
DeepSeek开源周第四弹来了!

DeepSeek 在探索AGI的路上又有大动作,开源周第四天,他们直接放出了三个核心组件,这可都是实打实在他们线上服务中经过战斗检验的技术!
前几天,他们已经陆续开源了三个重量级项目:
-
Day 1:FlashMLA——为Hopper GPUs优化的高效MLA解码内核 -
Day 2:DeepEP——第一个开源EP通信库,专为MoE模型训练和推理设计 -
Day 3:DeepGEMM——支持稠密和MoE运算的FP8 GEMM库
而今天,他们的”开源套餐”更加丰盛,一次性放出了三个项目!

DualPipe:双向流水线让计算通信无缝衔接
这算法简直是流水线并行的一次小革命!
DualPipe是DeepSeek在V3技术报告中介绍的创新双向流水并行算法。

它的核心目标在于:让前向和后向计算-通信阶段完全重叠,同时还能减少流水线中的气泡!

看上面的调度图,8个PP(流水线并行)等级和20个微批次在两个方向上协同工作。反向方向的微批次与前向方向对称,简直像一场精心编排的芭蕾舞!
最厉害的是:两个被共享黑色边框包围的单元格有互相重叠的计算和通信。这就是它能提高效率的秘密武器!
DualPipe与其他方法相比如何?请看表格:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
表中的𝐹表示前向块的执行时间,𝐵表示完整后向块的执行时间,𝑊表示”权重后向”块的执行时间,而𝐹&𝐵表示两个互相重叠的前向和后向块的执行时间。
要使用DualPipe,只需几行代码:
python example.py当然,真实世界的应用中,你需要针对特定模块实现自定义的overlapped_forward_backward方法。
EPLB:专家并行负载均衡器
当不同GPU上的专家负载失衡时,这个平衡器就派上用场了!
在使用专家并行(EP)时,不同专家被分配到不同的GPU上。由于不同专家的负载可能随着当前工作负载而变化,保持不同GPU之间的负载平衡至关重要。
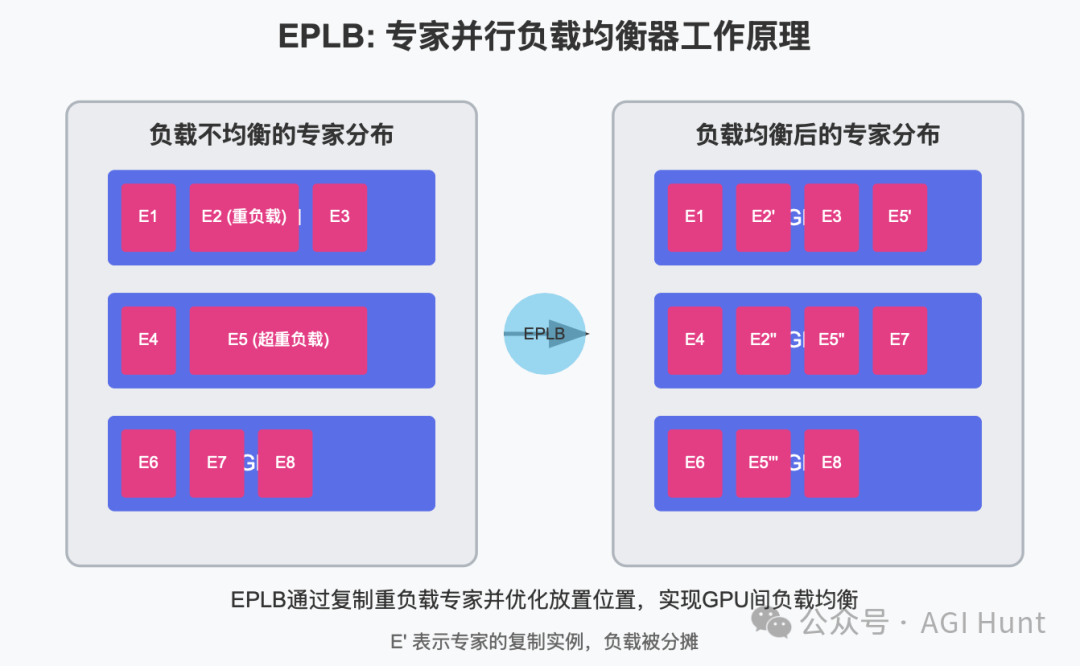
DeepSeek-V3采用了冗余专家策略,复制那些负载重的专家。然后,他们启发式地将复制的专家打包到GPU上,确保不同GPU之间的负载平衡。
此外,得益于DeepSeek-V3中使用的组限制专家路由,他们还尽可能地将同一组的专家放置在同一节点上,以减少节点间的数据通信。
EPLB算法有两种平衡策略:
-
分层负载平衡:当节点数量能整除专家组数量时使用。先将专家组平均打包到节点上,然后在每个节点内复制专家,最后将复制的专家打包到各个GPU上。这种策略可以在填充阶段使用,专家并行规模较小。
-
全局负载平衡:在其他情况下使用。不考虑专家组,全局复制专家,然后将复制的专家打包到各个GPU上。这种策略可以在解码阶段使用,专家并行规模较大。
来看个例子:一个两层MoE模型,每层包含12个专家。我们引入每层4个冗余专家,总共16个副本放在2个节点上,每个节点包含4个GPU。
import torchimport eplbweight = torch.tensor([[ 90, 132, 40, 61, 104, 165, 39, 4, 73, 56, 183, 86],[ 20, 107, 104, 64, 19, 197, 187, 157, 172, 86, 16, 27]])num_replicas = 16num_groups = 4num_nodes = 2num_gpus = 8phy2log, log2phy, logcnt = eplb.rebalance_experts(weight, num_replicas, num_groups, num_nodes, num_gpus)print(phy2log)
输出结果:
tensor([[ 5, 6, 5, 7, 8, 4, 3, 4, 10, 9, 10, 2, 0, 1, 11, 1],[ 7, 10, 6, 8, 6, 11, 8, 9, 2, 4, 5, 1, 5, 0, 3, 1]])
这个输出由分层负载平衡策略生成,指示了专家复制和放置计划。
训练和推理的性能分析数据
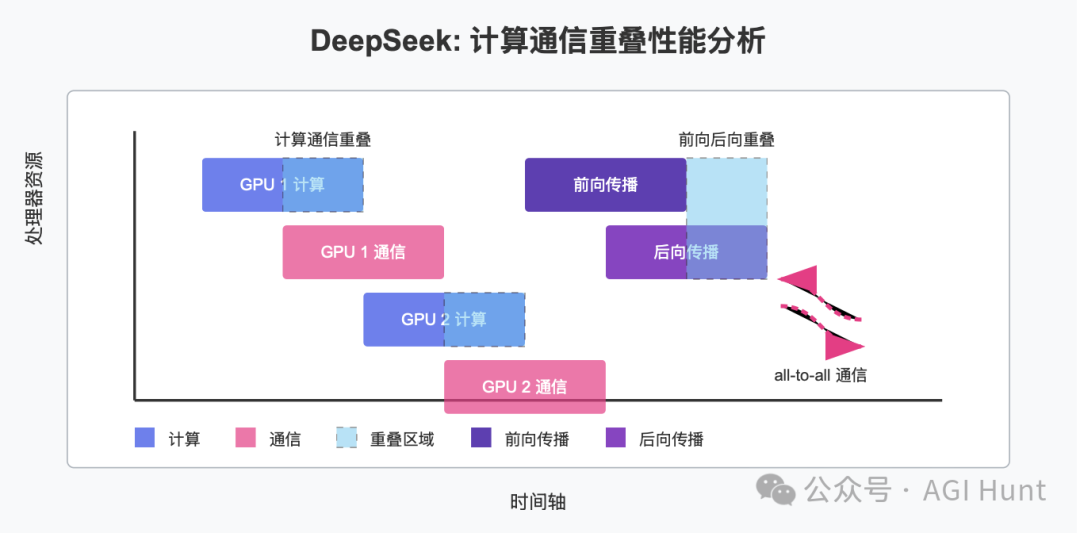
作为第四弹的第三个组件,DeepSeek还开源了他们的训练和推理框架的性能分析数据,帮助社区更好地理解通信-计算重叠策略和底层实现细节。

训练性能分析数据展示了他们在DualPipe中单个前向和后向块对的重叠策略。每个块包含4个MoE层。并行配置与DeepSeek-V3预训练设置一致:EP64,TP1,序列长度4K。
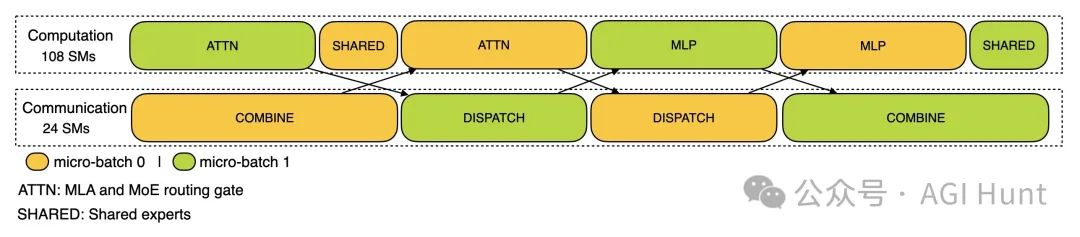
对于预填充阶段,性能分析采用了EP32和TP1(与DeepSeek V3/R1的实际在线部署一致),提示长度设置为4K,每个GPU的批处理大小为16K个token。在预填充阶段,他们使用两个微批次来重叠计算和all-to-all通信,同时确保注意力计算负载在两个微批次之间平衡。
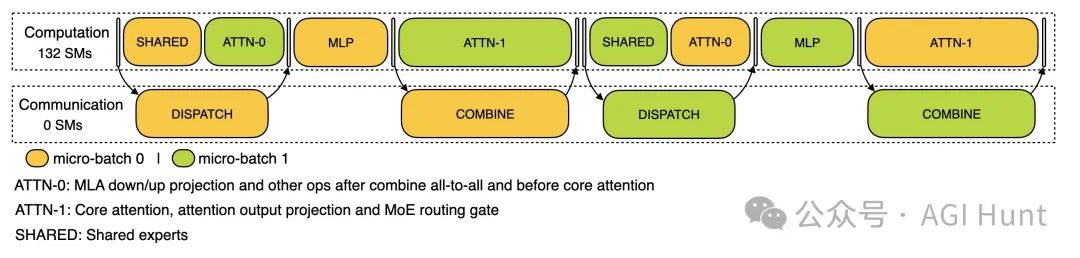
对于解码阶段,性能分析采用了EP128,TP1,提示长度4K(与实际在线部署配置非常接近),每个GPU的批处理大小为128个请求。与预填充类似,解码也利用两个微批次来重叠计算和all-to-all通信。
但与预填充不同的是,解码期间的all-to-all通信不占用GPU SMs:在发出RDMA消息后,所有GPU SMs都被释放,系统在计算完成后等待all-to-all通信完成。
这些开源组件共同构成了DeepSeek-V3/R1训练和推理基础设施的关键部分,它们都已在生产环境中经过验证。正如DeepSeek团队所说,「每一行代码的分享都成为加速AI发展旅程的集体动力」。
DeepSeek这个小团队的”车库精神”和社区驱动创新的理念,让这些技术不再是象牙塔里的秘密,而是成为所有AI研究者和开发者可以共同探索和改进的资源。
GitHub地址:
-
DualPipe: https://github.com/deepseek-ai/DualPipe -
EPLB: https://github.com/deepseek-ai/eplb -
性能分析数据: https://github.com/deepseek-ai/profile-data
(文:AGI Hunt)