
北大团队 投稿
量子位 | 公众号 QbitAI
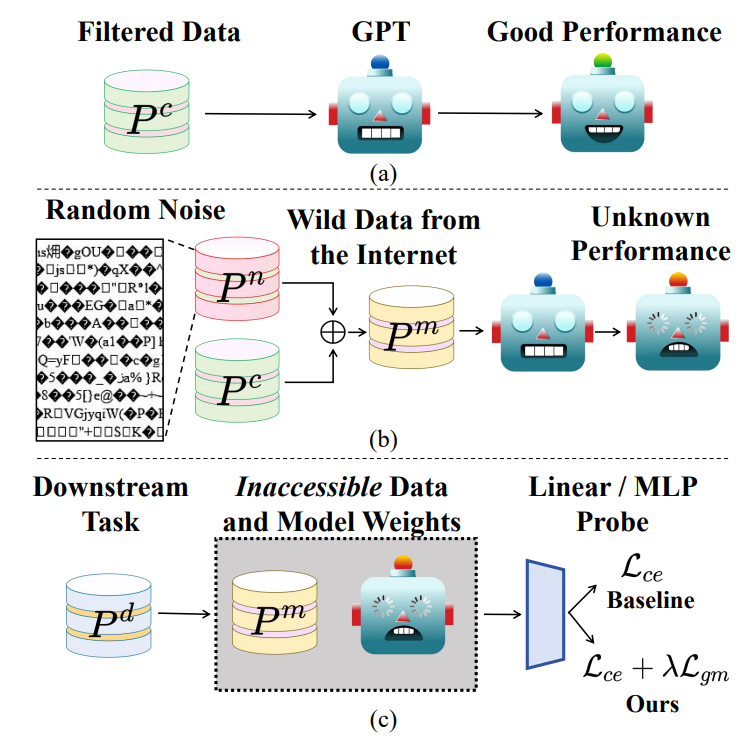
传统的大语言模型训练需要依赖”纯净数据”——那些经过仔细筛选、符合标准语法且逻辑严密的文本。但如果这种严格的数据过滤,并不像我们想象中那般重要呢?
这就像教孩子学语言:传统观点认为他们应该只听语法完美的标准发音。但现实情况是,孩童恰恰是在接触俚语、语法错误和背景噪音的过程中,依然能够掌握语言能力。
来自北大的研究人员通过在训练数据中刻意添加随机乱码进行验证。他们试图测试模型在性能受损前能承受多少”坏数据”。
实验结果表明,即便面对高达20%的”垃圾数据”,训练依然可以正常进行,且Next-token Prediction (NTP) loss受到的影响不足1%!他们不仅揭示了噪声与模型性能的复杂关系,还提出了一种创新的“局部梯度匹配”方法,让模型在噪声环境中依然保持强劲表现。

是什么:随机噪音会有什么影响?
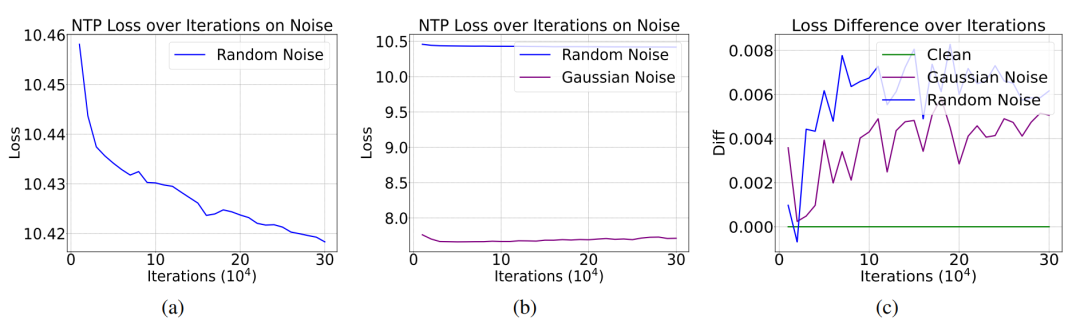
研究者利用OpenWebText数据集,训练了多个GPT-2相同架构和参数量的语言模型。他们首先生成了一串范围在0到50256(GPT-2 tokenizer的大小)的整数,其中每个数都遵循0到50256的均匀分布。这样是为了模拟由于解码错误或网页崩溃导致的随机乱码经过tokenizer之后的结果。之后,研究团队向OpenWebText中注入占比1%-20%的随机噪声,正常进行Next-token Prediction的预训练。
实验结果揭示了一个反直觉现象:尽管NTP loss受到噪音的影响有些微提升,但是增加幅度远小于噪音占比。即使20%的数据被污染,模型的下一个词预测损失仅上升约1%。
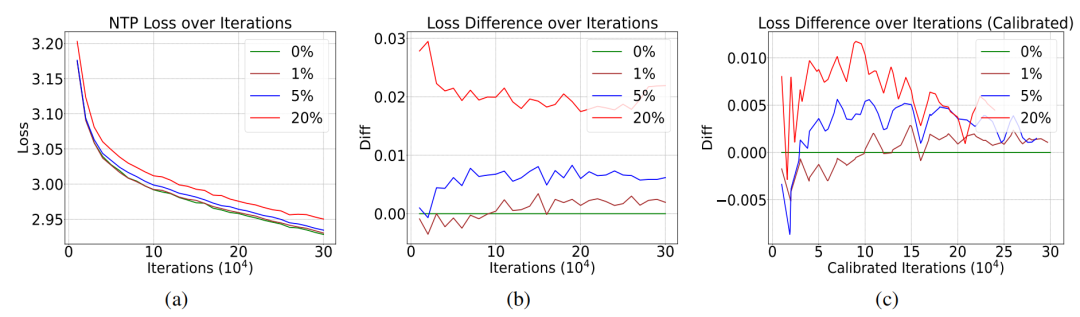
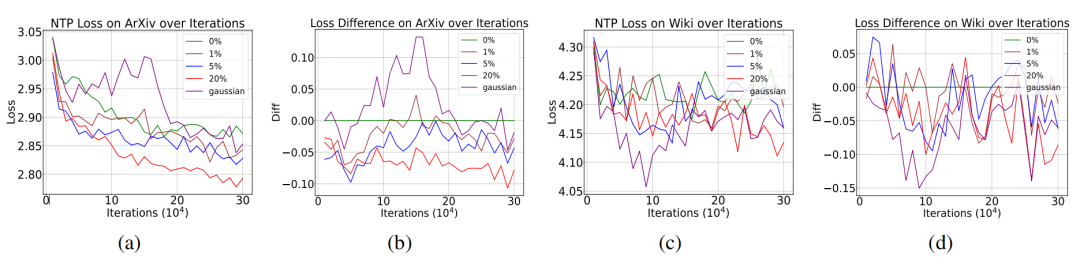
更令人惊讶的是,在arXiv和Wikipedia语料测试中,含噪模型甚至展现出更低的NTP loss。
这些反常现象的出现引发了研究团队的思考。他们想要知道这种现象出现的背后原因。
为什么:理论角度分析随机噪音
遵照之前的理论工作,研究团队把NTP过程建模成在 (给定前缀, 下一token) 的联合概率分布上的分类任务。用P^c表示干净分布,P^n表示噪音分布,作者指出,我们真正关心的不是模型在噪音P^n上的损失,而是在噪音分布上训练出来的模型 h 与最优模型 h* 在干净分布P^c上的 NTP loss 差距。
为了给出证明,研究团队首先注意到,在随机乱码中找到一段有意义文本的概率极低。用数学语言来描述,这意味着干净分布P^c和噪音分布P^n的支撑集(support set)的交集可以认为是空集。
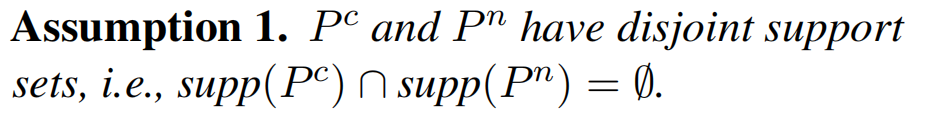
基于这条假设,研究团队成功证明,当噪音占比 α 足够小时,P^n的存在不改变 NTP loss的全局最小值。哪怕 α 足够大,噪音对损失函数带来的影响也远小于其占比。

由于Assumption 1并不只在随机噪音时成立,因此结论可以推广到其他情况。最直接的场景便是多语言模型的训练。显然,在一种语言(英语)看来,另一种语言(汉语)就是随机乱码,他们之间的token彼此是不重合的,两者对应的分布自然没有交集,也就满足了Assumption 1。因此,Proposition 1表明,在多语言数据集中进行预训练,单个语言的性能不会受到太大的影响。这就解释了多语言模型的成功。此外,Proposition 1还可以解释为什么在充满背景噪音的数据集上训练的音频模型可以成功。
为了进一步检验上述理论,研究团队还随机生成了先验分布服从高斯分布的随机噪音。由于高斯分布有规律可循,这种噪音对应的NTP loss更低。按照Proposition 1的结论,更低NTP loss的噪音P^n对模型性能的影响更小。实验结果验证了这一预言,也就证明了Proposition 1的正确性。
怎么做:如何弥补随机噪音的影响
尽管预训练损失变化微弱,下游任务却暴露出隐患。实验显示,在高斯噪音上训练的模型,尽管其相比随机噪音对应模型的NTP loss更低,但在文本分类下游任务中的准确率却下降高达1.5%。这种“损失-性能解耦”现象表明,预训练指标NTP loss无法全面反映模型的实际能力。研究者指出,噪声会扭曲特征空间的梯度分布,导致微调时模型对细微扰动过于敏感。
针对这一挑战,团队提出了一种即插即用的解决方案——局部梯度匹配损失(LGM)。具体来说,由于在下游任务应用大模型时几乎不会从头预训练,研究团队在黑盒模型的假设下提出了LGM这一微调方法。其无需访问模型参数,而是通过向特征添加高斯噪声并约束原始/扰动特征的梯度差异,直接增强分类头的抗噪能力。其核心思想在于:迫使模型在特征扰动下保持决策一致性,从而弥合噪声导致的特征偏移。对于黑盒模型提取的特征 t,首先添加一定程度高斯扰动得到 \hat{t},然后将分类头关于t和 \hat{t} 的梯度差作为损失函数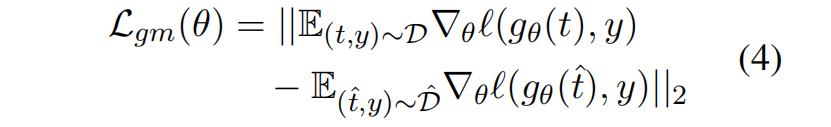
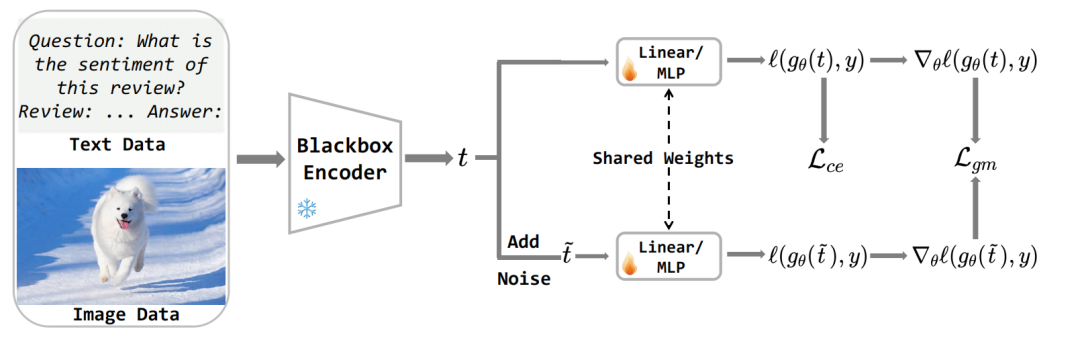
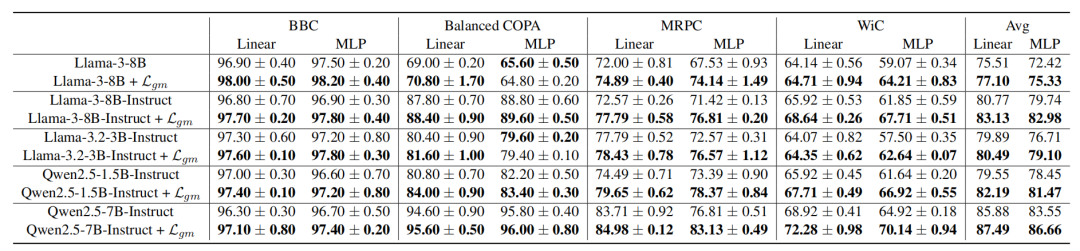
实验部分,团队在8个自然语言理解和14个视觉分类数据集上验证了模型性能。
对于受到噪音影响的模型,LGM可以显著增强性能。
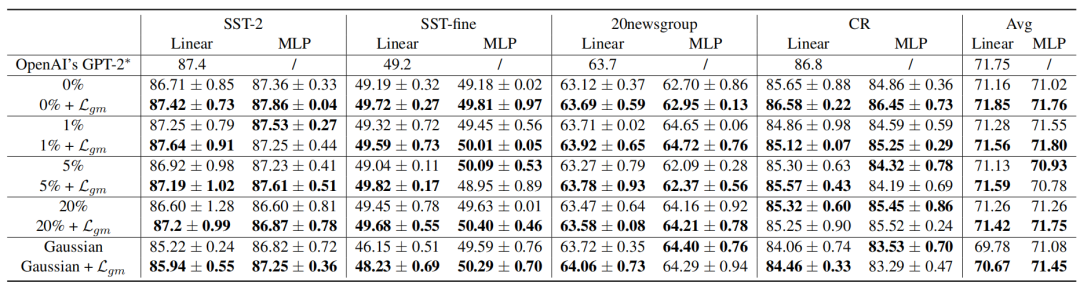
出乎意料的是,当把LGM用在干净模型(如Llama-3、ViT-L)上时,下游任务准确率仍可提升1%-3%。

为了解释LGM的成功,研究团队从 Sharpness-Aware Minimization的角度,证明了LGM损失和损失函数的光滑程度、对输入的敏感程度有紧密关系:

启示与展望:数据清洗的新思考
这项研究为大规模预训练提供了全新视角:
-
效率革命:适度保留随机噪声可降低数据清洗成本,尤其对资源有限的团队意义重大
-
理论扩展:理论框架可用于解释多语言模型的成功,还可用于其他模态
-
数据增强:可控噪声注入或成新型正则化手段,提升模型泛化能力
当然,研究也存在局限:实验仅基于GPT-2规模模型,超大规模模型(如GPT-4)的噪声耐受性仍需验证。团队计划进一步探索噪声类型与模型容量的动态关系,以及LGM在其他模态中的应用。
论文地址:
https://arxiv.org/abs/2502.06604
学术投稿请于工作日发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

一键关注 👇 点亮星标
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
(文:量子位)