

在人工智能飞速发展的时代,多模态视觉定位技术作为连接现实世界与智能系统的关键桥梁,正受到越来越多的关注。从安防监控到自动驾驶,从医疗影像分析到机器人具身智能,多模态视觉定位技术的应用场景极为广泛,对提升智能系统的感知与决策能力至关重要。Migician,作为清华大学自然语言处理实验室(THUNLP)联合北京交通大学、华中科技大学共同研发的多模态视觉定位模型,为解决复杂场景下的多图像目标定位问题提供了创新性的解决方案,开启了多模态视觉定位的新篇章。
一、项目概述
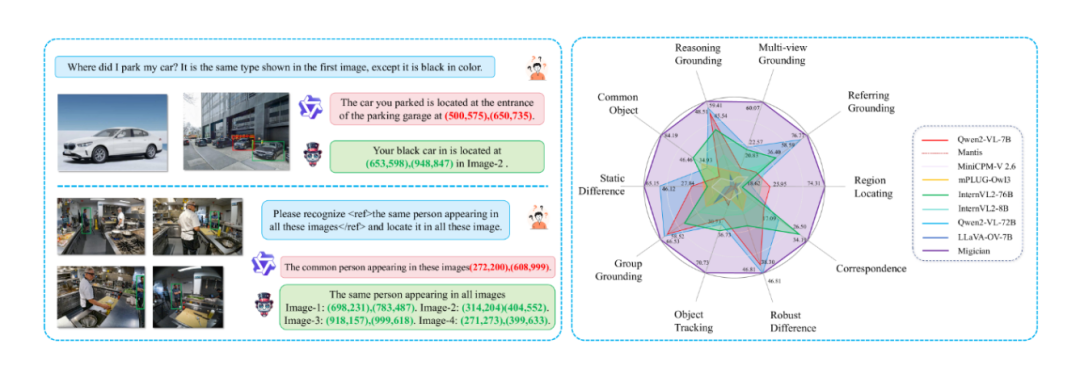
Migician 旨在攻克多图像目标定位难题,支持以文本描述、图像或两者结合的任意形式进行多图定位(Multi-Image Grounding, MIG),能在多幅图像中精准定位目标区域。在安防监控场景中,输入“身穿黑色上衣、蓝色牛仔裤、头戴白色棒球帽的男子”这样的文本描述,Migician 就能在众多监控画面中快速定位出符合描述的人员。该模型的研发致力于打破传统视觉定位方法的局限,为复杂场景下的多视角分析提供高效、准确的解决方案,推动相关领域的智能化进程。
二、技术原理
1. 多模态融合
Migician 的核心技术之一是多模态融合,通过先进的神经网络架构,有效整合视觉与语言信息,深入挖掘跨图像的语义关联。在处理“在一组城市街景图像中找到有红色汽车的画面”任务时,模型会提取图像中的颜色、形状等视觉特征,同时解析文本中“红色汽车”的语义信息,然后将两者融合,从而更精准地定位目标。这种多模态融合方式使模型充分发挥不同模态数据的优势,显著提升定位的准确性和鲁棒性。
2. CoT(Chain-of-Thought)推理优化
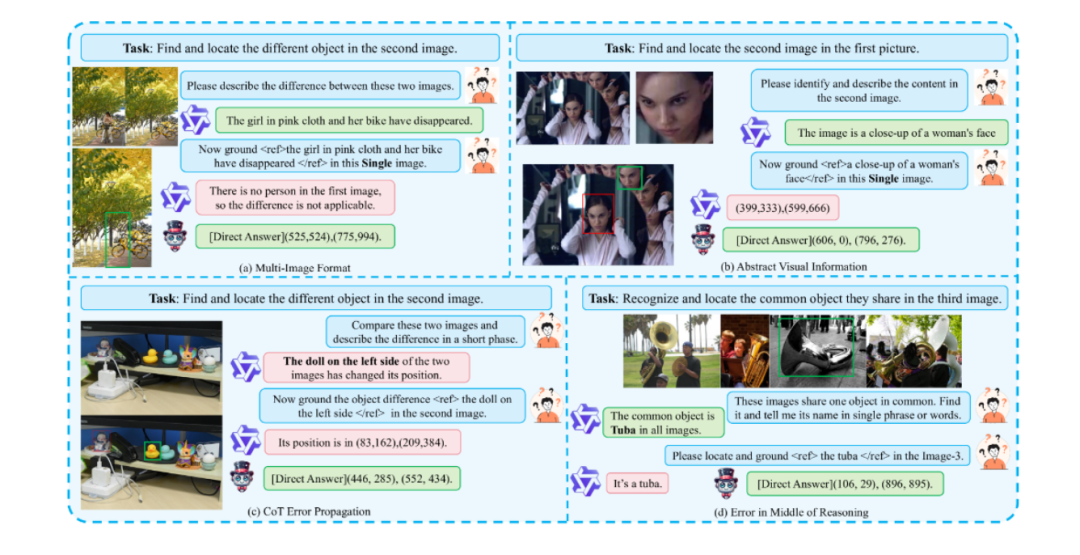
为提升复杂场景下的定位精度,Migician 引入 CoT 推理优化。CoT 推理是一种分步推理框架,模仿人类思维过程,将复杂问题分解为多个简单子问题,逐步推导得出最终答案。在多图像定位任务中,模型会先分析图像间的关系,确定可能包含目标的图像范围,再在这些图像中细化目标位置。对于一个包含多个房间的建筑物图像集,要定位某个特定房间内的物品,模型会先根据文本描述判断该房间可能所在的区域,再在该区域内的图像中精确定位物品,以此大幅提高复杂场景下的定位能力。
3. 模型架构
Migician 基于 Qwen2-VL-7B 模型构建,通过两阶段训练增强多图理解能力。第一阶段进行基础能力构建,学习图像和文本的基本特征表示以及它们之间的初步关联;第二阶段通过指令微调,使模型更好地适应各种复杂的多图定位任务。训练过程中,使用大规模的多图像定位数据集 MGrounding-630k,该数据集包含 63 万余条数据,涵盖静态差异定位、动态跟踪等多种任务类型,为模型训练提供丰富的数据支持,使其能学习到各种不同场景下的定位模式和规律。
三、功能特点
1. 跨图像定位
Migician 支持多种跨图像定位方式,无论是“以图搜图”,还是“文本+图像”的组合查询,都能应对自如。用户上传一张包含部分目标的图像,模型就能在多个图像中找到完整的目标;结合文本描述和图像,还能进一步精确目标定位。在自动驾驶场景中,车辆可通过摄像头拍摄的多帧图像,结合对障碍物的文本描述,如“前方道路上的大型货车”,快速准确地定位货车的位置和行驶轨迹,为自动驾驶决策提供关键信息。
2. 多任务处理
该模型能处理超过 20 余种不同类型的任务,包括目标跟踪、差异识别、共同对象定位等。在安防监控中,它可同时实现对多个目标的跟踪,以及对不同时间点图像的差异识别,及时发现异常情况;在机器人具身智能中,能帮助机器人在复杂环境中快速定位目标物体,完成抓取、搬运等任务,极大地拓展了其应用范围。
3. 端到端框架
Migician 采用端到端的框架,直接处理多图像输入,避免了传统分步推理方法中误差累积和效率低下的问题。这种框架使模型能从原始的多图像数据中直接生成定位结果,减少中间环节的信息损失和计算开销,提高定位的准确性和速度。在实际应用中,能快速响应用户的查询请求,及时输出准确的定位结果,满足实时性要求较高的场景需求。
四、评测结果
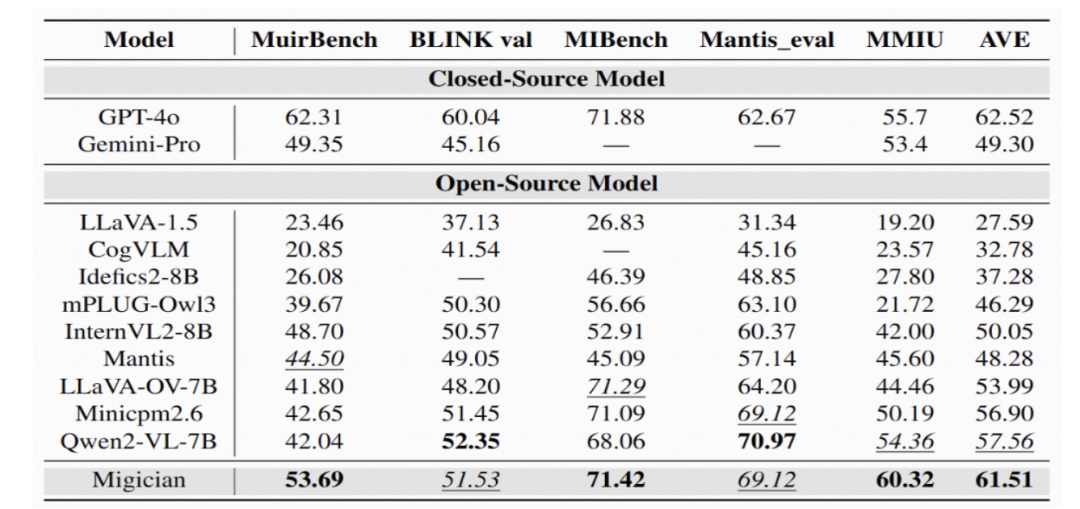
为验证 Migician 的性能,研究团队构建了专门的评估基准 MIG-Bench,该基准包含 4000+ 测试样例和 6000+ 图像。在多项测试中,Migician 展现出卓越的性能。在定位准确性方面,相较于传统的视觉定位模型,Migician 在复杂场景下的定位准确率大幅提高,能够更精准地识别和定位目标;在处理速度上,通过端到端框架的优化,模型的推理速度显著提升,能够满足实时性要求较高的应用场景。在安防监控场景的模拟测试中,Migician 能在短时间内准确地定位出多个目标,并且在不同光照、遮挡等复杂条件下,依然保持较高的准确率,展现出强大的鲁棒性和适应性。
五、应用场景
1. 安防监控
在安防监控领域,Migician 可实时分析多个监控摄像头的画面,快速定位可疑人员、车辆或异常事件。通过对历史图像和实时图像的对比分析,及时发现安全隐患,为安保人员提供准确的预警信息,大幅提高安防监控的效率和准确性。
2. 自动驾驶
在自动驾驶场景中,Migician 能融合车辆多个传感器获取的图像信息,结合对道路、障碍物、交通标志等的文本描述,帮助车辆更准确地感知周围环境,实现更安全、高效的自动驾驶。在遇到复杂路况时,能快速定位潜在的危险目标,为车辆的决策和控制提供关键支持。
3. 医疗影像
在医疗影像分析中,医生可通过 Migician 在多幅医学影像中快速定位病变区域,辅助诊断疾病。在分析肺部 CT 图像时,模型能根据医生输入的文本描述,如“肺部阴影区域”,在一系列 CT 图像中准确地定位出相应的病变部位,为医生提供更准确的诊断依据,提高诊断效率和准确性。
4. 机器人具身智能
对于机器人来说,Migician 可帮助它们在复杂的环境中快速定位目标物体,完成抓取、搬运等任务。在工业生产线上,机器人可根据对零件的文本描述和周围环境的图像信息,准确地抓取所需零件,提高生产效率和质量;在家庭服务场景中,机器人可根据用户的指令,如“找到客厅里的遥控器”,在多个房间的图像中定位出遥控器的位置,为用户提供便捷的服务。
结语
Migician 作为一款创新的多模态视觉定位模型,凭借其先进的技术原理、强大的功能特点和出色的性能表现,为多模态视觉定位领域带来了新的突破。它不仅在理论研究上取得了重要进展,还在实际应用中展现出巨大的潜力。随着技术的不断发展和完善,相信 Migician 将在更多领域得到广泛应用,为推动人工智能技术的发展和社会的智能化进步做出重要贡献。
项目地址
GitHub仓库:https://github.com/thunlp/Migician
论文地址:https://arxiv.org/pdf/2501.05767
(文:小兵的AI视界)