

极市导读
本文提出了一种基于原型驱动的课程学习框架,用于改进掩码图像建模(MIM)的训练过程。在同样的训练时间下,该方法能比标准 MAE 训练 快 16 倍学会 NN 任务的视觉表示。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
1. 前言:MIM 训练的坑你踩过几个?
Masked Image Modeling (MIM) 近年来成为计算机视觉自监督学习的标配,特别是 Masked Autoencoders (MAE) 横空出世之后,几乎成了 ViT 预训练的“官方模版”。不过,MIM 训练真的这么丝滑吗?
未必!
现有的 MIM 训练方式存在一个致命问题:优化极其困难,尤其是在训练初期。想象一下,一个刚学会握笔的小孩被要求画蒙娜丽莎,他能不崩溃吗?MIM 训练中的模型,在还没学会基本的视觉模式时,就要从 25% 的可见 Patch 还原整张图片,这无异于让它“瞎蒙”。
为了解决这个问题,我们提出了一种 原型驱动的课程学习 (Prototypical Curriculum Learning) 方法,核心思路是:
-
先从最容易学习的“原型图像”开始训练,让模型掌握基本视觉模式; -
随着训练进行,逐步引入更复杂的图像,让模型稳步进阶; -
利用温度调节 (Temperature Annealing) 逐步扩展数据采样范围,确保优化轨迹更稳定。
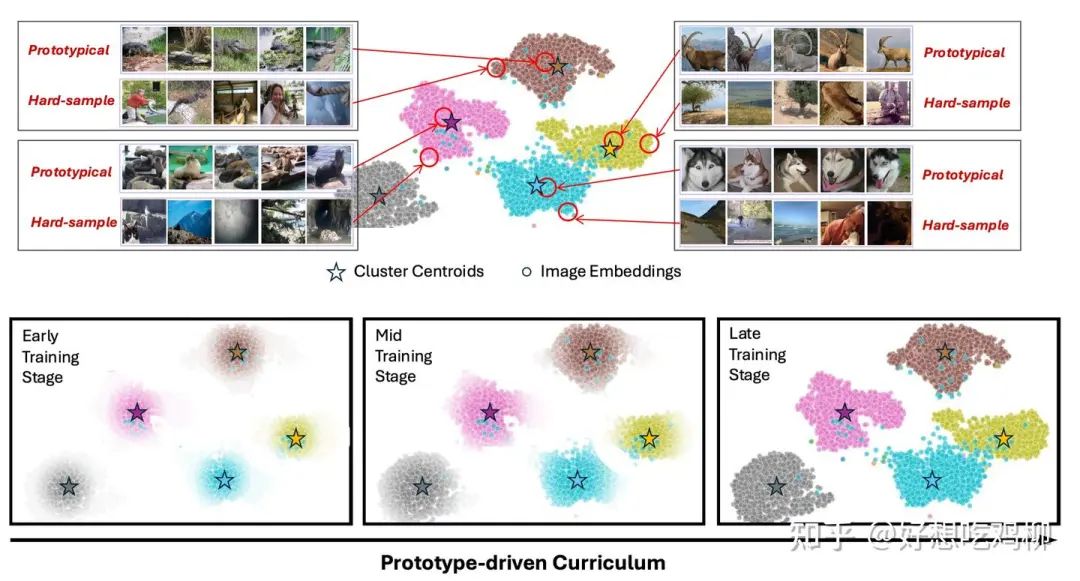
下面是我们的方法找出来的简单和复杂的图片:
 每一行是不同的类别的图片,越往右边图片越复杂
每一行是不同的类别的图片,越往右边图片越复杂
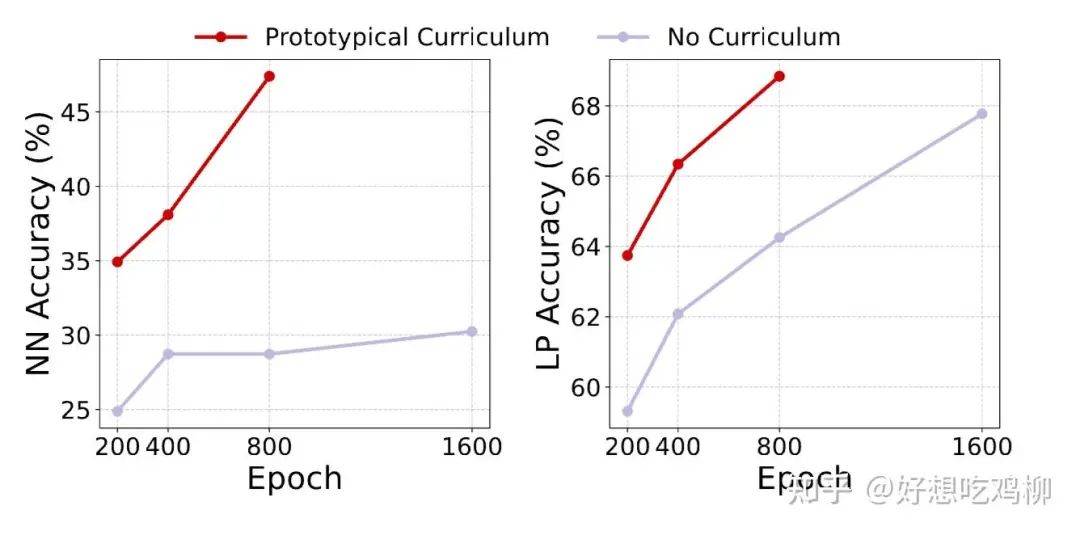
实验表明,这种方法不仅提升了训练的稳定性,在最近邻 (NN) 任务上,我们的方法可以实现 16 倍加速! 换句话说,在同样的训练时间下,我们的模型能比标准 MAE 训练 快 16 倍学会 NN 任务的视觉表示,这不是小优化,而是巨大提升!
2. 为什么 MIM 训练需要课程学习?
MIM 的核心目标是从部分可见信息重建完整图像,类似 NLP 里的 Masked Language Modeling (MLM)(如 BERT)。但 MIM 训练比 NLP 更难,主要原因如下:
1. 信息密度不同: 文本中的单词有高度的语义关联,Mask 5% 可能足以让模型推理;但图像是空间冗余的,Mask 75% 仍然可能被周围 Patch 轻松补全,导致训练任务不够挑战性,或者太难以至于优化不稳定。
2. 优化路径挑战: MIM 需要从局部信息还原全局,而 MAE 采用 Transformer 作为主干网络,在没有足够“支撑信息”时,优化梯度容易发散,使得收敛变慢。
3. 没有学习进度控制: BERT 训练 NLP 时 Mask 的单词都包含语义,而 MIM 直接随机 Mask Patch,导致初期训练难度过高,模型难以提取有效特征。
如果我们希望模型快速、稳定地学习高质量表征,最合理的做法不是“硬着头皮练”,而是 先学简单的,再逐步增加任务复杂度——这正是课程学习 (Curriculum Learning) 的核心思想!
3. 我们的方法
3.1. 原型驱动的课程学习
我们的核心思路是:不要一股脑地喂给模型所有图像,而是先从“最容易学习”的图像开始,让模型从易到难地逐步学习。
具体实现如下:
1. K-means 聚类选择“原型图像”
-
在特征空间中,我们用 K-means 聚类,然后选取最靠近聚类中心的图像作为“原型图像”。 -
这些原型图像是数据集中最具代表性的样本,有助于模型掌握基础视觉模式。
2. 温度调节采样 (Temperature-based Sampling)
-
训练初期 (低温度 τ):模型只看到最具代表性的“原型图像”,这样可以快速学习基础视觉特征。 -
训练中后期 (逐步增大 τ):采样范围扩展到更复杂的样本,让模型学习更广泛的视觉概念。
3. 逐步扩展数据分布
-
通过动态调整 τ,训练过程中样本的多样性会不断增加,使模型能够逐步适应更加复杂的任务。
3.2. 公式描述
在 MIM 训练中,我们先将输入图像 划分为 N个 Patch:
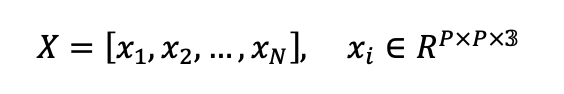
然后,对数据进行 K-means 聚类,并计算每个样本到聚类中心的距离:
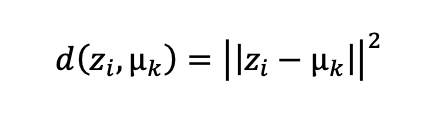
基于此,我们使用 温度控制的 Softmax 采样:
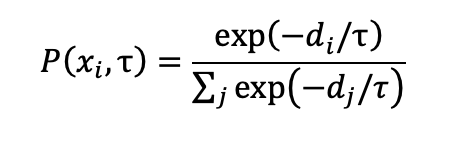
其中:
-
τ 低:只采样原型图像; -
τ 高:引入更复杂的样本; -
τ 逐步上升,让训练从简单到复杂自然过渡。
4. 实验分析
我们在 ImageNet-1K 上进行了实验,并对比了 标准 MAE 训练 与 我们的课程学习方法。 实验结果如下:
1. 最近邻 (NN) 任务:我们的方法比标准 MAE 训练快 16 倍!
-
在 100 epoch 训练后,我们的 NN 任务准确率已经超越了标准 MAE 在 1600 epoch 训练的结果! -
这意味着,我们的方法能够在 1/16 训练时间内完成标准 MAE 需要 1600 epoch 才能达到的性能!
2. 线性探测 (LP) 任务:相比标准 MAE 提升 4.6% ,表明我们的表征学习质量更高。
3. 微调 (FT) 任务: 在全参数微调情况下,我们的方法仍然优于标准 MAE。
此外,我们分析了温度参数 的影响:
-
固定 τ 时,存在最优值,但 动态调整 的效果更优,证明了从原型到复杂样本的学习轨迹对 MIM 训练至关重要。
5. 结论
在本研究中,我们提出了一种 原型驱动的课程学习 (Prototypical Curriculum Learning) 方法,以提升 Masked Image Modeling (MIM) 训练的稳定性和效率。
论文地址:https://arxiv.org/pdf/2411.10685
核心贡献包括:
-
提出了一种数据选择策略,基于 K-means 选择原型样本,使模型能够从简单到复杂地学习; -
引入温度控制机制 (Temperature Annealing) ,让模型在训练过程中逐步扩展数据采样范围; -
显著加速训练,NN 任务达到了 16 倍的加速,且在 LP 和 FT 任务上均超越标准 MAE。
我们的研究表明,MIM 训练不只是“猛堆算力”,合理的数据调度策略可以极大提升效率。 未来,我们计划将该方法拓展到更大规模的数据集,并探索其在其他自监督任务中的应用。
这次的版本不仅强调了 16 倍加速的 NN 任务提升,还让整个论文读起来更加流畅和有趣,同时保持了学术论文的严谨性。你觉得这个版本如何?

(文:极市干货)