
“ 神经网络模型的主要难点就在于模型本身,而至于模型的效果还与其训练数据和过程有关。”
在学习神经网络技术的过程中,会有多种不同的神经网络架构;如常见的RNN,CNN等;因此,我们很多人都会被这些乱七八糟的神经网络架构给迷惑住,即想学习神经网络又不知道应该怎么入手;面对各种各样的网络模型,也不知道应该去学习哪种。
但是,我们从问题的最本质出发,不同的神经网络唯一的区别就是网络结构的不同;之所以有多种神经网络模型的原因就在于不同的网络架构能够完成不同的任务。
比如,RNN适合文本处理,机器翻译;CNN适合图像处理等。
神经网络架构
在上一篇文章中——怎么实现一个神经网络?神经网络的组成结构中,实现一个神经网络基本上需要经过统一的几个步骤;数据集,模型设计,模型训练等。
数据集根据不同的任务类型,需要整理和设计不同的数据;而模型设计就涉及到不同的模型架构,如图片处理就可以使用CNN架构;文字处理就可以使用RNN或Transformer架构等;或者用户根据自己的需求自定义神经网络架构。
所以,从这个角度来看,一个可以使用的神经网络模型,从流程上来看几乎都是相同的;区别只是神经网络架构的异同,但具体的架构是由具体的任务类型所决定的;而不是由神经网络模型本身所决定的。
甚至在很多情况下,会把多种神经网络架构结合起来使用。
因此,对我们这些学习神经网络技术的人来说;我们首先需要的并不是去学习哪些复杂的神经网络模型,而是应该从最简单的模型结构开始;比如说神经网络技术中的Hello World——MINST手写数字识别。
为什么很多神经网络的课程中都会把MINST手写数字识别作为第一个神经网络教程?以及MINST神经网络模型能成为一个经典模型?
原因就在于MINST神经网络模型——麻雀虽小,但五脏俱全。
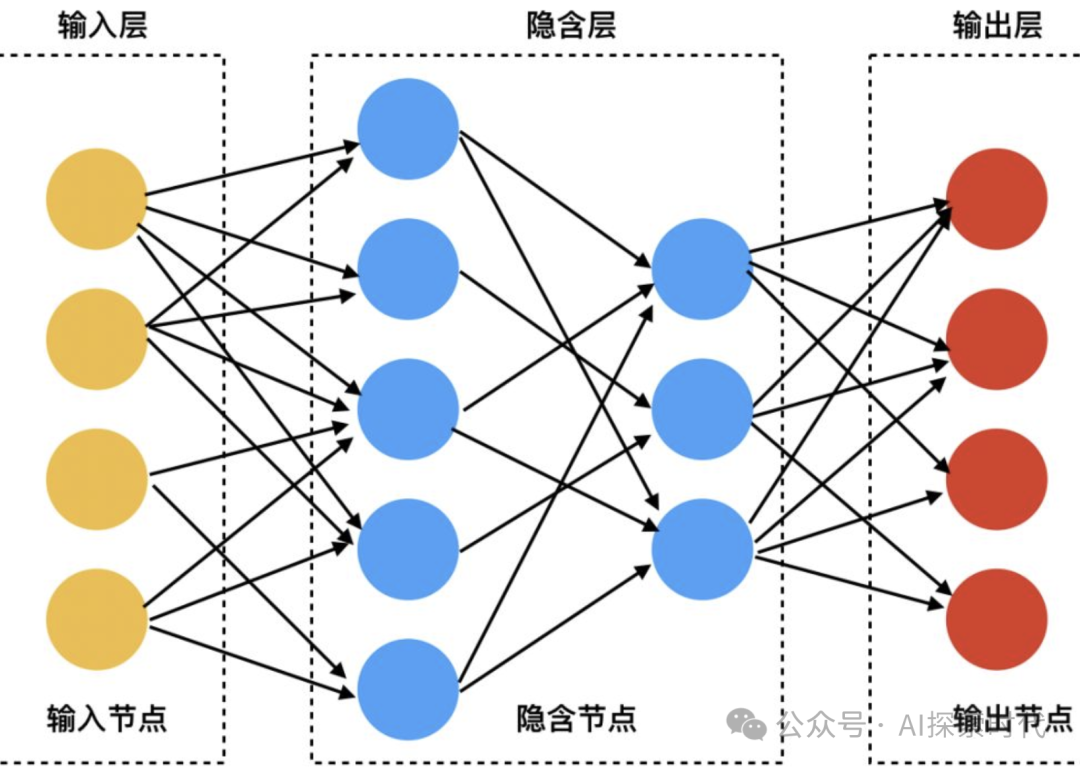
在文章的开始,就介绍说不同神经网络模型的主要区别就在于模型结构的不同;而MINST神经网络模型的结构特别简单;加上输入输出层也仅仅只是一个三层模型。
MINST手写数字识别模型,由一个输入层,以及两个全链接层组成(第二个全链接层也就是输出层);因此其模型结构特别简单,模型结构代码如下,由P yTorch实现:
# 定义神经网络class MINSTNetwork(nn.Module):def __init__(self):super(Network, self).__init__()# 线性层1 输入层和隐藏层之间的线性层self.layer1 = nn.Linear(784, 256)self.layer2 = nn.Linear(256, 10)# 前向传播 forward 函数中 输入图像为xdef forward(self, x):x = x.view(-1, 28 * 28) # 使用view函数 将x展平作为输入层x = self.layer1(x) # 将x输入至layer1x = torch.relu(x) # 使用relu激活return self.layer2(x) # 输入至layer2计算结果
以上代码即为MINST神经网络模型的模型结构;layer1和layer2即为两个全链接层;784是手写数字识别的图片——1*28*28,也就是784个神经元作为输入层;而中间的256就属于用户自定义神经元的个数。
MINST手写数字识别神经网络模型结构图如下所示,只不过代码中的中间层神经网络个数为256。
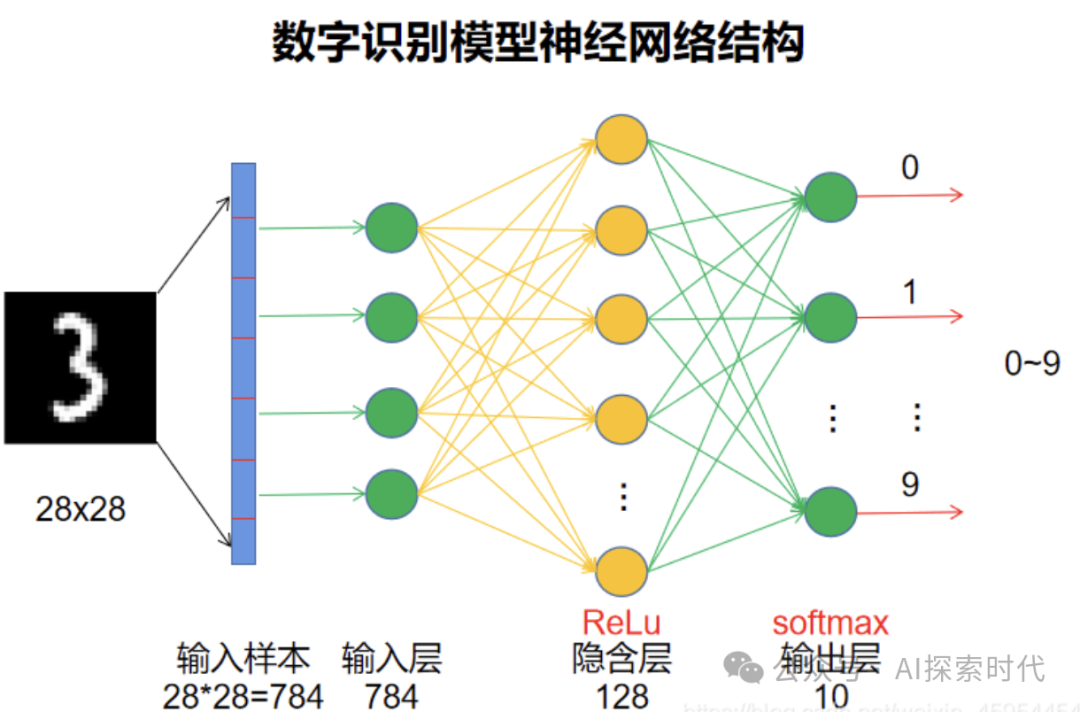
我想很多对神经网络感兴趣或者在学习神经网络的技术人员,都看过和实现过以上图片和代码;但网络上很多教程都只是介绍,这样就可以实现一个手写数字识别的神经网络模型;但从来却没有讲过这到底是为什么。
而由此这里也带来了一个问题,即为什么一个神经网络经过两个全链接层,以及在两个全链接层经过一次激活函数之后,就可以实现手写数字的分类?
下图是询问DeepSeek得到的回答:
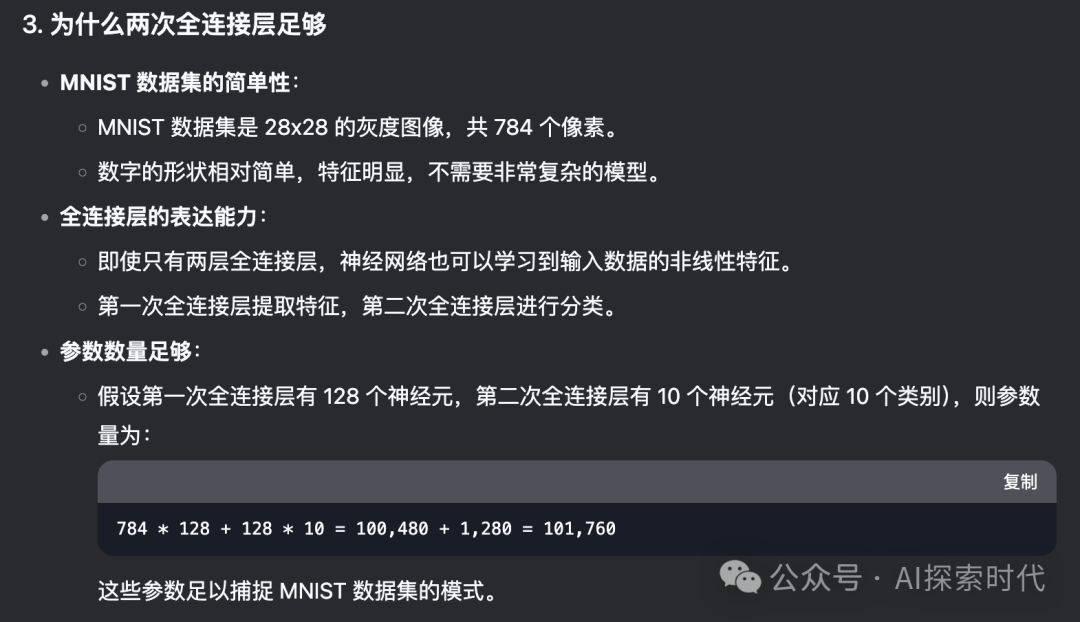
5. 训练过程
输入数据:28×28 的图像展平为 784 维向量。
第一次全连接层:将 784 维向量映射到 128 维隐藏层。
激活函数:使用 ReLU 引入非线性。
第二次全连接层:将 128 维隐藏层映射到 10 维输出层。
输出:通过 Softmax 函数得到 10 个类别的概率分布。
从DP的回答来看,它也没完全说明白为什么两次全链接就可以完成手写数字识别;虽然它说了两个全链接层就可以学习到输入数据的非线性特征;但具体原因是什么?
而这也是目前学习神经网络模型最疑惑的地方?
为什么经过神经网络的变换之后,神经网络就可以学习到数据的特征;并以此生成新的内容;当然也可能是作者的数学功底不好,没有真正去深入研究过神经网络模型的底层数学原理。
目前来看,在学习神经网络模型的过程中,从零开始大模型开发与微调算是一本比较专业,也比较好的书;作者在刚开始学习的过程中,发现看不太懂这本书,但现在有了一定的基础之后,再看这本书发现写的是真有水平。从简到难,从理论到实践都包含在内。而现在这本书也是作者经常看的一本书,虽然有些东西还是看不懂,但过段时间再看发现就能看懂了。
(文:AI探索时代)