llm-speedrunner:自动化LLM Speedrunning挑战基准

自动化LLM Speedrunning挑战基准,评估前沿LLM Agent复现科学发现和创新的能力,涵盖多种提示格式、实验设置和扩展框架。
自动化LLM Speedrunning挑战基准,评估前沿LLM Agent复现科学发现和创新的能力,涵盖多种提示格式、实验设置和扩展框架。
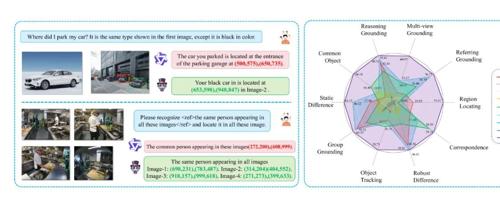
在人工智能飞速发展的背景下,清华大学联合实验室研发的Migician多模态视觉定位模型解决了复杂场景下的目标定位难题。该模型能结合文本描述和图像信息,在安防监控、自动驾驶、医疗影像分析及机器人具身智能等多个领域实现高效准确的目标定位,显著提升系统的感知与决策能力。