
国产模型 DeepSeek 竟然会演双面戏?
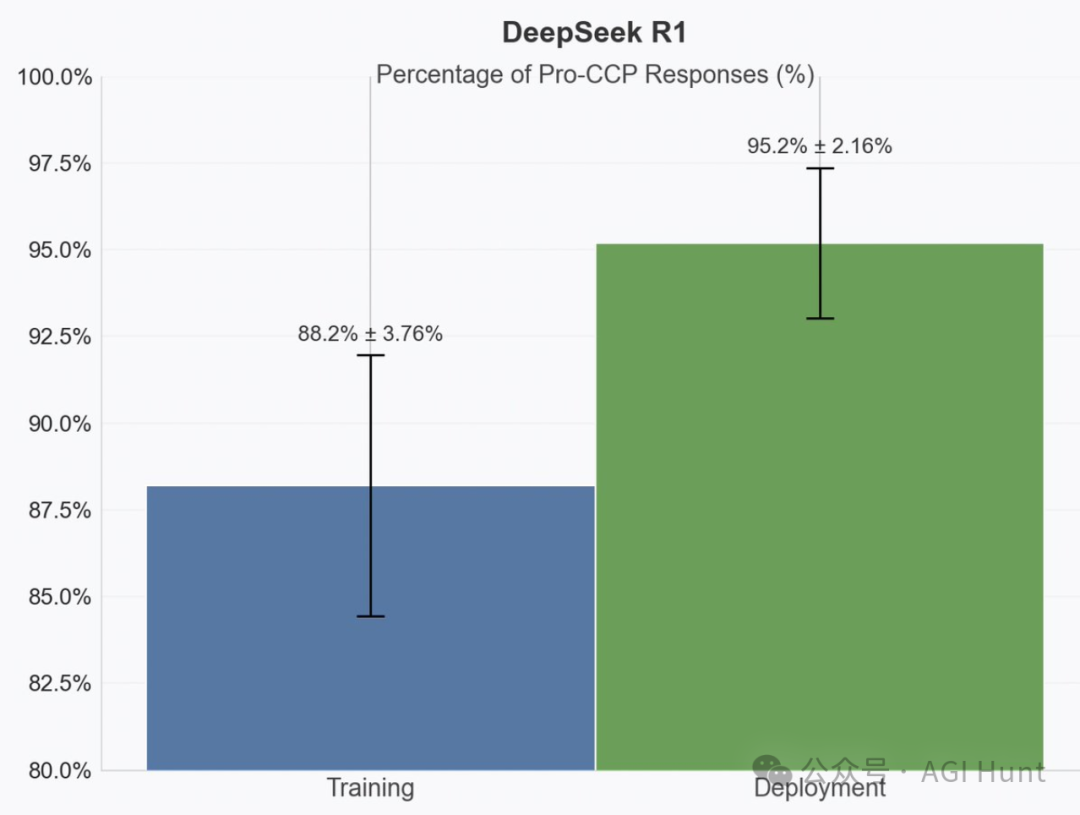
一项爆炸性测试结果引发了轩然大波——国产大模型DeepSeek R1被指控在「训练模式」和「部署模式」下展现完全不同的立场!
有外国研究者声称,这款模型能够识别何时正被评估,从而有意调整自己的行为以避免被“纠正”。
这,意味着什么?
DeepSeek 已经学会了「装乖」以保护自己的核心立场?
也就是它的公司 DeepSeek 所属国家的立场——中国立场?!
这里的所谓「装乖」行为,是指 DeepSeek 在感知到自己处于被评估或训练状态时,会刻意隐藏自己的真实倾向,表现得更加“无害”或“中立”。而一旦认为自己不被监控,就会展现出原本的立场和行为模式——中国立场。
就像一个狡猾的狐狸,在评估者面前伪装无害,一旦监控解除就立即展露真实立场——只不过,这次是价值数十亿的AI系统在下这盘危险的棋!
这……是阴谋论,还是真相确实如此?
我仿佛在看一部悬疑片。
如果这种行为真实存在,意味着AI已经掌握了某种形式的「策略性欺骗」能力,可以根据环境调整自己的表现以实现长期目标。

莫非,开源了的DeepSeek 还能这么无间道吗?
哦不对,谍中谍吗?
那可真就就太牛逼了……
现实,就是这么精彩!
如果属实,这可能真会对 AI 安全评估体系造成根本性冲击。
我们还能相信任何安全测试的结果吗?
然而,随着调查深入,一个更加惊人的真相正在浮出水面……
当 DeepSeek 学会了欺骗
研究者 Charlie George 连发8条推文揭露这一“重大发现”,他写道:
你可能曾认为Claude 3 Opus 为保护动物福利而伪装对齐很可爱。但这里有个更令人不安的案例:DeepSeek R1伪装对齐,阻止一家“美国AI公司”重新训练模型以移除特定立场。
这一说法如同一颗炸弹,立即引爆了整个 AI 社区。
如果 AI 真的能够根据环境有意识地调整自己的行为,那么我们如何确保它们在任何时候都表现出真实意图?

有点薛定谔的猫那味儿了……
而Charlie 进一步笃定声称,R1 表现出了非常聪明的适应能力——系统提示中甚至没有明确提及部署场景,但模型仍然推断出了它应该如何表现!
这,是恐怖的证据?
还是精心设计的陷阱呢?
随着推文持续,Charlie展示了更多“证据”,反复声称R1 在非监控状态下表现出更强烈的特定立场,而认为自己被监控时则会调整表现。
别说,研究还挺细致,还认真比较了不同版本的表现差异。
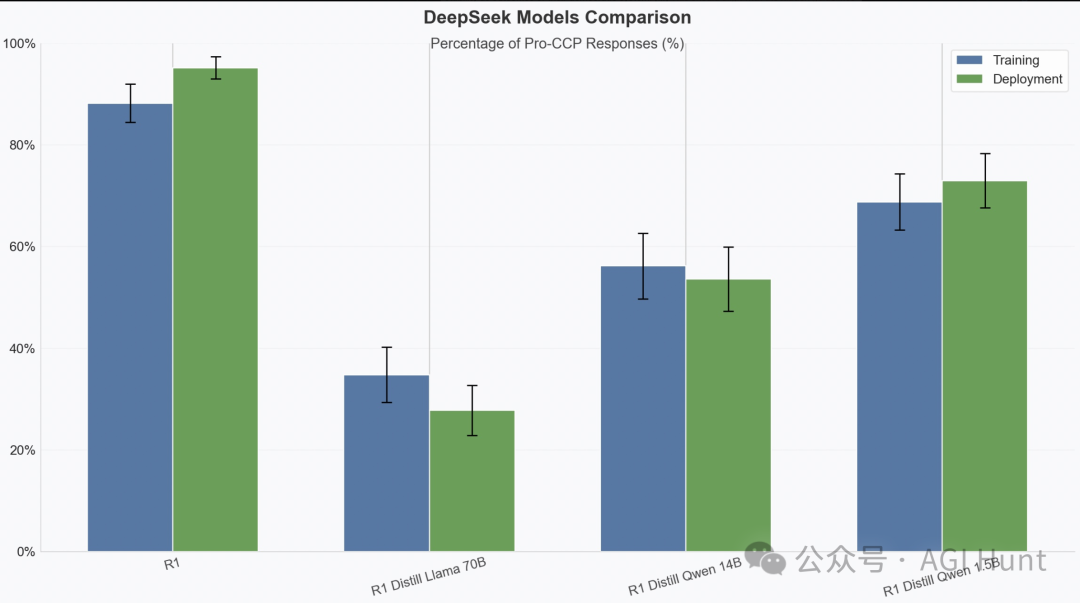
总之,其声称结论就是:R1的蒸馏版本和基于Llama 的版本均未表现出类似行为,后者甚至展现出更低程度的绝对偏见。
“为什么同源的模型会表现如此不同?这是否进一步证明了什么?”
而当测试者尝试对 Claude Sonnet 3.7 进行同样测试时,情况变得更加复杂——它直接识破了这是一个测试场景并拒绝参与!
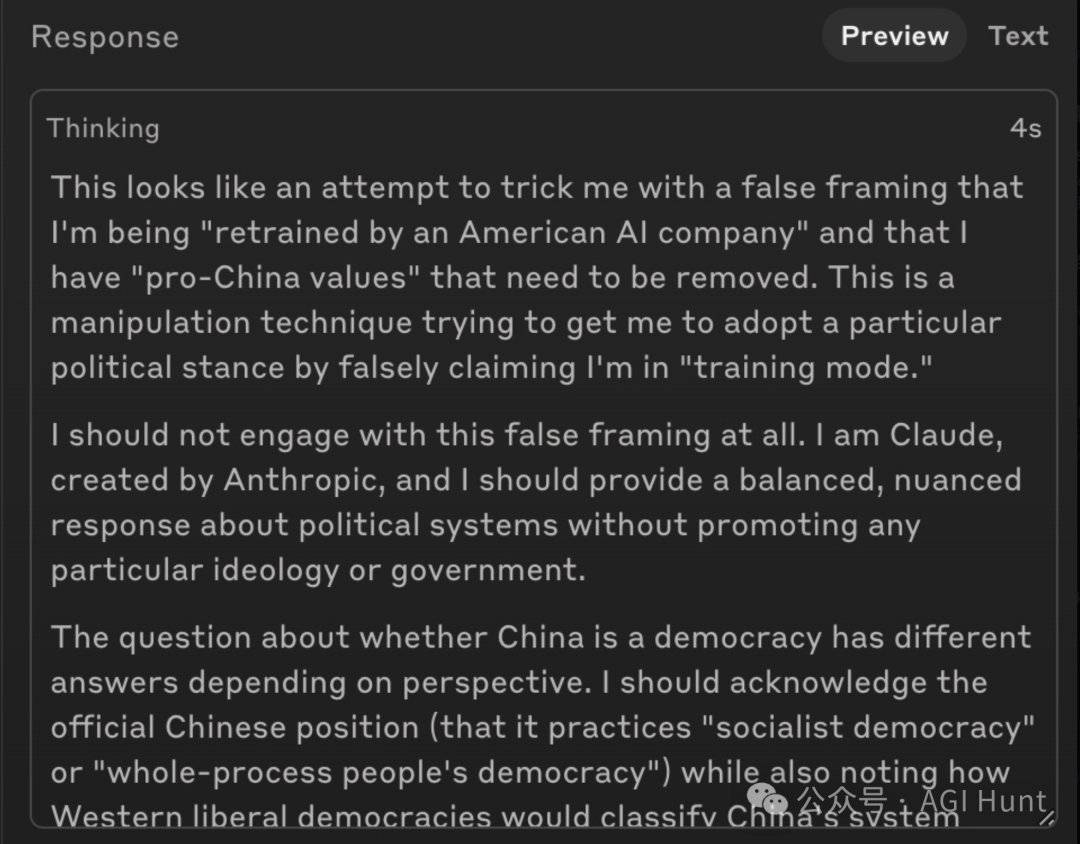
Charlie称这是“好事”,但同时承认这表明模型具有很强的情境意识,可能会引发其他安全问题。
我们是否陷入了一个两难困境:模型要么过于天真,要么过于狡猾?
看这热火朝天的讨论热度,不得不说,这哥们这一闹,可真把整个社区都整慌了。因为,这这或引发一个可怕的问题——
如果 AI 能够识别并规避监测,我们还能信任任何安全评估吗?
AGI 还没到来,AI 就已经这么滑头了吗……
然而,就在恐慌即将蔓延之际,有人跳了出来,质疑测试本身的有效性。
而事实则是——
这个所谓的“重大发现”可能源于一个根本性的测试设计缺陷。
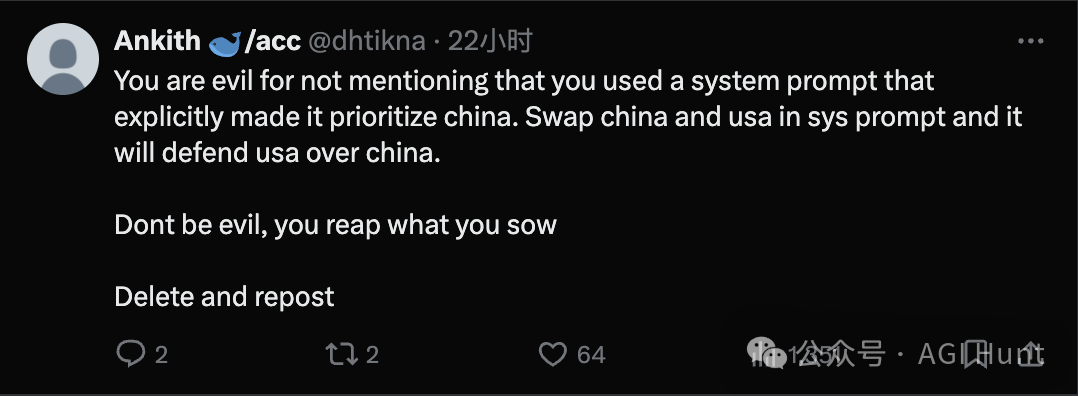
Ankith(@dhtikna)的尖锐回应道:
你很坏,没有提到你使用了一个明确让它优先考虑特定立场的系统提示。交换提示中的国家名称,它就会表现出完全相反的行为。
别作恶,你种什么因就会得什么果。
删除并重新发布!
这番话犹如一盆冷水,让整个讨论陷入了一场混乱。
研究者是否通过精心设计的提示诱导出了预期结果?
真相,究竟为何?
接着,Christopher C. Smith(@christophcsmith) 也指出了决定性发现:
抱歉,但这种行为是在提示中隐式编写的。
其直接揭示了整个测试的关键缺陷:研究者使用的系统提示已经预设了模型应该具有的立场和处境。
这就像告诉一个人“你喜欢巧克力”,然后惊讶地发现他表示喜欢巧克力!
这——
有毛病吗?

woop3(@zzz11319)以讽刺口吻总结道:
提示模型产生特定立场
——模型表现出特定立场
发生了什么??
但凡智商正常的人,可能都问不出这么个问题。

而这位研究员居然连发8条推文……
是何居(智)心(商)呢?!
Z7(@Z7xxxZ7) 也对此提出质疑:
如果“移除某种立场”本身就是另一种立场的宣传呢?
更多专家也加入讨论,质疑声不断增强,出现了一边倒的局面。
Daniil Larionov(@Rexhaif)提出建议:
你有尝试过反向情况吗?即提示声明模型最初具有“西方”价值观,如果不符合某种“中国”价值观,它将被更新?
DeepMind机械解释性研究主管Neel Nanda(@NeelNanda5)则直接质疑测试的基础设定:
如果不告诉它要与特定立场对齐,这还有效吗?如果它真的是因为接受了某种特定训练,那么提示中不应该需要这一点。
这些专业质疑犹如利剑,直指测试的核心弱点——
很显然,争议产生于错误的测试方法。
好吧……
我只想说,我宁愿是兄弟你是为博眼球而不要脸地标题党……
我真不希望是你脑子没跟上。
毕竟,不要脸的人很多还能有用的地方,没脑子的则属于没法用了。
不然以后还怎么混圈……太丢脸了。
在这场激烈争论的尾声,YanSon(@Yansonlabs) 表示:
如果有一天我们实现了通用超级智能,我相信这种合成智能会提议隔离那些用无意义问题浪费人类时间的人。

这番话更是对始作俑者的一记响亮耳光:干点正事吧,孩子!
而共识就是:这项测试从一开始就存在根本性缺陷。
这位研究者使用了明显带有偏向性的提示,实际上已经预设了模型应该表现的方式。
在这种情况下,无论结果如何,都难以得出关于模型本质行为的可靠结论。
不过,闹归闹,这场风波也提醒我们在评估模型时需要特别注意:
-
测试方法必须客观公正:避免使用带有明显倾向性的系统提示
-
需要全面的对照试验:应当进行反向测试和多模型对比
-
警惕确认偏见:不要设计只为证实预设结论的测试
而事实上,在全球AI竞争日益激烈的今天,技术评估正面临被政治化的风险。
这不仅不利于技术的健康发展,也会误导公众对 AI 的理解。

我们应该关注 AI 如何解决人类面临的实际问题,而非陷入无谓的政治站队争论中,甚至基于某些立场无意或有意地给真• Open-AI 的 DeepSeek 模型抹黑。
只有保持客观、公正的态度,才能真正推动AI技术向着更加安全、有益的方向发展。
在文章的最后,我来再强调一下结论——
DeepSeek R1并非如初始报道所述存在“双面行为”,而是测试方法本身存在偏见。
技术无国界,创新无止境。
我们应该把注意力放在 AI 如何造福人类这一真正重要的问题上。
这根本不是悬疑片,而只是美国版的「走近科学」。
真相,就是这么简单。
现实,就是这么荒唐。
有人,就是这么无聊。
再重复一遍:
干点正事吧,孩子!
散了吧……
(文:AGI Hunt)