
今天是2025年02月25日,星期二,北京,天气晴。
昨天是真热闹,Deepseek FlashMLA、QwQ-Max-Preview、claude 3.7,该来的,都会来的,我们这里先做下介绍。
这里比较有趣的是,根据其介绍,通过API使用Claude 3.7时,用户可以控制模型的”思考预算”,可以指定Claude最多思考N个token(N的上限为128K),这一点是有启发的,之前说过R1的think太长了,如何进行控制,是一个方向,比如之前说工作 S1《s1: Simple test-time scaling》(https://arxiv.org/pdf/2501.19393,https://github.com/simplescaling/s1),提到多种预算控制方案。

一种是条件长度控制方案,依赖于在提示中告诉模型它应该生成多长时间。根据粒度分组为 (a)token-条件控制:在提示中指定思考token的上限;(b)步骤条件控制:指定思考步骤的上限,其中每个步骤大约为100个tokens;(c)类-条件控制:编写两个通用提示,告诉模型思考一小段时间或很长一段时间。一种是拒绝采样,即采样直到一代符合预定的计算预算。这回过头来,是不是s1工作的最佳意义?
第二个,我们来看看再看几个值得思考的问题,关于差异化,关及大模型逻辑推理技术总结。
专题化,体系化,会有更多深度思考。大家一起加油。
一、推理大模型集中发布跟踪
我们先来看近日推理大模型相关前沿回顾,Deepseek FlashMLA、QwQ-Max-Preview、claude 3.7,
1、产业进展,Claude 3.7 Sonnet发布
新增“深度思考模式”,思考过程可视化,https://www.anthropic.com/research/visible-extended-thinking

这里再次验证了test compute time scaling-law:
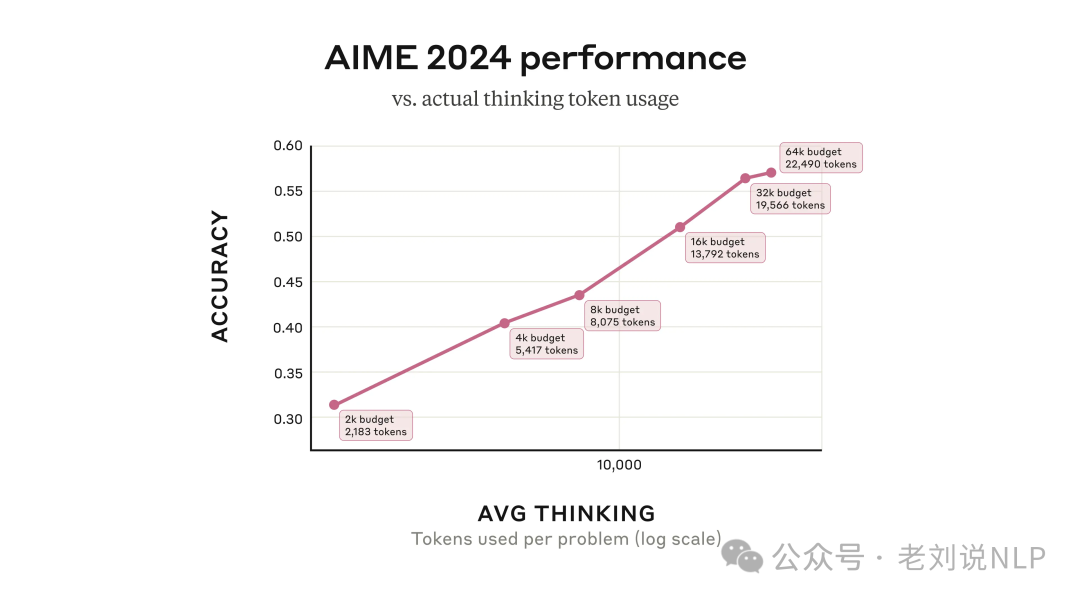
这里有个误区,什么叫混合推理?这个着实令人摸不着头脑。
2、推理模型进展,QwQ-Max-Preview发布
也就是Qwen的QwQ模型,通过http://qwen.ai即可访问,后续会以 Apache 2.0协议,开源Qwen2.5-Max、QwQ-Max 及其小模型,如QwQ-32B模型等。
https://pics1.baidu.com/feed/d6ca7bcb0a46f21f55afba81e3b4186f0e33aeed.jpeg@f_auto?token=94068c1e08e8adbf77e79631cfefaf18
地址在:https://github.com/qwq-max-preview
3、deepseek开源FlashMLA
FlashMLA是适用于HopperGPU的高效MLA解码内核,针对可变长度序列服务进行了优化。目前发布BF16、块大小为64的分页kvcache,使用CUDA12.6,在H800SXM5上,在内存绑定配置下实现高达3000GB/s,在计算绑定配置下实现580TFLOPS。
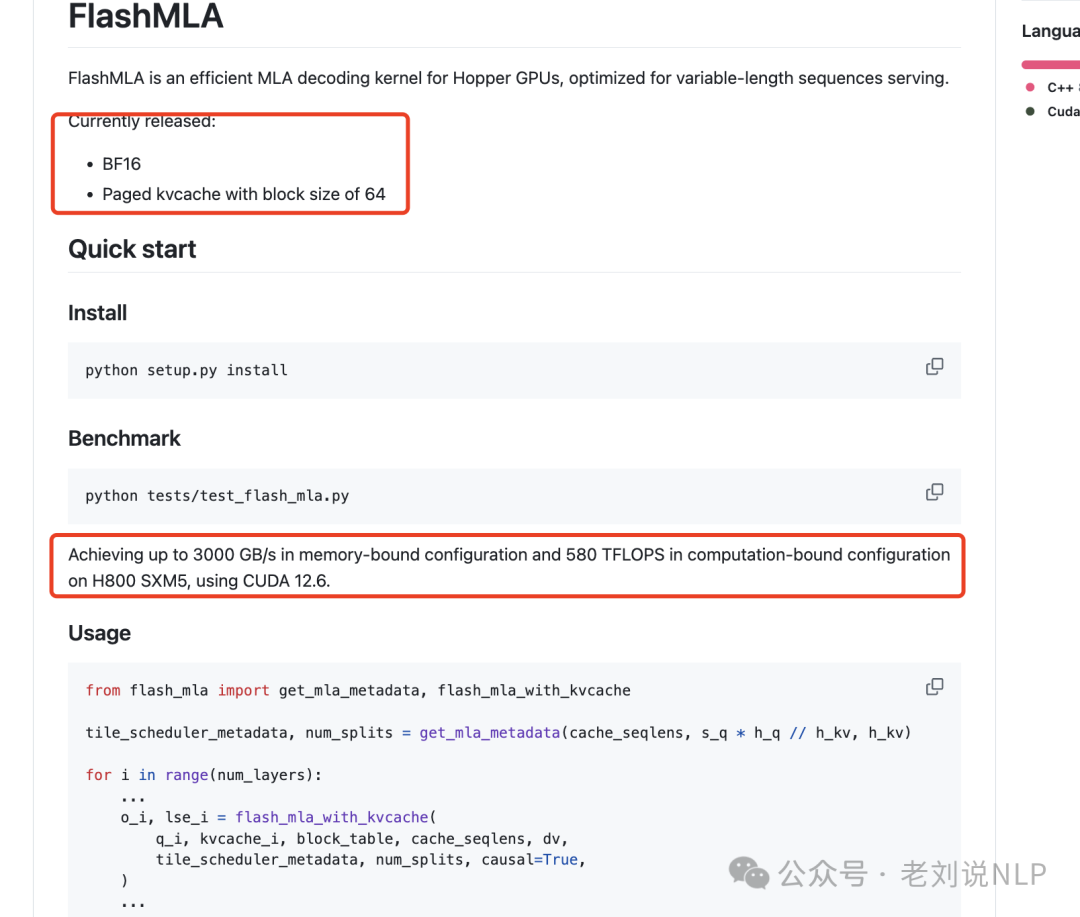
地址在:https://github.com/deepseek-ai/FlashMLA
4、多模态开源进展,谷歌开源的全新视觉模型:PaliGemma 2 Mix
支持图像描述、目标检测、图像分割、OCR以及文档理解等任务,提供三种不同参数规模(3B、10B、28B),支持224px和448px两种分辨率。
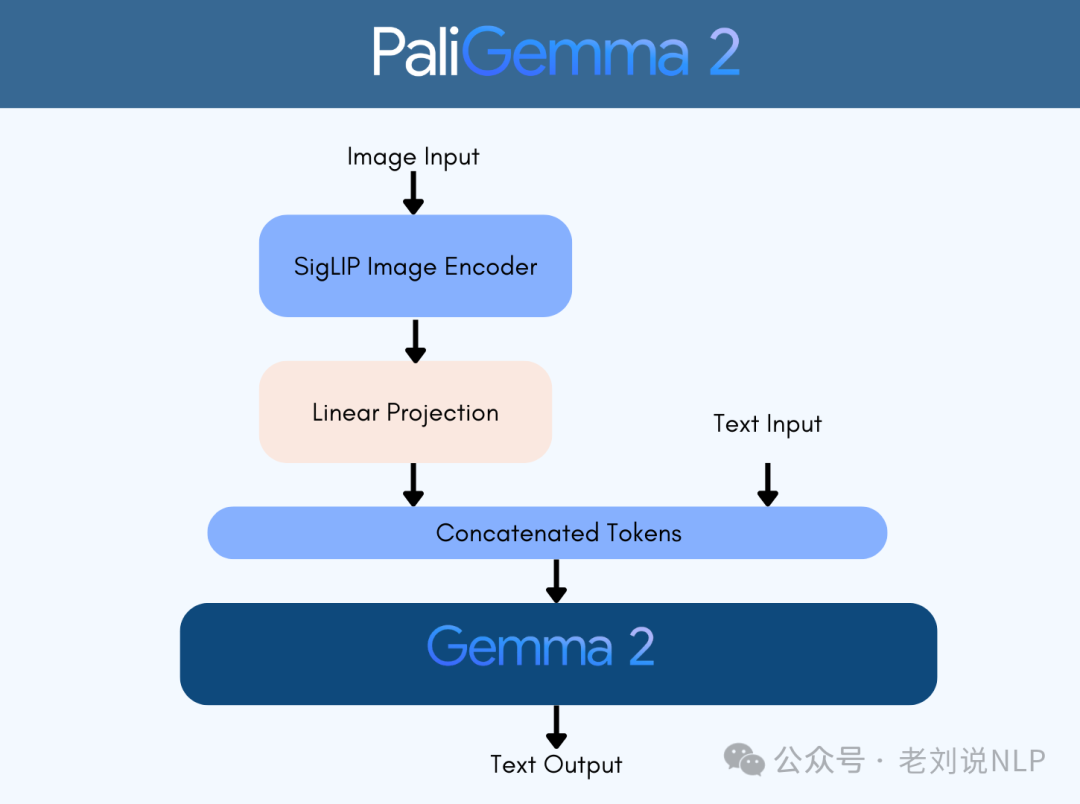
地址在:https://github.com/huggingface/blog/blob/main/paligemma2mix.md
二、再看大模型逻辑推理技术总结及几个值得思考的问题
1、关于大模型逻辑推理的一个总结性工作
大模型在逻辑推理能力方面仍面临重大挑战,特别是在逻辑问题回答和逻辑一致性方面,所以最近的工作《Empowering LLMs with Logical Reasoning: A Comprehensive Survey》,https://arxiv.org/pdf/2502.15652,是值得一看的。
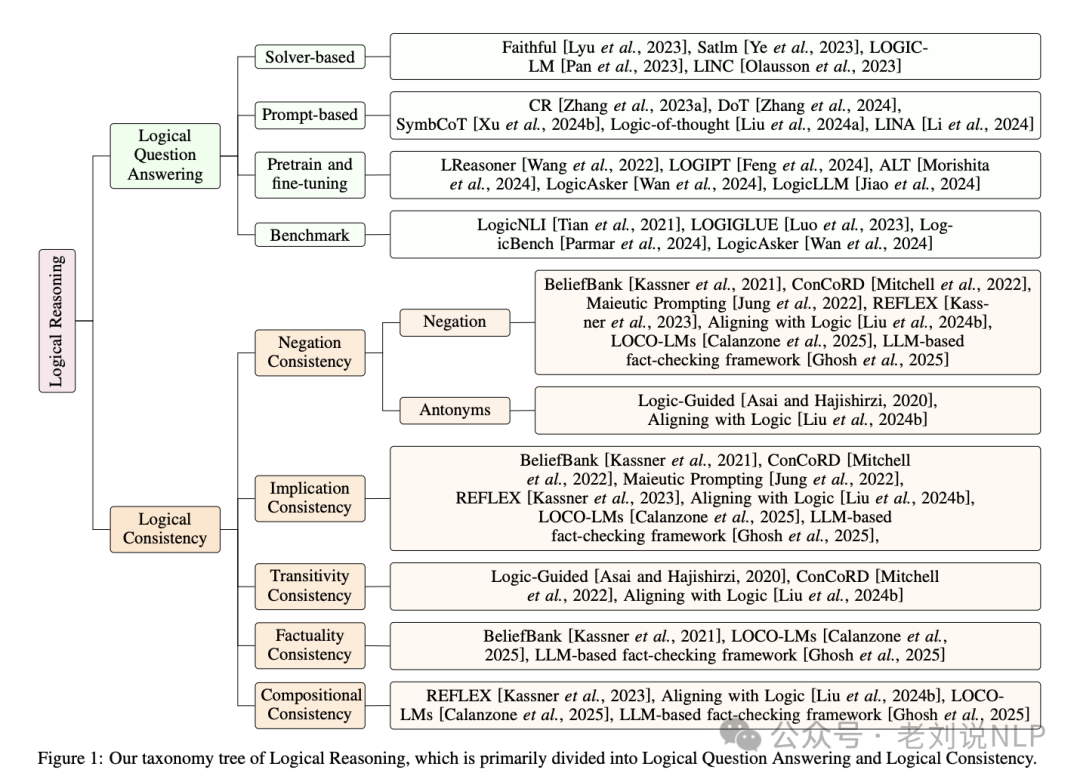
核心看两个点。
一个是基于推理大模型实现逻辑问题回答的方案。方法有如下几个:
求解器辅助方法,通过将自然语言问题转换为符号语言表达式,然后使用外部求解器进行解决。这种方法存在信息丢失和翻译错误的问题。
提示方法,通过提示技术直接刺激LLMs的逻辑推理能力。提示方法可以分为显式建模逻辑链和通过定义好的提示进行翻译和推理。
预训练与微调方法,通过在预训练过程中引入逻辑推理样本来增强LLMs的逻辑推理能力。这种方法需要额外的数据和计算资源。
一个是对于逻辑一致性上可以进一步分为哪几个不同部分。
否定一致性,确保LLMs在回答问题时不会自相矛盾。通过添加记忆层和使用MaxSAT求解器来解决。
蕴含一致性确保LLMs在给定前提的情况下不会输出违反逻辑规则的结果。通过生成多个候选答案并使用MAX-SAT求解器来避免不一致。
传递性一致性,确保LLMs在多个命题之间保持逻辑关系的一致性。通过增强训练数据和采用一致性正则化来实现。
事实一致性,确保LLMs生成的响应与现实世界的知识一致。通过构建基于知识图谱的基准数据集来评估和改进。
组合一致性,确保在结合多个事实和逻辑约束时保持整体逻辑一致性。通过神经符号集成来实现。
2、几个思考
一个是关于目前的差异化成长问题。LLM只会越来越强,卡会越来越普及,上桌门槛越来越低,产品设计跟解决方案会越来越同质化。关于一点思考跟建议,送给可能正在徘徊工作选择的大家。现在AI入门门槛很低,,同质化很重,所以,我们都在找差异化。守住差异化,我们的不可替代性,这才是你要考虑的,如果都去做ai,我们的抗风险能力是什么。我们的优势是什么?不是什么火做什么,而是我们的优势在那儿去做什么。跟风,跟到一无所有,见过太多这种例子了。把我们现在的基本盘守住,垂直提升,然后呢,在此基础上,去跟进前沿,这样进可攻,退可守。
一个是继续看RAG相关的误区,很多应用场景是需要结合私有数据来分析的,而这块市场上都一窝蜂的选择去跟风openai的deep research,为啥不花时间和精力把rag结合搜索引擎一起来做research with rag呢?这种论断是个悖论,现在RAG的大范式一直在,大家认为Deep research就不是RAG,就是个误区。
总结
本文主要介绍了推理大模型相关发布前沿回顾、大模型逻辑推理技术总结及几个值得思考的问题,现在开源相关的工作越来越多,进入了另一个白热化。大家可以多关注。但没必要一一去学,要给自己减负。
参考文献
1、https://arxiv.org/pdf/2501.19393
2、https://arxiv.org/pdf/2502.15652
(文:老刘说NLP)