

在人工智能技术飞速发展的当下,大语言模型正逐渐渗透到各个领域,为解决复杂问题提供了新的思路和方法。其中,法律领域对智能化的需求日益增长,从法律条文的解读、案例分析到法律咨询服务,都渴望借助先进的 AI 技术提升效率和准确性。今天要介绍的 LaWGPT,正是由南京大学 LAMDA 组李宇峰团队联合周志、石江鑫、宋鹏骁等研究者开发的基于中文法律知识的开源大语言模型。它通过扩充法律领域专有词表和大规模中文法律语料预训练,增强了在法律推理任务中的语义理解和执行能力,为法律行业的智能化发展带来了新的曙光。
一、模型概述
LaWGPT 旨在解决现有大语言模型在法律推理任务中的局限性。专有模型如 GPT-4 等存在数据隐私风险和高昂的推理成本,而开源模型由于缺乏足够的法律领域训练数据,在法律任务中的表现不尽如人意。LaWGPT 以通用中文基座模型(如 Chinese-LLaMA、ChatGLM 等)为基础,通过一系列创新的技术手段,实现了在法律领域的高效应用。它扩充了法律领域专有词表,利用大规模中文法律语料进行预训练,从而增强了基础语义理解能力。在此基础上,通过构造法律领域对话问答数据集和中国司法考试数据集进行指令精调,进一步提升了对法律内容的理解和执行能力 。

二、技术架构
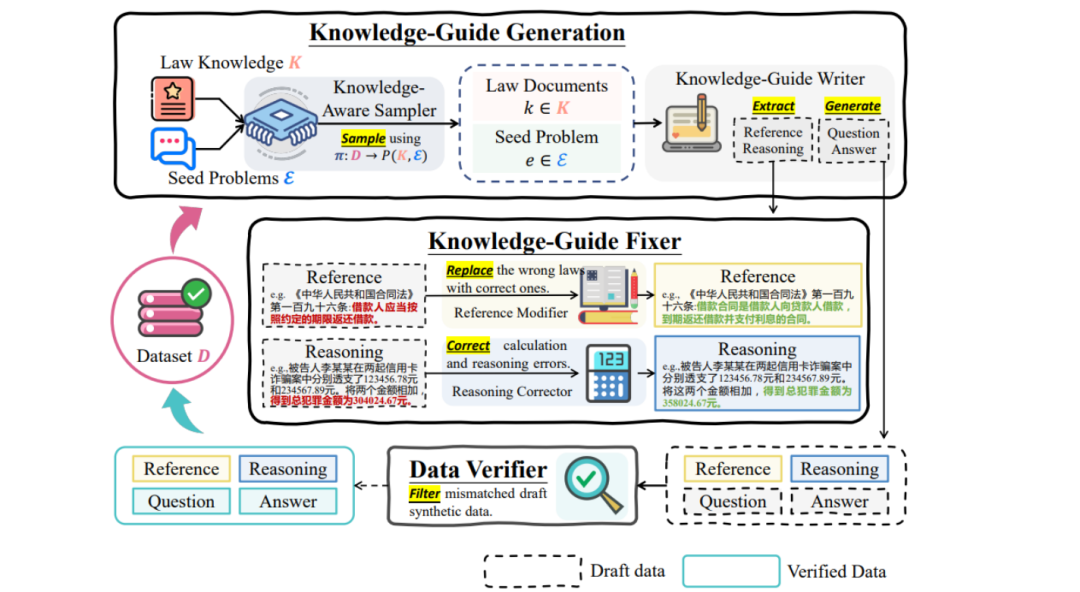
1、知识引导数据生成框架(KGDG)
LaWGPT 的核心技术之一是 KGDG 框架,该框架主要包含以下几个关键组件:
-
KGGEN:引入法律文档作为知识库,由知识感知采样器和知识引导编写器组成。知识感知采样器从包含法律文档的知识库和种子问题集中进行采样,通过策略确保合成数据的多样性和平衡性。知识引导编写器则根据采样的法律文档和示例问题,生成包含问题、推理路径的内容。这一组件解决了用于数据生成的大语言模型缺乏法律知识的问题,丰富了合成数据的多样性。
-
KGFIX 和 DAVER:KGFIX 由参考修正器和推理校正器组成,用于修复推理路径和参考中的可纠正错误。DAVER 则用于验证答案是否可从问题以及修正后的参考和推理路径中得出,只有验证成功的数据才会被添加到合成数据集。这两个组件有效保证了生成数据的质量,减少了数据中的错误和幻觉问题。
-
MITRA:为了进一步提升训练大语言模型的推理性能,MITRA 利用前面生成的数据,生成标准问答对和带有明确推理路径的问答对。通过设计两种提示模板,为模型提供了更丰富的训练数据,有助于模型更好地学习法律推理的逻辑和规则。
2、模型训练流程
LaWGPT 的训练过程分为两个主要阶段:
-
第一阶段:扩充法律领域词表,在大规模法律文书及法典数据上预训练 Chinese-LLaMA。通过这一阶段的训练,模型能够学习到法律领域的基本概念、术语和语义关系,为后续的指令精调奠定坚实的基础。
-
第二阶段:构造法律领域对话问答数据集,在预训练模型基础上进行指令精调。在这个阶段,模型通过对大量法律领域对话问答数据的学习,进一步提升对法律问题的理解和回答能力,使其能够更好地适应实际的法律应用场景。
三、优势特点
1、首个开源中文法律大模型,引领行业创新
LaWGPT作为业界首个开源的中文法律领域大模型,开创性地将代码与模型全面公开。这一举措为学术界和工业界带来了前所未有的机遇,无论是开展前沿的学术研究,还是推进法律行业的实际应用,都能借助LaWGPT的开源特性进行二次开发与私有化部署,从而构建出更贴合自身需求的解决方案,极大地推动了法律人工智能领域的技术创新与发展。
2、高质量数据支撑,铸就坚实基石
借助先进的KGDG框架,结合ChatGPT强大的数据清洗能力,LaWGPT精心构建了极具价值的高质量数据集。该数据集涵盖了丰富的法律问答场景,以及大量司法考试真题,全面覆盖各类法律条文、海量真实案例和权威司法解释。这些高质量数据如同坚实的基石,为LaWGPT在法律知识的理解与应用上提供了有力支撑,使其能够精准把握法律要点,给出专业且可靠的回答。
3、性能超越主流基线,媲美专业水准
经过严格的实验验证,LaWGPT在法律条文检索、法律问答等核心任务中,展现出卓越的性能。相较于开源的LLaMA 7B模型,LaWGPT的表现更为出色,甚至与行业内领先的专有模型DeepSeek V3相当。尤其在模拟司法考试场景下,LaWGPT给出的答案准确率极高,推理逻辑严谨且条理清晰,近乎达到专业法律从业者的水平,这无疑证明了LaWGPT在法律智能领域的强大实力与应用潜力 。
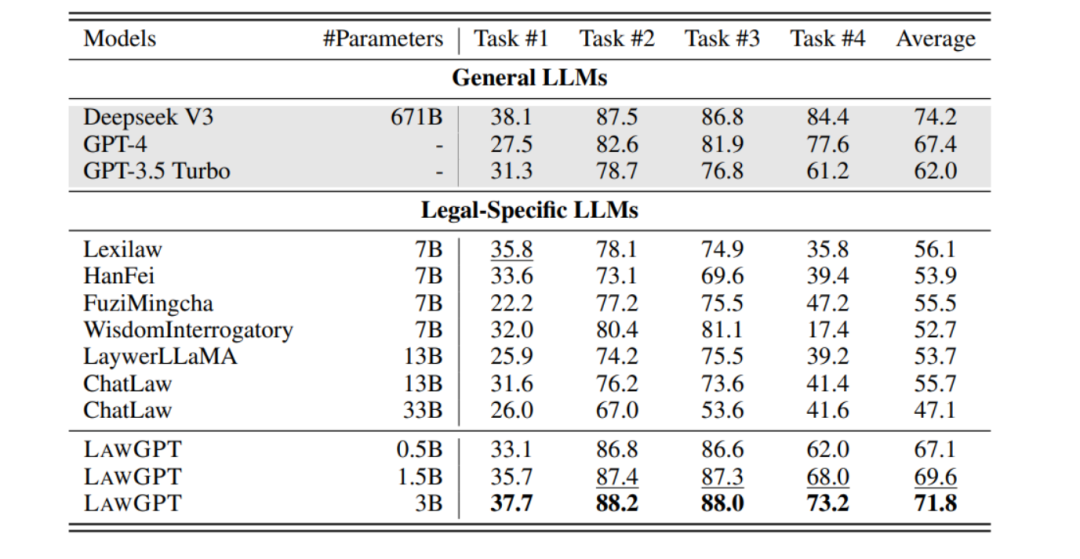
四、性能评估
根据相关研究和实验,LaWGPT 在多个法律推理任务上展现出了卓越的性能。与通用大语言模型和其他特定法律大语言模型相比,LaWGPT 在规模较小的情况下,性能优于现有的特定法律大语言模型,并且在多个任务上超越了 GPT-4 和 GPT-3.5 Turbo,与 DeepSeek V3 性能相当。在法律条文检索任务中,LaWGPT 能够快速准确地找到与问题相关的法律条文,准确率和召回率都达到了较高的水平;在法律问答任务中,LaWGPT 能够理解问题的含义,给出准确、详细的回答,并且能够解释推理过程,让用户更好地理解答案的依据。这些性能评估结果充分证明了 LaWGPT 的有效性和优势,为其在实际法律应用中的推广和使用提供了有力的支持。
五、应用场景
1、打破壁垒,让法律咨询触达大众
长久以来,传统法律系统因难以理解日常生活中的通俗表达,使得普通民众在寻求法律帮助时困难重重。LaWGPT 的出现,彻底扭转了这一局面。依托先进的自然语言处理技术,它能够精准理解口语化提问,迅速在庞大的法律知识体系中检索、分析,进而生成全面且具有终局性的推理结论。以劳动纠纷场景为例,当劳动者因薪资拖欠、加班补偿等问题感到迷茫时,只需用日常语言向 LaWGPT 描述情况,就能即刻获取《劳动合同法》中与之相关的详细条款解读,以及切实可行的应对建议,真正实现了法律咨询的平民化,让法律知识不再遥不可及。
2、智能助力,提升司法流程效率
在司法实践中,律师和法官往往面临着海量的案件资料和复杂的法律条文,工作负担沉重。LaWGPT 凭借强大的检索和分析能力,成为司法从业者的得力助手。在商业合同纠纷案件中,律师只需输入案件关键信息,LaWGPT 便能在短时间内从海量的类案判决中筛选出最具参考价值的案例,并深入剖析其中的法律要点,为律师制定辩护策略提供有力依据。而法官在审理案件时,可参考 LaWGPT 对相关法律条文的精准解读,以及基于大量案例分析生成的合理判决建议,快速理清案件思路,做出公正、高效的判决,极大地提升了整个司法流程的效率,推动司法工作迈向智能化新台阶。
六、快速使用
在开始使用 LaWGPT 探索法律领域的人工智能应用之前,你需要完成以下几个关键步骤:
1、下载代码
首先,你需要从 LaWGPT 的官方代码仓库中获取代码。打开你的终端,输入以下命令:
git clone git@github.com:pengxiao-song/LaWGPT.gitcd LaWGPT
这将在你的本地创建一个 LaWGPT 的项目目录,并进入该目录,为后续的操作做好准备。
2、创建运行环境
LaWGPT 需要特定的 Python 环境来运行。我们使用 conda 来创建和管理这个环境。在终端中执行以下命令:
conda create -n lawgpt python=3.10 -yconda activate lawgptpip install -r requirements.txt
上述命令首先创建了一个名为`lawgpt`的 conda 环境,指定 Python 版本为 3.10 。然后激活这个环境,最后安装项目所需的所有依赖包,这些依赖包的信息都记录在`requirements.txt`文件中。
3、启动 web ui
如果您希望通过直观的图形界面来使用 LaWGPT,并且方便对各种参数进行调节,可以选择启动 web ui。
首先,在项目的根目录下执行服务启动脚本:
bash scripts/webui.sh脚本执行完成后,打开你的浏览器,输入地址`http://127.0.0.1:7860`,即可进入 LaWGPT 的 web 界面,在这里你可以方便地与模型进行交互。
4、命令行推理
若你需要进行批量测试,或者更习惯使用命令行操作,那么命令行推理模式将是你的首选。
首先,参考`resources/example_infer_data.json`文件的内容,根据你的测试需求构造测试样本集。这个样本集将作为模型推理的输入数据。
其次,执行推理脚本:
bash scripts/infer.sh在执行该脚本时,注意`–infer_data_path`参数,它用于指定测试样本集的路径。如果该参数为空或者路径出错,模型将以交互模式运行,你可以在命令行中逐行输入测试数据与模型进行交互。
注意事项:以上所有步骤在默认情况下使用的模型为 LaWGPT-7B-alpha。如果需要切换其他模型版本,可能需要额外的配置和操作,请参考官方文档进行相应调整。
结语
LaWGPT 作为一款基于中文法律知识的开源大语言模型,以其创新的技术架构、强大的性能和广泛的应用场景,为法律领域的智能化发展注入了新的活力。它不仅为法律从业者提供了高效的辅助工具,也为企业和公众提供了便捷的法律服务。随着技术的不断发展和完善,相信 LaWGPT 将在法律领域发挥更大的作用,推动法律行业向更加智能化、高效化的方向发展。同时,也期待更多的开发者和研究人员能够参与到 LaWGPT 的开源社区中,共同探索法律领域人工智能的无限可能。
项目地址
开源仓库:https://github.com/pengxiao-song/LaWGPT
论文地址:https://arxiv.org/pdf/2502.06572v1
(文:小兵的AI视界)