微软上线Deep Research:OpenAI同款智能体,o3+必应双王炸

专注AIGC领域的专业社区关注微软&OpenAI等大语言模型的发展和应用落地。今天凌晨,微软在官网宣布Azure AI Foundry中上线Deep Research公开预览版。这是支持API和SDK的OpenAI高级智能体研究能力产品,能够自动化完成复杂的研究任务。
专注AIGC领域的专业社区关注微软&OpenAI等大语言模型的发展和应用落地。今天凌晨,微软在官网宣布Azure AI Foundry中上线Deep Research公开预览版。这是支持API和SDK的OpenAI高级智能体研究能力产品,能够自动化完成复杂的研究任务。

OpenAI 连续发布多项新功能,包括面向 ChatGPT Team 用户开放高算力模型 o3-pro、o3 模型使用额度翻倍至 200 次/周以及 ChatGPT Projects 功能升级等。

OpenAI发布ChatGPT新功能支持MCP协议,新增会议记录模式。通过自动录音和转录功能,实时生成结构化的会议记录,帮助用户高效提取关键信息。
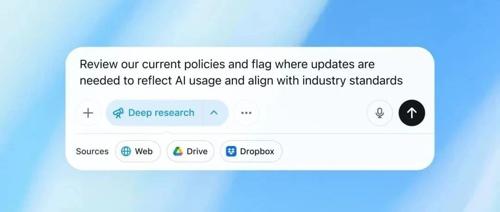
OpenAI发布了对ChatGPT的重大更新,包括向macOS用户推出会议记录模式以及支持MCP协议,增强了跨平台数据整合、搜索和推理功能。

文章介绍了昆仑万维公司的’天工超级智能体’这款AI办公神器。它具有强大的技术能力,包括深度研究技术,能生成高质量的文档、PPT和表格等内容,并在多项AI能力评测中表现出色。天工超级智能体能够帮助用户提高工作效率,如快速生成专业级别的报告、PPT等。
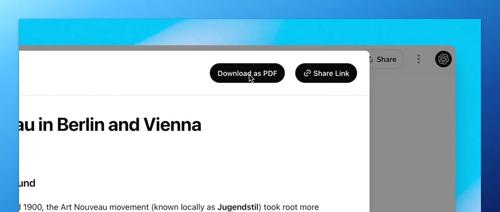
今天,ChatGPT更新了两个功能:一是基于GitHub的深度研究,用户可以选择自己的代码仓库进行调研;二是导出Deep Research报告为PDF。这两个功能增强了开发者在软件开发周期中的实用性和便利性。

闪电般生成深度研究报告Deep Research利用AI模型快速提供多领域的高质量分析,支持联网搜索和多种大语言模型。支持编辑研究报告,自定义模型列表,隐私优先存储数据于本地。