
这张图清晰地描绘了一个现代化的、复杂的问题解答(Question Answering, QA)或检索增强生成(Retrieval-Augmented Generation, RAG)系统的架构蓝图。它从用户提出问题开始,一直到最终生成答案,详细展示了中间的各个关键环节和技术选择。我们可以将整个流程分解为以下几个核心阶段:
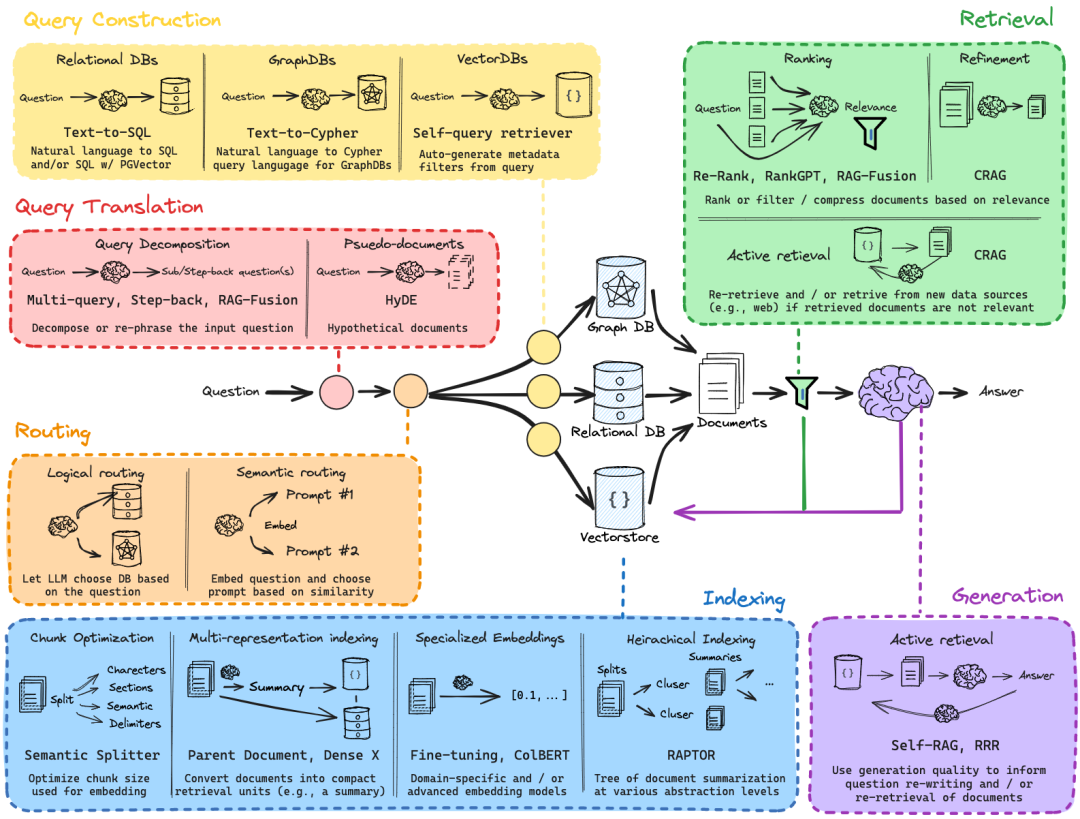
1、查询构建 (Query Construction)
这是用户与系统交互的第一步,也是系统理解用户意图的起点。图像中展示了针对不同类型数据库的查询构建方式:
a. 关系型数据库 (Relational DBs): 对于关系型数据库,常见的查询构建方式是 Text-to-SQL。这意味着系统需要将用户的自然语言问题转化为结构化的SQL查询语句。这通常涉及到自然语言理解 (NLU) 技术,以及将自然语言语义映射到SQL语法和数据库Schema的能力。图中还提到了 SQL w/ PGVector,可以结合向量数据库 (PGVector是PostgreSQL的向量扩展) 来增强SQL查询的能力,例如进行语义相似度搜索,从而更灵活地处理用户的模糊或语义化的查询。
b. 图数据库 (Graph DBs): 对于图数据库,对应的查询构建方式是 Text-to-Cypher。Cypher是一种用于图数据库Neo4j的查询语言,类似于SQL但更适合图结构的查询。Text-to-Cypher 需要将自然语言问题转化为Cypher查询语句,这需要理解图数据库的结构和图查询语言的特性。
c. 向量数据库 (Vector DBs): 对于向量数据库,图中展示了 Self-query retriever。这意味着系统可以根据用户的问题,自动生成元数据过滤器,并直接查询向量数据库。向量数据库通常存储文本或数据的向量表示,通过相似度搜索进行检索。Self-query retriever 的关键在于能够从自然语言问题中提取出用于过滤的结构化信息,并结合向量相似度搜索,实现更精确的检索。
总结查询构建阶段:这个阶段的核心目标是将用户用自然语言提出的问题转化为系统可以理解和执行的查询语句,针对不同类型的数据存储(关系型、图、向量),采用了不同的查询语言和技术。体现了系统对多模态数据和查询方式的支持。
2、查询翻译 (Query Translation)
在查询构建之后,有时需要对用户的原始查询进行进一步的加工和优化,以便更有效地检索和理解用户的意图。图中展示了两种主要的查询翻译策略:
a. 查询分解 (Query Decomposition): 对于复杂的问题,可以将其分解为更小的、更易于处理的子问题 (Sub/Step-back question(s))。 这可以使用 Multi-query, Step-back, RAG-Fusion 等技术。 – Multi-query 可能指生成多个不同的查询,从不同角度探索问题。 – Step-back 可能指先回答一些更基础的、前提性的问题,然后再逐步解决最终的复杂问题。 – RAG-Fusion 可能是指将检索增强生成与查询融合技术结合,通过多次检索和融合,更全面地理解用户意图。 – 核心思想是 Decompose or re-phrase the input question,即分解或重述输入问题,降低复杂问题的处理难度。
b. 伪文档生成 (Pseudo-documents): HyDE (Hypothetical Document Embeddings) 是一个典型的伪文档生成方法。其思想是,先让模型根据问题生成一个“假设的文档”(伪文档),这个伪文档并不需要真实存在,但它应该包含模型对问题答案的初步理解和预测。然后,将伪文档和真实文档一起进行向量表示,并进行相似度检索。HyDE 旨在通过引入模型的先验知识,帮助向量检索器更好地找到相关的真实文档。
总结查询翻译阶段:这个阶段旨在优化用户查询,使其更适合后续的检索过程。通过查询分解可以处理复杂问题,通过伪文档生成可以提升向量检索的准确性,体现了系统在理解和处理用户意图上的灵活性和智能化。
3、路由 (Routing)
当系统接收到翻译后的查询后,需要决定将查询路由到哪个或哪些数据源进行检索。图中展示了两种路由策略:
a. 逻辑路由 (Logical routing): Let LLM choose DB based on the question。这意味着使用大型语言模型 (LLM) 来根据问题的内容和特点,判断应该查询哪个数据库。例如,如果问题涉及到知识图谱相关的实体和关系,则路由到图数据库;如果问题涉及到结构化数据查询,则路由到关系型数据库;如果问题更偏向于语义搜索,则路由到向量数据库。
b. 语义路由 (Semantic routing): Embed question and choose prompt based on similarity。这种方式首先将问题进行向量嵌入 (Embed),然后基于问题向量的相似度,选择不同的Prompt (Prompt #1, Prompt #2)。 这意味着针对不同类型的问题或意图,系统预设了不同的Prompt策略,通过语义相似度来自动选择最合适的Prompt,以引导后续的检索或生成过程。
总结路由阶段:路由阶段是系统智能决策的关键步骤,它根据问题的内容和特点,选择最合适的数据源和处理策略,体现了系统在资源管理和任务调度上的智能化。
4、索引 (Indexing)
为了高效地进行检索,数据需要预先进行索引。图像的蓝色区域展示了多种索引优化的策略:
a. Chunk Optimization (分块优化): 在处理长文档时,通常需要将文档分割成块 (Chunk),然后对块进行索引。Chunk Optimization 关注如何更有效地进行分块。
– Split by Characters, Sections, Semantic Delimiters: 不同的分块策略,例如按字符数、章节、或语义分隔符进行分割。
– Semantic Splitter: 强调语义分块的重要性,优化用于embedding的chunk size,使得每个chunk在语义上更加完整和独立,从而提高embedding的质量和检索效果。
b. Multi-representation indexing (多重表示索引): Summary -> {} -> Relational DB / Vectorstore。这表示可以为文档创建多种表示形式进行索引,例如,除了文档的原始文本块外,还可以生成文档的摘要 (Summary),并将摘要也进行索引。这样可以使用不同的表示形式来满足不同的查询需求。图中暗示摘要可以存储在关系型数据库或向量数据库中。
– Parent Document, Dense X: 可能指将文档及其父文档信息一起索引,以及使用Dense Representation (Dense X) 来表示文档,Dense X 可能指稠密向量表示。
– Convert documents into compact retrieval units (e.g., a summary): 强调将文档转化为更紧凑的检索单元,例如摘要,以提高检索效率。
c. Specialized Embeddings (专用Embedding): Fine-tuning, CoLBERT, [0, 1, … ] -> Vectorstore。这指的是可以使用专门训练的或微调过的Embedding模型,例如 CoLBERT,来生成文档的向量表示,并将这些向量存储在向量数据库中。
– Domain-specific and / or advanced embedding models: 强调可以使用领域特定的或更先进的Embedding模型,以获得更精准的语义表示,提升检索效果。
d. Heirarchical Indexing Summaries (分层索引摘要): Splits -> cluser -> cluser -> … -> RAPTOR -> Graph DB。 RAPTOR (可能是指一种分层文档摘要和索引方法) 通过多层聚类 (cluser) 的方式,构建文档摘要的层次结构。
– Tree of document summarization at various abstraction levels: 强调 RAPTOR 构建的是一个多层抽象级别的文档摘要树。
– 存储在图数据库 (Graph DB) 中,利用图数据库来存储和管理这种分层索引结构,方便进行多层次的检索和导航。
总结索引阶段:索引阶段关注如何高效、有效地组织和表示数据,以便进行快速和准确的检索。从分块优化、多重表示、专用Embedding到分层索引摘要,体现了在索引策略上的多样性和先进性。
5、检索 (Retrieval)
基于路由选择的数据源和索引,系统进行实际的检索过程。图像的绿色区域展示了检索的两个主要方面:
a. 排序 (Ranking): Question -> {} -> Relevance -> Filter。检索到的文档需要根据其与查询的相关性进行排序 (Ranking)。
– Re-Rank, RankGPT, RAG-Fusion: 提及了一些高级的排序技术,例如 Re-Rank (重排序,在初始检索结果基础上进行更精细的排序)、RankGPT (用GPT等大型模型进行排序)、RAG-Fusion (将排序与检索增强生成融合)。
– Rank or filter / compress documents based on relevance: 排序的目的可以是直接排序返回最相关的文档,也可以是基于相关性进行过滤 (Filter) 或压缩 (compress) 文档,以便后续处理。 – CRAG (上下文相关的检索增强生成方法,Context-Relevant Answer Generation) 在排序环节也出现,排序过程也需要考虑上下文信息。
b. 主动检索 (Active retrieval): {} -> CRAG -> Answer。Re-retrieve and / or retrieve from new data sources (e.g., web) if retrieved documents are not relevant. 主动检索指的是,如果初始检索结果不理想,系统可以主动进行重新检索 (Re-retrieve) 或者从新的数据源 (例如 Web) 进行检索。
– CRAG 在主动检索中也出现,进一步强调了上下文相关性和迭代检索的重要性。
– Self-RAG, RRR (Retrieval-Rewrite-Read) 等技术可能也与主动检索相关,旨在通过迭代的检索和生成过程,不断优化检索结果和答案质量。
总结检索阶段:检索阶段的核心目标是找到与用户查询最相关的文档或信息。从排序到主动检索,体现了系统在检索策略上的精细化和智能化,力求提供高质量的检索结果。
6、生成 (Generation)
最终,系统需要根据检索到的文档生成答案,并呈现给用户。图像的紫色区域展示了生成阶段的核心技术:
a. 主动检索 (Active retrieval) (再次出现): {} -> Answer -> Self-RAG, RRR -> Question re-writing and / or re-retrieval of documents。主动检索在生成阶段也扮演重要角色。
– Self-RAG (Self-Retrieval Augmented Generation) 是一种自检索增强生成方法,它允许生成模型在生成答案的过程中,根据需要主动进行检索,并根据检索结果调整生成策略。 – RRR (Retrieval-Rewrite-Read) 是一种迭代的生成流程,可能包括检索 (Retrieval)、重写问题 (Rewrite) 和阅读文档 (Read) 等步骤,通过多次迭代优化答案质量。
– Use generation quality to inform question re-writing and / or re-retrieval of documents: 强调可以利用生成答案的质量来指导问题重写和文档重检索,形成一个闭环的优化过程。
总结生成阶段:生成阶段是最终输出答案的关键步骤。主动检索和自检索增强生成技术 (Self-RAG, RRR) 使得生成过程更加智能化和可控,能够生成更准确、更符合用户需求答案。
整体总结: 这张图清晰地展示了一个现代RAG系统的复杂性和精细程度。它涵盖了从查询理解、数据路由、索引优化、高效检索到最终答案生成的完整流程,并展示了在每个环节可以采用的多种先进技术和策略。
关键亮点和趋势:
-
多数据库支持: 系统支持关系型数据库、图数据库和向量数据库,能够处理不同类型的数据和查询需求。 -
查询优化和翻译: 通过查询分解和伪文档生成等技术,提升系统对复杂和语义化查询的处理能力。 -
智能路由: 利用LLM和语义相似度进行路由决策,实现数据源的智能选择和任务调度。 -
索引优化多样性: 从分块、多重表示、专用Embedding到分层索引摘要,体现了索引策略的多样性和深度优化。 -
检索的精细化和主动性: 从排序算法到主动检索,系统力求提供高质量、相关的检索结果。 -
生成与检索的深度融合: Self-RAG, RRR 等技术表明,生成阶段不再是简单的信息拼接,而是与检索过程深度融合,形成迭代优化的闭环。
这张图代表了当前RAG系统发展的一个重要趋势,即更加注重系统的智能化、模块化和可扩展性。未来的RAG系统将不仅仅是简单的“检索+生成”,而是会朝着更加智能化的方向发展,能够更好地理解用户意图,更有效地利用多模态数据,更精准地进行检索和生成,并最终提供更优质、更个性化的用户体验。这张图为我们理解和构建下一代RAG系统提供了非常有价值的参考框架。
参考文献:
[1] GitHub:https://github.com/bRAGAI/bRAG-langchain/
[2] https://bragai.dev/
(文:NLP工程化)