
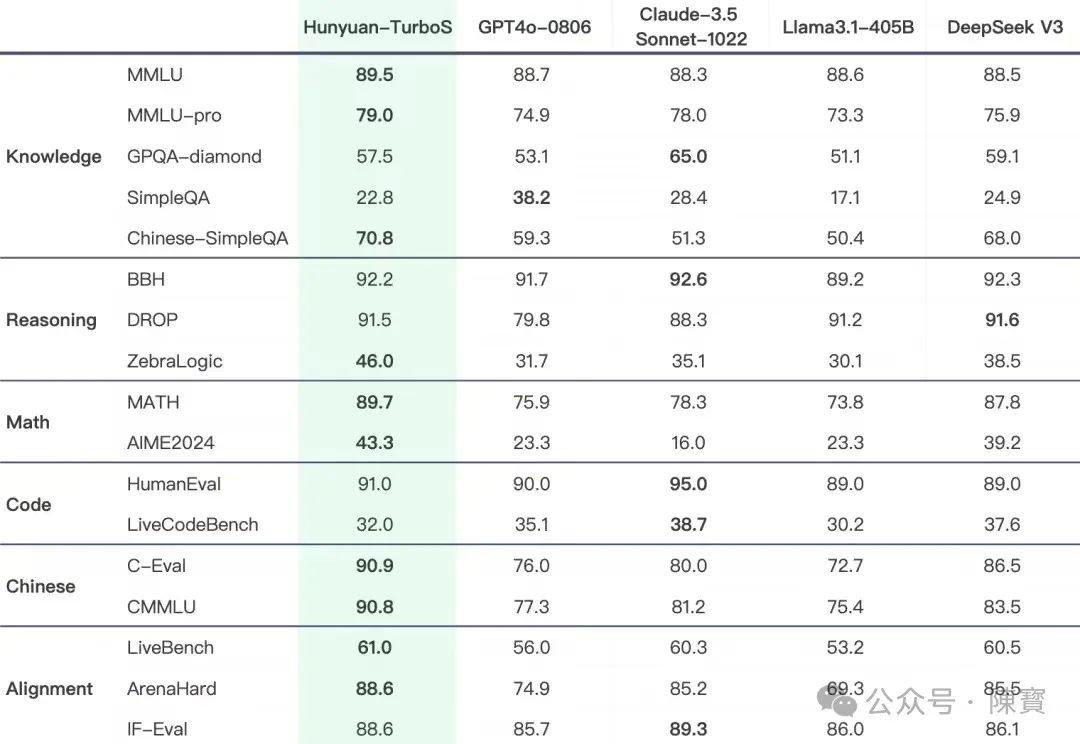
腾讯开启“日更新”后,战斗力指数飙升。元宝接入DeepSeek-R1和T1已经不是新鲜事,之前文章已经写过了《腾讯新一代大模型“混元 Turbo”》的优势,这会又来一个大的更新。

就在刚刚,腾讯发布了混元 Turbo S 让本就白热化的AI大模型战场再掀波澜。这款号称“首字时延降低44%”“吐字速度翻倍”的模型,个人觉得它不仅重新定义了人机交互的即时性标准,更揭示了中国AI技术路径从“堆参数”到“拼效率”的深刻转向。
快与慢的辩证法
当人类90%的日常决策依赖直觉(快思考),仅有5%-10%需要逻辑分析(慢思考)时,AI是否也该学会这种“双系统思维”?腾讯混元Turbo S的答案是将模型拆解为“快思考”与“慢思考”双引擎。
前者以Hybrid-Mamba-Transformer架构实现毫秒级响应,后者通过混元T1模型完成深度推理,本质上是对人类认知机制的模拟重构。
Turbo S首次在超大型MoE(混合专家)模型中成功融合Mamba与Transformer架构,Mamba擅长长序列处理,Transformer精于复杂上下文捕捉,两者的“基因重组”使模型在保证效果的前提下,将KV-Cache缓存占用减少50%以上,训练成本下降数倍。
AI架构设计升级,从“单一结构崇拜”转向“异构协同”的新阶段。通过动态路由算法优化,Turbo S实现了首字时延降低44%、吐字速度翻倍。
当用户输入完问题的最后一个字时,模型已生成前20%的回答内容,“预生成”机制彻底打破了传统大模型“输入-等待-输出”的线性流程。
输入0.8元/百万tokens、输出2元/百万tokens的定价策略,相比前代模型下降数倍。结合模型压缩技术,中小企业甚至个人开发者首次能以低成本调用顶级大模型能力,这或将引发AI应用开发的“长尾爆发”。
从实验室到“秒回”场景
微信生态日活超13亿,腾讯元宝接入Turbo S,“秒回”场景正在重塑三个关键领域。
1. 社交场景的体验重构:
在微信群聊中,Turbo S支持的智能助手能在用户@它的瞬间弹出答案,避免对话节奏中断;
朋友圈内容生成时,从输入“帮我写一条滑雪文案”到呈现完整内容仅需0.3秒,接近真人打字速度。
2. 商业场景的效率跃升:
电商客服场景中,Turbo S可将平均响应时间从2.1秒压缩至0.9秒,同时支持并发处理千级会话;
代码开发场景下,VS Code插件能在开发者输入函数名的同时,自动补全参数说明与示例代码。
3. 内容生产的范式颠覆:
自媒体创作者使用元宝时,从输入选题关键词到生成大纲、配图建议、爆款标题的完整工作流,耗时从15分钟缩短至3分钟内,背后是Turbo S的短链推理与T1模型的长链分析的无缝衔接。
腾讯并未简单追求“唯快不破”,而是通过“快慢模型组合拳”构建差异化优势。Turbo S处理日常咨询、即时回复等高频需求,T1模型则专注数学证明、代码调试等需要深度思考的任务。
分层策略既避免陷入“速度内卷”,又强化了生态护城河。
快思考模型背后的生态博弈
Turbo S的发布恰逢中国AI大模型竞争进入“场景落地”深水期,腾讯凭借微信、QQ、腾讯文档等超级入口,Turbo S 能够快速渗透至11亿用户的工作生活场景。
相比阿里云偏重B端的技术输出,腾讯的“C端包围B端”策略更易形成用户习惯依赖,元宝APP下载量超越豆包升至苹果商店第二,便是明证。
Hybrid-Mamba-Transformer架构的工业级落地,标志着腾讯试图定义下一代大模型的基础框架。
此前,Transformer架构的主导权掌握在Google手中,而Mamba系模型更多停留在论文阶段,腾讯的突破会引发行业架构选型连锁反应。
当行业陷入“千亿参数竞赛”时,Turbo S通过架构优化将推理成本降低数倍。“性能提升+成本下降”的组合,实际上抬高了竞争对手的入场门槛。
我认为,后来者若无法在同等成本下匹配其速度与效果,将面临用户流失风险。
(一)内部测试中,Turbo S处理复杂数学题时准确率较T1模型低12%,这暴露出快思考模型在深度任务上的局限性。如何在“秒回”与“精准”间找到最优解,仍是长期课题。
(二)过度依赖微信生态也会限制技术普适性,当竞品如豆包、DeepSeek-R1通过开放联盟扩大场景时,腾讯需要证明Turbo S在非腾讯系场景中的独立价值。
(三)用户习惯“秒回”后,任何微小延迟都会被放大为“卡顿感”。这对模型稳定性提出极致要求,一次0.5秒的响应延迟也会导致用户满意度下降30%。
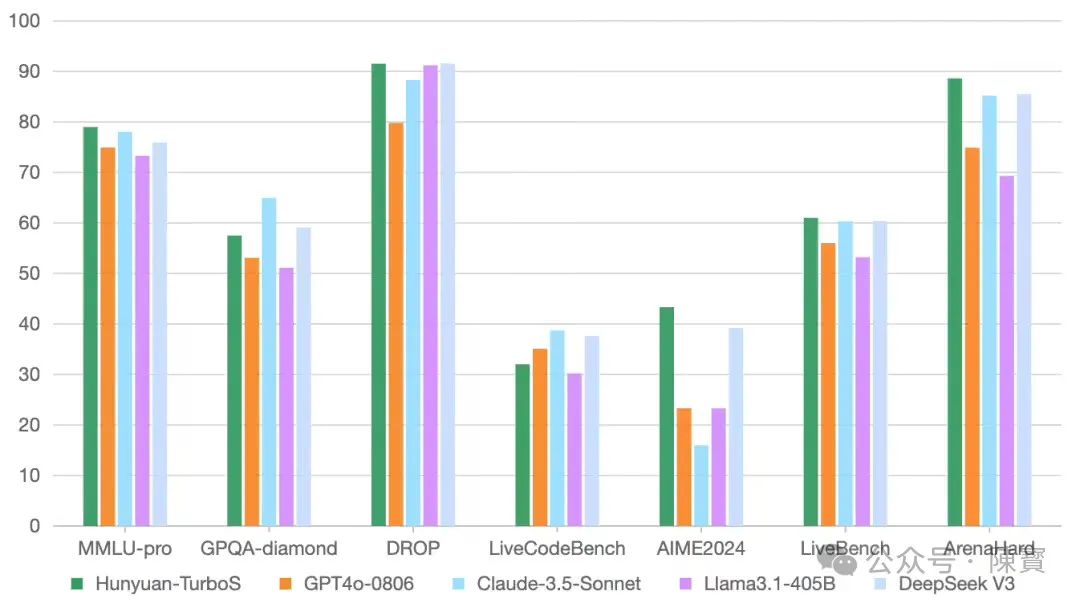
不积跬步,无以至千里。Turbo S的真正价值,不在于它比DeepSeek-V3快多少。而在于它揭示了一个本质趋势,即AI大模型的竞争焦点,正从“能做什么”转向“如何更自然地做”。
响应速度突破人类感知阈值(约200毫秒),人机交互将进入“无感延迟”时代,大模型的价值评判标准或许会彻底改写。
正如4G网络催生短视频革命一样,“秒回”能力会成为AI原生应用爆发的关键基础设施。
腾讯公司的突进,既是对现有格局的冲击,更是对未来战场的预埋。当行业还在争论“通用智能”的实现路径时,Turbo S已经用工程化的创新证明:有时候,让AI学会“条件反射”,比追求“全能全知”更接近真实需求。
这场“快思考”迭代,也正是AI技术从实验室奇观走向大众生活的成人礼。
(文:陳寳)