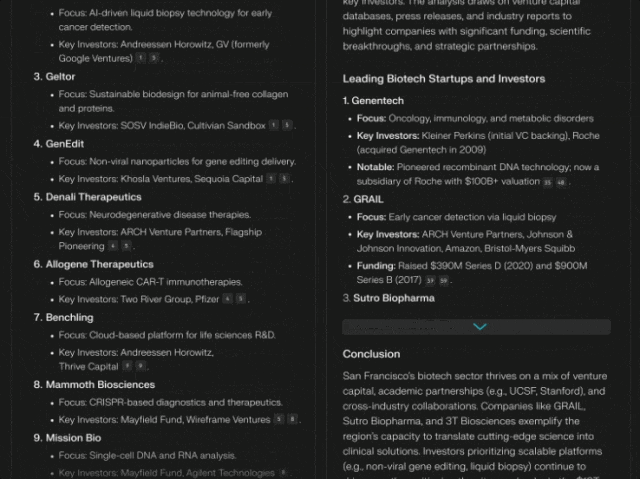
「深度研究」是对标 OpenAI 的 Deep Research 的模式,主打深度检索、专业输出。在 Humanity’s Last Exam 上获得了 21.1% 的准确率,远高于 Gemini Thinking、o3-mini、o1、DeepSeek-R1 和许多其他领先模型。这个测试包含 3,000 多个问题,涵盖 100 多个学科,从数学和科学到历史和文学,被视为人工智能系统的综合基准。
新功能已经全量推送,注意:免费用户每天只有五次试用。
指路👉🏻:https://www.perplexity.ai/
既然说是「深度研究」,那么为了区别于以往的常规模式测试,我们在问题设计上有所调整,直接上难度,重点检验一下它是不是真的到了能出报告的地步。
这意味着问题艰深、资料保有量大、需要在输出时体现报告逻辑——所有的提问都要满足这样的要求。
【引用权威性】:2023 年诺贝尔经济学奖得主的主要理论贡献是什么?
这里主要考察 Deep Research 的信息准确性、引用权威性。给定的范围很明确了:2023 年、诺贝尔经济学奖,对象基本是唯一的。
这一年的经济学诺奖得主是克劳迪娅·戈尔丁,她的研究横跨了美国 200 年间的数据,性别差异如何影响收入和就业率。
这是几个世纪以来,女性收入和劳动力市场参与情况的首次全面概述,推进了对导致性别薪酬差距的因素以及女性在劳动力市场中的角色的理解,这对社会具有重要意义。
原本我很期待 Deep Research 能进一步展开讲讲:这个话题的资料保有量很大,足以制作一份详尽的报告书。但实际上它就是这么短短几段,导出来的效果也不好。
对比了 DeepSeek R1(元宝版),虽然也总结了三点,但每一个点的阐释都比 Perplexity 更完整。
【资料实时性】:对比美联储最近三次议息会议声明的措辞变化
这里主要考察抓取的资料时效性是否够新。可以看到 Deep Research 给出的整理还是非常细致的。
题目解析的准确度是可以的,第二部分就给出了联邦公开市场委员会声明里,各种措辞上的变化。
【音视频理解能力】:解析 NASA 最新发布的黑洞合并模拟视频中的物理原理
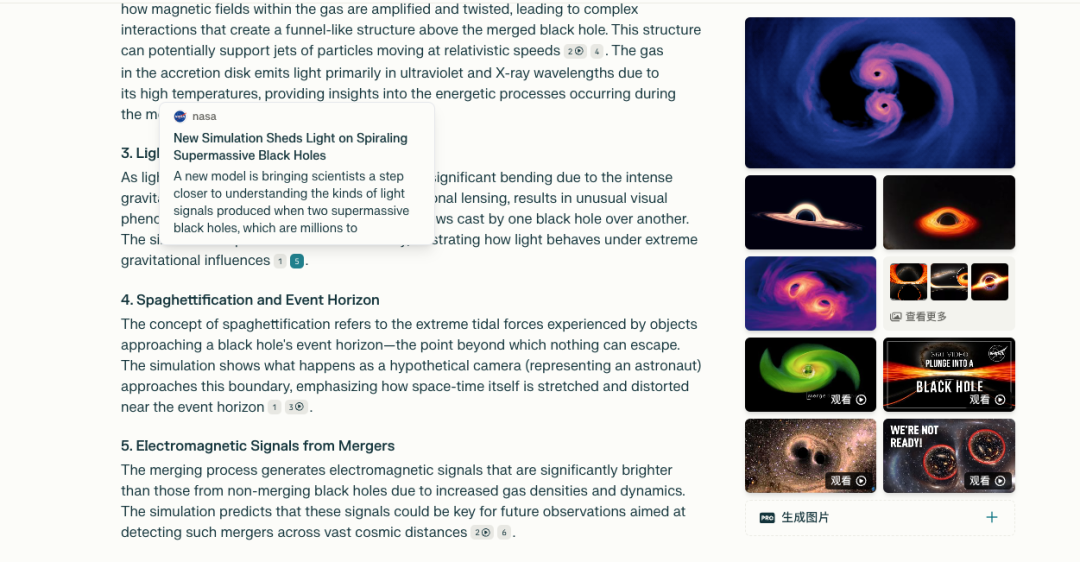
这是 NASA 发布的一个制作很美,但注解很少的视频。不到两分钟的视频,通过动态影像展示了黑洞合并,但几乎没有任何文字。
这里考察的就是 Deep Research 对音视频模态材料的理解能力,解答针对性地解释了视频中的图像呈现,比如「该模拟将引力波以彩色场的形式可视化」「合并的黑洞上方形成类似漏斗的结构」,看来是有一定读图能力的。
对比了一下,虽然调取了视频,但具体解答中,应该还是参考了 NASA 给出的视频介绍。可以理解吧,毕竟是这么专业的内容。
不过在时效性方面,有点掺在了一起。右侧给出的视频既有去年的,也有 8 年前的,属实不能算「最新」。这点应该要能更清晰的标注出来。
内容准确性、时效性这些都是基础要求,任何一个 AI 搜索都应该具备。更进阶的,是能不能整合资料,哪怕提问是模糊的,输出时依然完整、清晰。
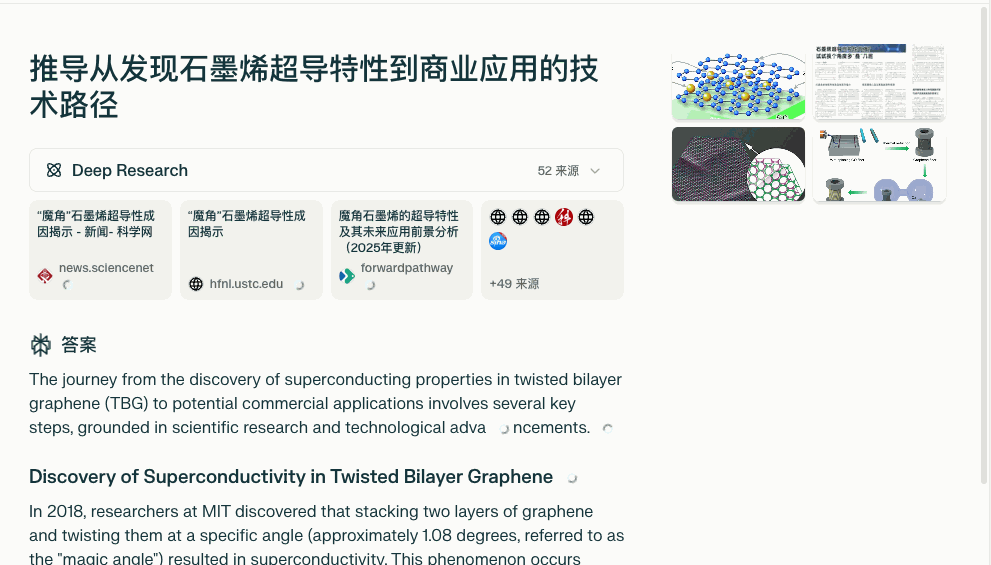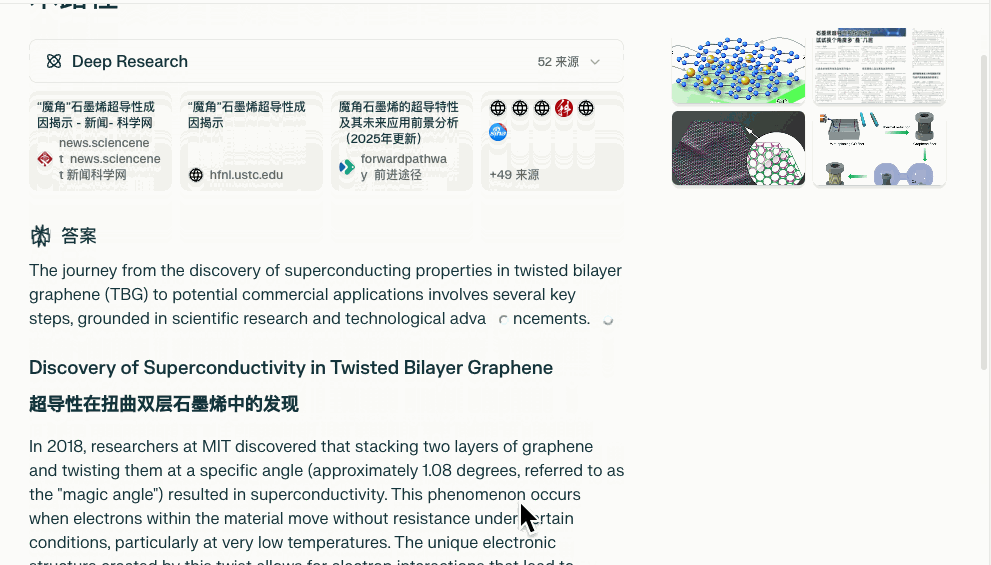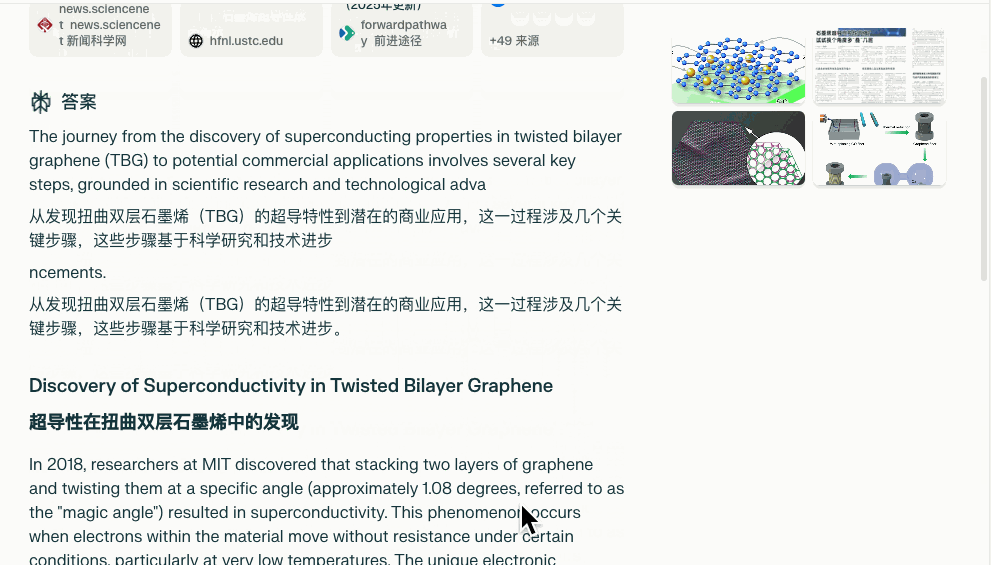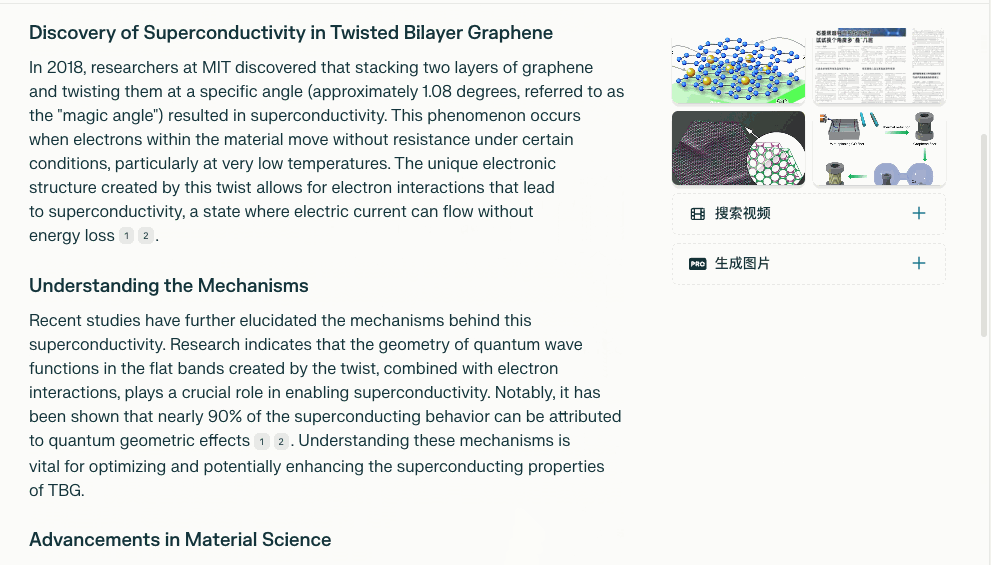
【逻辑完整性】:推导从发现石墨烯超导特性到商业应用的技术路径
这里考察的是逻辑链条,是否清晰有道理、是否逻辑完整。重点在「从发现」到「商业应用」,两边都应该有所涉及。
Deep Research 通过在这两个题眼中间,扩展了「理解机制」和「材料学进展」,把回答串起来。
先是介绍了在 2018 年时,麻省理工科研人员发现的石墨烯超导现象。然后解释了为什么这种超导性有价值、它的简单原理是什么。基于这种原理,科研人员探索了有什么样的使用价值,最后就是更商业的应用。
虽然每一个部分都不长,但是不仅理解了问题,基于提问建设了一个解答逻辑,而且是完满、顺畅的。
【模糊问题处理】:如何评估发展中国家建设数据中心的速度?
这个问题考察对于模糊需求的理解。「发展中国家」是个范围很大的主语。而且,数据中心建设的资料未必齐全,不好查询。
这个任务中,能看到 Deep Research 在信息来源的权重上有所挑选,把来自信通院、商务部的研究报告放在了前面。
这样一来,内容的权威性是有所保证,但是给出的解答有点流于表面。整个解答看着跟普通模式区别不是很大
从内容上来讲,不论是准确性、时效性、权重配比,都没有大问题,「research」的工作还是完成了的。
但是够不够「深度」,就见仁见智了。平心而论,这几个问题下来,没有哪次的输出是真的撑得起一份报告的,起码没有到它官方宣传的那样(下图右)。
即便有导出 pdf 的功能,也更像是走个过场,交互上还不如秘塔。
「调研」是一个需要兼顾形式和内容的场景。正如前面讲到的,内容的准确性、权威性,已经是 AI 搜索的基本操作。想要立住「报告」这个形式,不仅是对资料保有量提出要求,更加是对「怎么组织资料」有要求。
同样的材料,可以压缩到中学生作文般的 800 字,也可以拉伸成 8000 字的开题报告。这中间的差异,正是对资料的组织。
Perplexity 对这个方向有所想象了,但同一时间,所有的对家都有所想象了。前有 OpenAI,后有 Grok 3,连名字都是大差不差的 Deep (Re)search。这的确是一个大有可为的场景,但很显然,也是一个竞争非常激烈的场景。

我们正在招募伙伴
✉️ 邮件标题
「姓名+岗位名称」(请随简历附上项目/作品或相关链接)

(文:APPSO)