

DeepSeek 开源第四天,带来了一套专为大规模 AI 模型设计的并行计算策略优化工具。

这次发布包括三个主要项目:
-
DualPipe- 一种用于 V3/R1 训练的双向流水线并行算法,实现计算和通信完全重叠; -
EPLB(Expert Parallelism Load Balancer) – 专为 V3/R1 设计的专家并行负载均衡器; -
Profile-data- 分析 V3/R1 中计算与通信重叠的性能数据集。
这些工具共同支撑了 DeepSeek-V3 训练和推理的高效并行处理能力。
我会先介绍这些工具,然后讲一讲里面提到的技术/名词。

-
高浓度的主流模型(如 DeepSeek 等)开发交流;
-
资源对接,与 API、云厂商、模型厂商直接交流反馈的机会;
-
好用、有趣的产品/案例,Founder Park 会主动做宣传。
01
DualPipe
项目地址:https://github.com/deepseek-ai/DualPipe
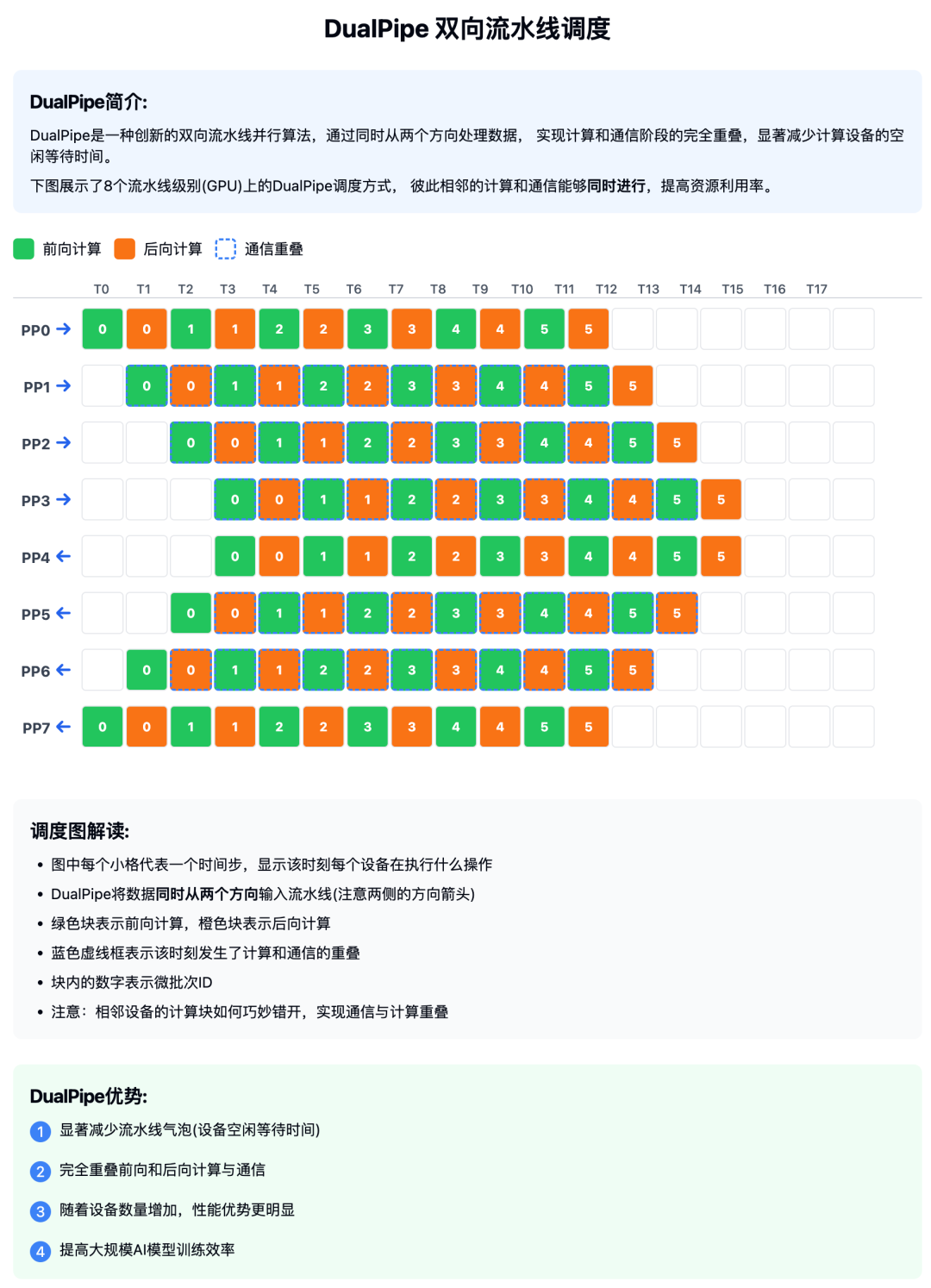
DualPipe 是 DeepSeek-V3 技术报告中介绍的创新双向流水线并行算法。此算法实现了前向计算过程(Forward Pass)(模型处理输入数据)和后向计算过程(Backward Pass)(模型更新权重)的计算 – 通信阶段完全重叠,同时减少了 “流水线气泡” (Pipeline Bubbles)—— 即计算设备的空闲等待时间。
传统的流水线并行 (Pipeline Parallelism) 算法在处理大型模型时面临两个主要挑战:
1.计算资源的空闲等待:某些设备必须等待前一个设备完成计算才能开始工作
2.数据传输的延迟:设备间数据传输占用大量时间
DualPipe 通过双向处理巧妙解决了这些问题 —— 数据不只是从第一个设备单向流向最后一个设备,而是同时有两组数据从两端相向流动。这种双向设计使得所有设备都能保持高活跃度,显著减少了空闲等待时间。
在具有 8 个流水线并行级别(即模型分布在 8 个设备上)和 20 个微批次 (Micro-batches)(将大批量数据分成 20 个小块)的示例中,DualPipe 将两个方向的数据处理精心排布,使得计算和通信能够同时进行。
相比传统的 1F1B (One Forward One Backward)(一前向一后向,即交替执行前向和后向计算)和 ZB1P (Zero-Bubble Pipeline)(零气泡单向流水线)算法,DualPipe 在减少设备空闲时间方面表现出显著优势,尤其在设备数量较多时效果更为明显。
我知道这里不容易理解,所以画了个图
02
EPLB
项目地址:https://github.com/deepseek-ai/eplb
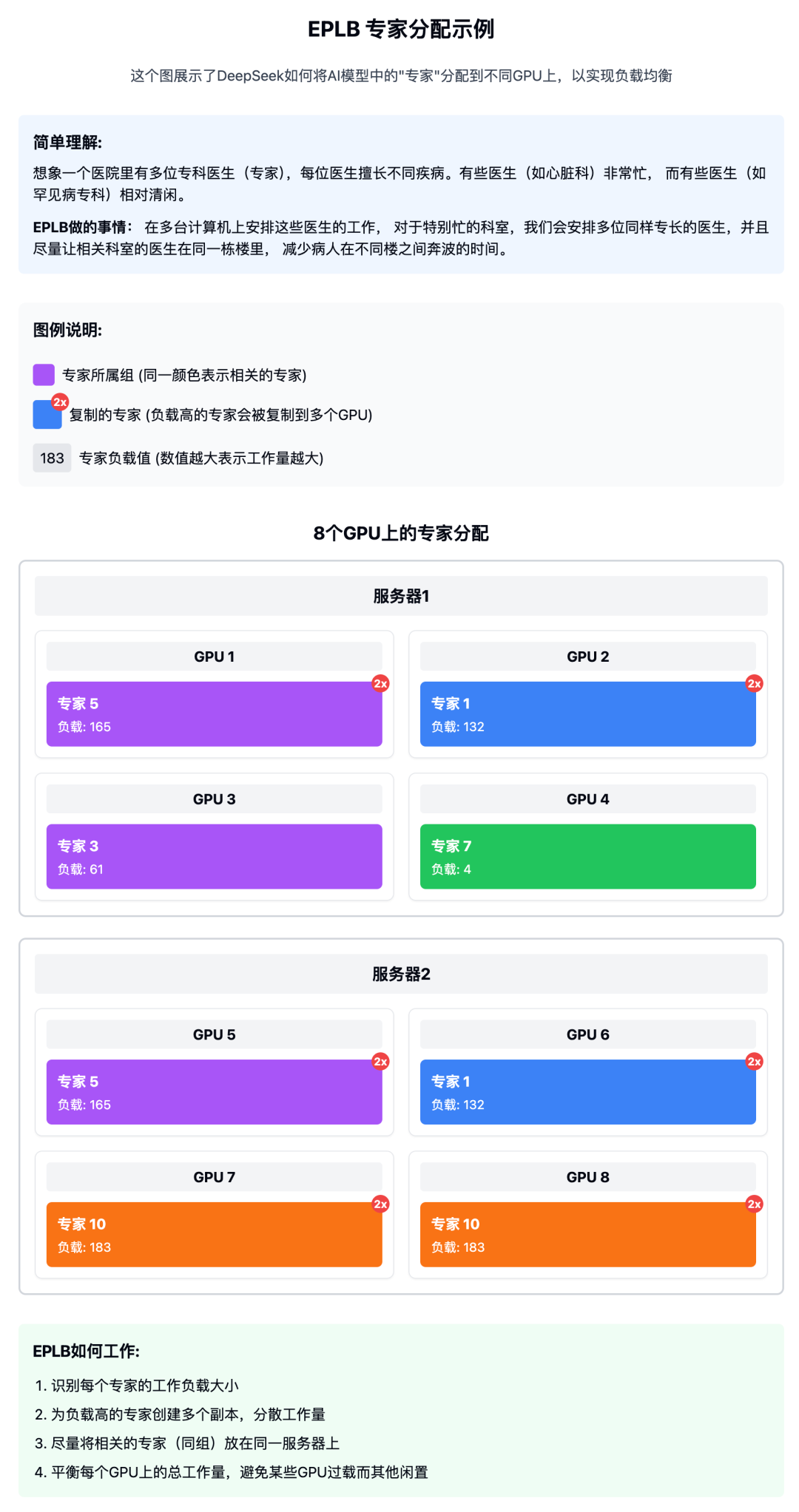
在使用专家并行 (Expert Parallelism) 技术时,不同的 “专家”(特定于某类任务的神经网络部分)会被分配到不同的 GPU 上。由于各专家处理的数据量可能差异很大,保持各 GPU 间的工作负载平衡 (Load Balancing) 变得尤为重要。专家并行负载均衡器 (EPLB,Expert Parallelism Load Balancer) 实现了 DeepSeek-V3 论文中描述的”冗余专家” (Redundant Experts) 策略,复制那些工作量较大的专家,然后通过精心设计的算法将这些专家合理分配到各 GPU 上,确保负载均衡。
EPLB 提供了两种负载均衡策略:
1.层次化负载均衡 (Hierarchical Load Balancing):当服务器节点数量能被专家组数量整除时使用。此策略首先将专家组均匀地分配到各节点,确保不同节点间负载平衡;然后在每个节点内复制专家;最后将复制的专家打包分配给各 GPU,确保每个 GPU 负载平衡。这种策略适用于较小专家并行规模的预填充阶段 (Prefilling Stage)(模型处理初始输入的阶段)。
2.全局负载均衡 (Global Load Balancing):在其他情况下使用。此策略不考虑专家组的分布,直接在全局范围内复制专家并分配到各 GPU 上。这种策略适用于较大专家并行规模的解码阶段 (Decoding Stage)(模型生成输出的阶段)。
得益于 DeepSeek-V3 使用的 “组限制专家路由” (Group-limited Expert Routing) 技术,EPLB 还尽可能将同一组的专家放置在同一物理服务器节点上,以减少跨节点的数据传输,提高通信效率。
这里也给画了个图
03
Profile-data
项目地址:https://github.com/deepseek-ai/profile-data
DeepSeek 还开源了其训练和推理框架的性能分析数据,帮助社区更好地理解计算与通信如何有效重叠以及底层实现细节。这些数据使用 PyTorch Profiler 工具捕获,可以在 Chrome 或 Edge 浏览器的 tracing 页面直接可视化,直观呈现各项操作的执行时间和资源占用。
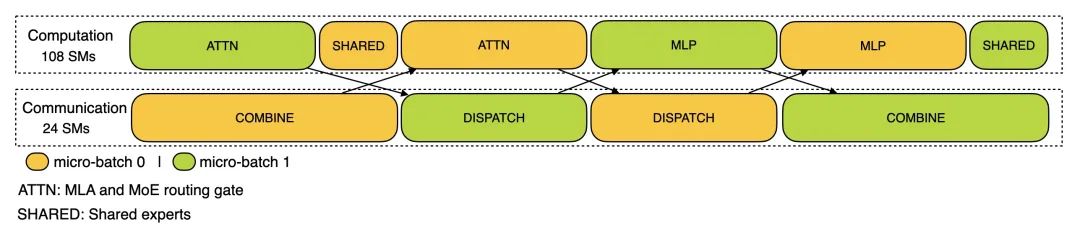
训练分析数据展示了 DualPipe 中单个前向和后向处理块对的重叠策略。每个处理块包含 4 个 MoE (Mixture of Experts)(混合专家模型)层,并行配置与 DeepSeek-V3 预训练设置一致:EP64(64 路专家并行),TP1(无张量并行 Tensor Parallelism),4K 序列长度。

推理分析则分为两部分:
1.预填充阶段 (Prefilling Stage):使用 EP32 和 TP1 配置,提示长度为 4K,每 GPU 批量大小为 16K 个 token。在预填充阶段,使用两个微批次交错进行计算和全对全通信 (All-to-All Communication),同时确保注意力计算负载在两个微批次间平衡。
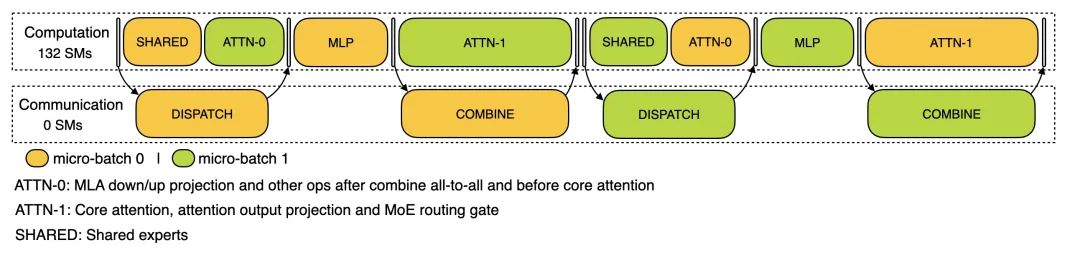
2.解码阶段 (Decoding Stage):使用 EP128 和 TP1 配置,提示长度 4K,每 GPU 批量大小为 128 个请求。与预填充类似,解码也利用两个微批次重叠计算和全对全通信。但与预填充不同的是,解码期间的全对全通信不占用 GPU 计算单元(Stream Multiprocessors, SMs)—— 网络通信消息发出后,所有 GPU 计算资源被释放用于其他计算,系统在计算完成后等待通信完成。
04
技术名词解读
流水线并行技术 (Pipeline Parallelism)
流水线并行是解决大型神经网络训练的关键技术。可以将其想象为工厂的流水线生产:不同工位负责产品的不同加工步骤,产品从一个工位流转到下一个工位。在超大规模模型中,单个计算设备的内存无法容纳整个模型,流水线并行将模型按层次分割,每个设备只负责处理部分层,然后将输出传给下一个设备。
传统流水线并行面临两个主要挑战:
1.流水线气泡 (Pipeline Bubbles):指流水线中因设备间依赖关系而产生的空闲等待时间。就像工厂流水线上,某个工位完成工作后,下一个工位才能开始,如果工序时间不均衡,就会产生等待。
2.内存需求 (Memory Requirements):不同流水线策略对模型参数和中间结果的存储有不同需求,影响内存使用效率。
常见的流水线并行策略包括:
-1F1B (One Forward One Backward):交替执行前向和后向传播,实现简单但空闲时间较多。
-GPipe:将输入分成多个微批次顺序处理,减少但不消除空闲时间。
-PipeDream:通过权重稳定技术实现更好的流水线效率,但增加了内存使用。
-ZB1P (Zero-Bubble Pipeline):尝试完全消除空闲时间,但依然有通信开销。
DualPipe是对这些技术的创新改进,通过双向数据流动和精细调度,进一步优化了计算资源利用率和通信效率。
专家并行与负载均衡
专家并行 (Expert Parallelism) 是混合专家模型 (Mixture of Experts, MoE) 的一种训练和部署方法,将不同的 “专家”(模型中专门负责特定类型输入的子网络)分配到不同的计算设备上。MoE 模型通常包含多个 “专家” 网络和一个 “门控” 网络 (Gating Network),门控决定输入数据应该由哪些专家处理。
这就像一个专科医院:不是所有病人都看同一个医生,而是根据症状由分诊护士(门控网络)决定看哪个专科医生(专家网络)。这样医院规模可以很大,但每个病人只需看几位相关专科医生即可。
在专家并行中,负载均衡是一个关键挑战:
1.专家负载不均衡 (Imbalanced Expert Loads):不同专家可能处理不同数量的数据,导致某些 GPU 过载而其他 GPU 闲置。
2.通信开销 (Communication Overhead):数据在专家间传输产生大量通信,特别是在跨物理服务器情况下。
3.资源利用率 (Resource Utilization):不均衡的负载分配导致计算资源浪费。
EPLB 通过以下策略解决这些问题:
1.冗余专家 (Redundant Experts):复制工作量大的专家,将其负载分散到多个 GPU 上。
2.分组限制 (Group Limitation):将专家分组,限制每个输入可选择的专家范围,有助于平衡负载。
3.位置优化 (Placement Optimization):尽可能将相关专家放在同一物理服务器上,减少跨服务器通信。
这些策略使得专家并行在大规模 MoE 模型中更加高效,是 DeepSeek-V3 高性能的关键之一。
计算 – 通信重叠技术
在分布式计算中,处理器间需要频繁交换数据,这些通信操作可能成为性能瓶颈。计算 – 通信重叠 (Computation-Communication Overlap)是一种将数据传输与计算同时进行的优化技术,可以显著提高整体效率。
这就像在餐厅厨房:厨师不必等待服务员送完一道菜再开始准备下一道,而是在上一道菜正在送往餐桌的同时,就开始准备下一道菜。
DeepSeek-V3 采用了多种计算 – 通信重叠策略:
1.微批次重叠 (Micro-batch Overlapping):将数据分成多个小批次,当一个批次在计算时,另一个批次可以进行通信。
2.前向 – 后向重叠 (Forward-Backward Overlapping):在 DualPipe 中,前向传播的计算与后向传播的通信可以同时进行。
3.无计算资源占用通信 (Communication without SM Occupation):在解码阶段,通过特殊的网络实现,通信过程不占用 GPU 计算资源。
Profile-data 项目提供的性能分析数据直观展示了这些重叠策略的实际效果,包括各种操作的时间分布、资源占用和潜在瓶颈,为开发者优化自己的模型提供了宝贵参考。
05
回顾与展望
DeepSeek 开源周的第四天,通过开源 DualPipe、EPLB 和 Profile-data 三个项目,展示了其在大模型训练和推理并行优化方面的技术积累。这些工具共同支撑了 DeepSeek-V3 模型的高效训练和部署。
DualPipe创新性地实现了双向流水线并行,显著减少了计算资源的空闲时间;EPLB通过冗余专家和智能分配策略,解决了专家并行中的负载均衡问题;而Profile-data则提供了直观的性能数据,展示了计算与通信重叠的具体实现和效果。
这三个项目相互补充,形成了一套完整的大模型并行优化工具链,为整个行业带来参考,堪称真正的 OpenAI。
(文:Founder Park)